Prometheus 介绍
承蒙大家厚爱,我的《Go语言之路》的纸质版图书已经上架京东,有需要的朋友请点击 此链接 购买。
prometheus 是目前主流的一个开源监控系统和告警工具包,它可以与 Kubernetes 等现代基础设施平台配合,轻松集成到云原生环境中,提供对容器化应用、微服务架构等的全面监控。本文将带你快速了解 Prometheus 相关概念。
简介
Prometheus 受启发于 Google 的 Brogmon 监控系统,从2012年开始由前Google工程师在 Soundcloud 以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。
2016年5月继 Kubernetes 之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。
2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
Prometheus 于2016年加入云计算基金会,成为继 Kubernetes 之后的第二个托管项目。
Prometheus 收集并存储其指标作为时间序列数据,即指标信息与其记录的时间戳一起存储,同时存储的还有可选的称为标签的键值对。
特性
Prometheus的主要特性有:
多维数据模型,包含由 metric 名称和键值对标识的时间序列数据
PromQL,一种可以灵活利用上述维度数据的查询语言
不依赖于分布式存储; 单个服务器节点是自治的
通过基于 HTTP 的拉模式(pull)进行时间序列数据收集
可以通过一个中间网关(Pushgateway)以推模式上报时间序列数据
通过服务发现或静态配置发现监控目标
支持多种模式的图表和仪表板
metric 是什么
通俗地说,metric 就是用数字来测量/度量。时间序列一词指的是记录一段时间内的变化。用户想要测量的内容会因应用而异。对于 Web 服务器,可以测量请求耗时;对于数据库,可以测量活动连接数或活动查询数等等。
Metrics 在理解应用程序以某种方式工作的原因方面发挥着重要作用。假设有一个 Web 应用程序正在运行,你发现它的运行速度很慢。这时候你需要一些信息来了解应用程序的运行情况。例如,当请求数量较多时,应用程序可能会变慢。如果掌握了请求数指标,就可以确定原因并增加服务器数量来处理负载。
组件
Prometheus 的生态系统由多个组成部分组成,其中许多是可选的:
- prometheus Server:用于抓取和存储时间序列数据
- client libraries:用于检测应用程序代码的客户端库
- push gateway:用于短时任务的推送接收器
- exporter:用于 HAProxy、StatsD、Graphite 等服务的专用输出程序
- altermanager:处理告警的警报管理器
- 各种支持工具
大多数 Prometheus 组件都是使用 Go 编写的,因此很容易构建和部署为静态二进制文件。
架构
这张图展示了 Prometheus 的架构及其生态系统的部分组件:
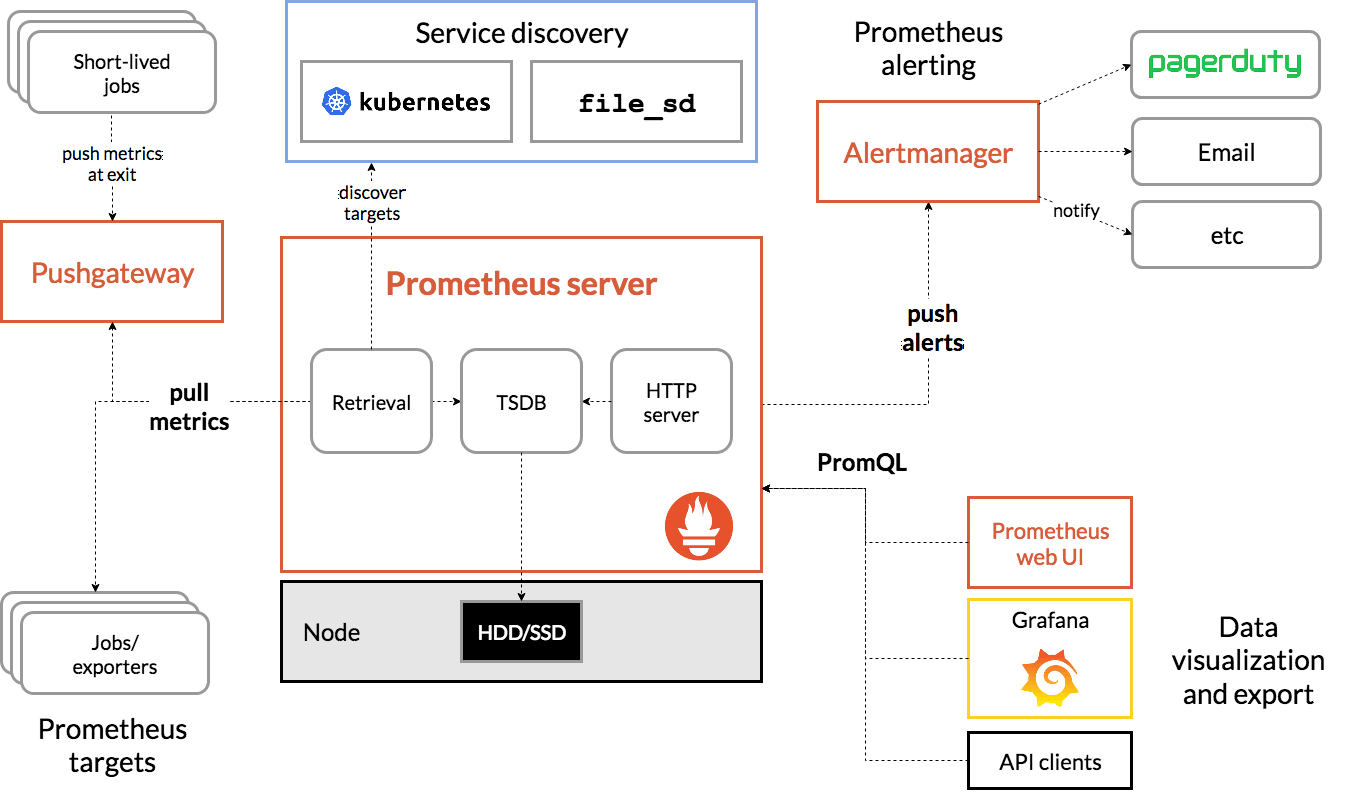
Prometheus 可直接或间接通过推送网关(Pushgateway)抓取监控指标(适用于短时任务)。
它在本地存储所有抓取到的样本数据,并在这些数据上执行一系列规则,以从现有数据中汇总并记录新的时间序列或生成告警。
可以使用 Grafana 或其他 API 消费者对收集到的数据进行可视化展示。
Prometheus 的优势
Prometheus 适用于记录文本格式的时间序列数据,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它天然支持对多维数据的收集和查询。Prometheus 是专为提高系统可靠性而设计的,它可以协助在故障期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
数据模型
Prometheus 将所有数据都存储为时间序列:属于同一指标(metric)和同一组标注维度(label)的带时间戳的值流。除了存储的时间序列外,Prometheus 还可以根据查询结果生成临时派生时间序列。
^
│ . . . . . . . . . . . . . . . . . . . go_gc_duration_seconds_count 12
│ . . . . . . . . . . . . . . . . . . . go_goroutines 32
│ . . . . . . . . . . . . . . . . . . go_info{version="go1.22.3"} 1
│ . . . . . . . . . . . . . . . . . .
v
<------------------ 时间 ---------------->
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标metric:metric name 和描述当前样本特征的 label sets
- 时间戳timestamp:一个精确到毫秒的时间戳
- 样本值value: 一个 float64 的浮点型数据表示当前样本的值
Metric name和 label
每个时间序列都由其指标名称和称为标签的可选键值对唯一标识。
Metric name
- 指定要测量的系统的一般功能(例如
http_requests_total-接收的http请求总数)。 - 指标名称可以包含ASCII字母、数字、下划线和冒号。它必须匹配正则表达式
[a-zA-Z_:][a-zA-Z0-9_:]*。
注意:冒号是为用户定义的录制规则保留的。exporter或直接仪器不应使用它们。
Metric labels
- 使 Prometheus 的维度数据模型能够识别同一指标名称的任何给定标签组合。它标识了该度量的特定维度实例化(例如:所有发送
POST到/api/tracks的HTTP请求)。Prometheus 查询语言允许基于这些维度进行筛选和聚合。 - 任何标签值的更改,包括添加或删除标签,都将创建一个新的时间序列。
- label 可以包含 ASCII 字母、数字以及下划线。必须匹配
[a-zA-Z_][a-zA-Z0-9_]*。 - 以
__(两个“下划线”)开头的标签名称保留供内部使用。 - 标签值可以包含任何 Unicode 字符。
- 标签值为空的标签被视为等同于不存在的标签。
更多内容请查看metric name和label的最佳实践。
Sample(采样/样本)
样本构成实际的时间序列数据。每个样本包括
- 一个 float64值
- 毫秒精度的时间戳
从 Prometheus v2.40 开始,实验性地支持原生直方图(histograms)。采样值不再是简单的 float64,而是一个完整的直方图。
Notation(表达式)
给定一个指标名称和一组标签,时间序列通常使用以下符号进行表示:
<metric name>{<label name>=<label value>, ...}
例如,指标名称为api_http_requests_total,带有method=“POST” 和handler="/messages"label 的时间序列可以这样写:
api_http_requests_total{method="POST", handler="/messages"}
这与OpenTSDB使用的表示方式相同。
Metric 类型
Prometheus 客户端库提供四种核心指标类型。这些类型目前仅在客户端库(以便根据特定类型的使用情况定制应用程序接口)和传输协议中有所区别。目前 prometheus 服务端还没有使用类型信息,而是将所有数据平铺为无类型的时间序列。未来的版本中可能会有所改变。
Counter(计数器)
Counter 是一种累积度量,表示单个单调递增的计数器(只增不减),其值只能在重新启动时增加或重置为零。例如,可以使用 counter 来表示已服务的请求数、已完成的任务数或错误数。
不要使用counter 记录可能减小的值。例如,不要使用counter记录当前正在运行的进程数,而是应该使用gauge 类型来记录。
Gauge(仪表盘)
Gauge 是一种度量标准,代表一个可以任意升降的单一数值。(可增可减)
Gauge 通常用于测量温度或当前内存使用量等值,但也用于上下变化的“计数”,如并发请求的数量。
Histogram(直方图)
histogram 对观测结果进行采样(通常是请求耗时或响应体大小) ,并按可配置的桶进行计数。它还提供了所有观察值的总和。
基本度量名称为<basename>的 histogram 会在抓取过程中暴露多个时间序列:
观察桶的累积计数器,对外展示为
<basename>_bucket{le="<upper inclusive bound>"}所有观测值的总和,对外展示为
<basename>_sum已观察到的事件数,对外展示为
<basename>_count(与上面的<basename>_bucket{le="+Inf"}相同)
使用histogram_quantile()函数可以根据 histogram 甚至 histogram 的聚合计算分位数。histogram 也适用于计算 Apdex 得分。在对bucket进行操作时,请记住 histogram 是累积的。
注意:从普罗米修斯v2.40开始,就有对原生直方图的实验支持。原生直方图只需要一个时间序列,除了观测值的总和和计数外,还包括动态数量的桶。原生直方图允许以很小的成本获得更高的分辨率。一旦本机直方图接近成为一个稳定的功能,详细的文档将随之而来。
Summary(摘要)
与 histogram 类似,summary对观察结果(通常是请求耗时和响应体大小)进行采样。虽然它还提供了观测的总计数和所有观测值的总和,但它在滑动时间窗口内计算可配置的分位数。
基本度量名称为<basename>的 summary 会在抓取过程中暴露多个时间序列:
- 观测事件的流式φ-quantiles(0 ≤ φ ≤ 1) 分位数,对外展示为
<basename>{quantile="<φ>"} - 所有观测值的总和,对外展示为
<basename>_sum - 已观察到的事件数,对外展示为
<basename>_count
关于 histogram 和 summary 的区别,可以简单概括为 histogram分桶记录数据,后续可在服务端使用表达式函数进行各种计算;而summary在客户端上报时就按配置上报计算好的φ-分位数。
- 如果需要多个实例的数据进行汇总,请选择
histogram。 - 除此以外,如果对将要观察的值的范围和分布有所了解,请选择
histogram。无论值的范围和分布如何,如果需要准确的分位数,请选择summary。
更多内容请查看HISTOGRAMS AND SUMMARIES。
job 和 instance
用 Prometheus 的术语来说,一个可以抓取的端点被称为一个instance,通常对应于一个进程。具有相同功能的实例集合(例如,为提高可扩展性/可靠性而创建的副本进程)称为 job。
例如,具有四个副本 instance 的api-server job:
- job:
api-server- instance 1:
1.2.3.4:5670 - instance 2:
1.2.3.4:5671 - instance 3:
5.6.7.8:5670 - instance 4:
5.6.7.8:5671
- instance 1:
当 Prometheus 抓取目标时,它会自动在抓取的时间序列上附加下面的标签,用于区分不同的目标:
job:目标所属的已配置作业名instance:被抓取的目标URL的<host>:<port>部分。
对于每一次抓取,prometheus 都会按照以下时间序列存储一个样本:
up{job="<job-name>", instance="<instance-id>"}:如果实例是健康的,即可访问的,就是1或者如果抓取失败,则为0。scrape_duration_seconds{job="<job-name>", instance="<instance-id>"}scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}scrape_series_added{job="<job-name>", instance="<instance-id>"}
快速开始
安装
Prometheus 支持预编译二进制文件安装、源码安装、docker等方式,由于我们是学习 prometheus 的基本使用,所以在本地使用 docker 快速开启一个实例。
docker run -d --name=prometheus -p 9090:9090 prom/prometheus
上面的命令将使用一个示例配置启动 Prometheus Server,启动完成后,可以通过 http://localhost:9090 访问Prometheus的UI界面。
如果你有自定义的prometheus.yml配置。
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
其中:
- global:全局配置
- alerting:Alertmanager 相关配置
- rule_files:规则相关配置,可以指定记录规则和告警规则。
- scrape_configs:采集配置
完整配置信息请查看官方文档:https://prometheus.io/docs/prometheus/latest/configuration/configuration/
使用以下命令挂载你的配置文件。
docker run \
-d \
--name=prometheus \
-p 9090:9090 \
-v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
Prometheus 数据存储在容器内的 /prometheus 目录中,因此每次重新启动容器时都会清除数据。要保存数据,需要为容器设置持久存储(或绑定挂载)。
运行具有持久存储的 prometheus 容器:
# Create persistent volume for your data
docker volume create prometheus-data
# Start Prometheus container
docker run \
-d \
--name=prometheus \
-p 9090:9090 \
-v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml \
-v prometheus-data:/prometheus \
prom/prometheus
采集指标
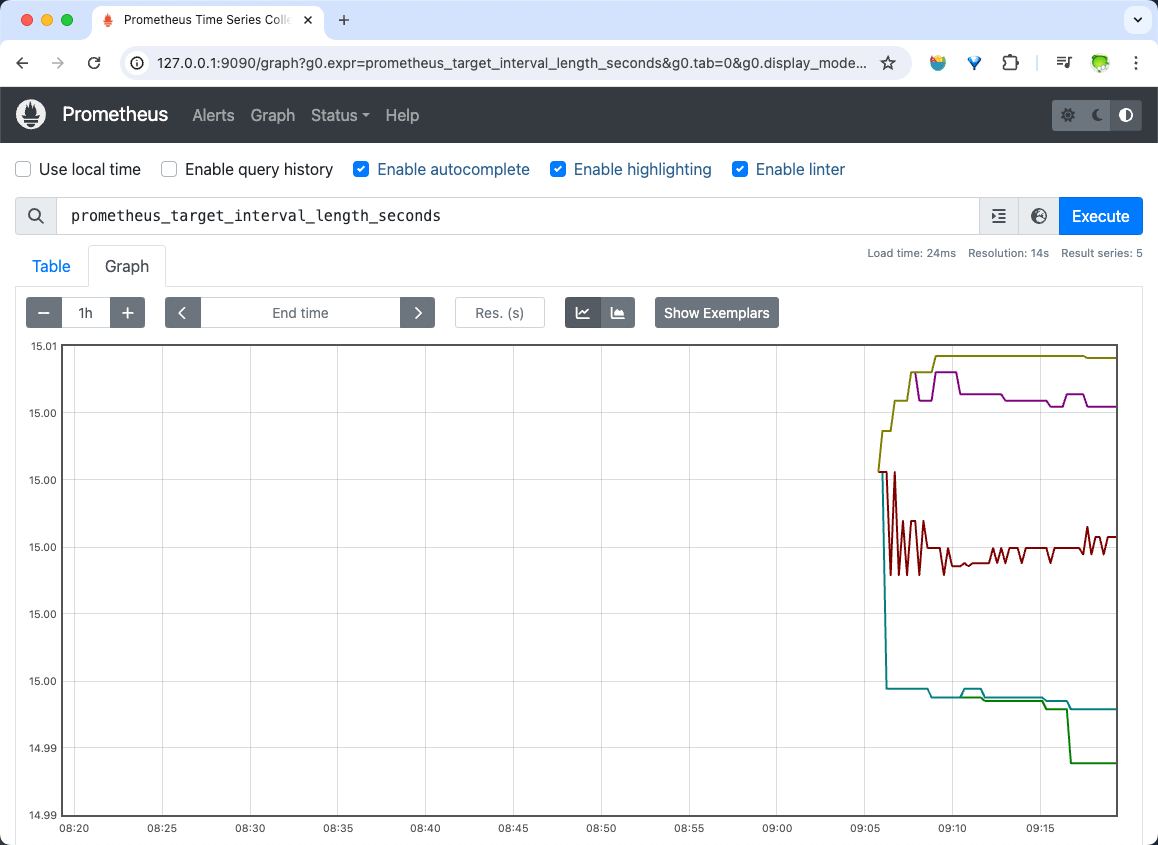
Prometheus 通过在目标节点的 HTTP 端口上采集 metric 数据来监控目标节点。因为 Prometheus 也以相同的方式暴露自己的指标数据,可以通过http://127.0.0.1:9090/metrics查看。
例如 Prometheus 暴露有一个表示从目标节点采集的时间间隔的 metric :
# HELP prometheus_target_interval_length_seconds Actual intervals between scrapes.
# TYPE prometheus_target_interval_length_seconds summary
prometheus_target_interval_length_seconds{interval="15s",quantile="0.01"} 14.99540459
prometheus_target_interval_length_seconds{interval="15s",quantile="0.05"} 14.995504465
prometheus_target_interval_length_seconds{interval="15s",quantile="0.5"} 14.999971298
prometheus_target_interval_length_seconds{interval="15s",quantile="0.9"} 15.00456159
prometheus_target_interval_length_seconds{interval="15s",quantile="0.99"} 15.005704466
prometheus_target_interval_length_seconds_sum{interval="15s"} 435.00580140700004
prometheus_target_interval_length_seconds_count{interval="15s"} 29
#号开头的是 metric 相关注释prometheus_target_interval_length_seconds开头的是相应的 metric 数据。
可视化
在 prometheus 提供的图形界面可以查看完整的指标数据。
grafana可视化
Grafana 是一款开源的数据可视化工具,支持多种数据源(如Graphite、InfluxDB、OpenTSDB、Prometheus、Elasticsearch等)并且具有快速灵活的客户端图表,提供了丰富的仪表盘插件和面板插件,支持多种展示方式,如折线图、柱状图、饼图、点状图等,满足用户不同的可视化需求。
安装 grafana
使用以下命令快速开启一个轻量级 grafana 容器环境。
docker run -d --name=grafana -p 3000:3000 grafana/grafana-oss
启动成功后,使用浏览器打开http://localhost:3000。默认的登录账号是 “admin” / “admin”。
配置 prometheus 数据源
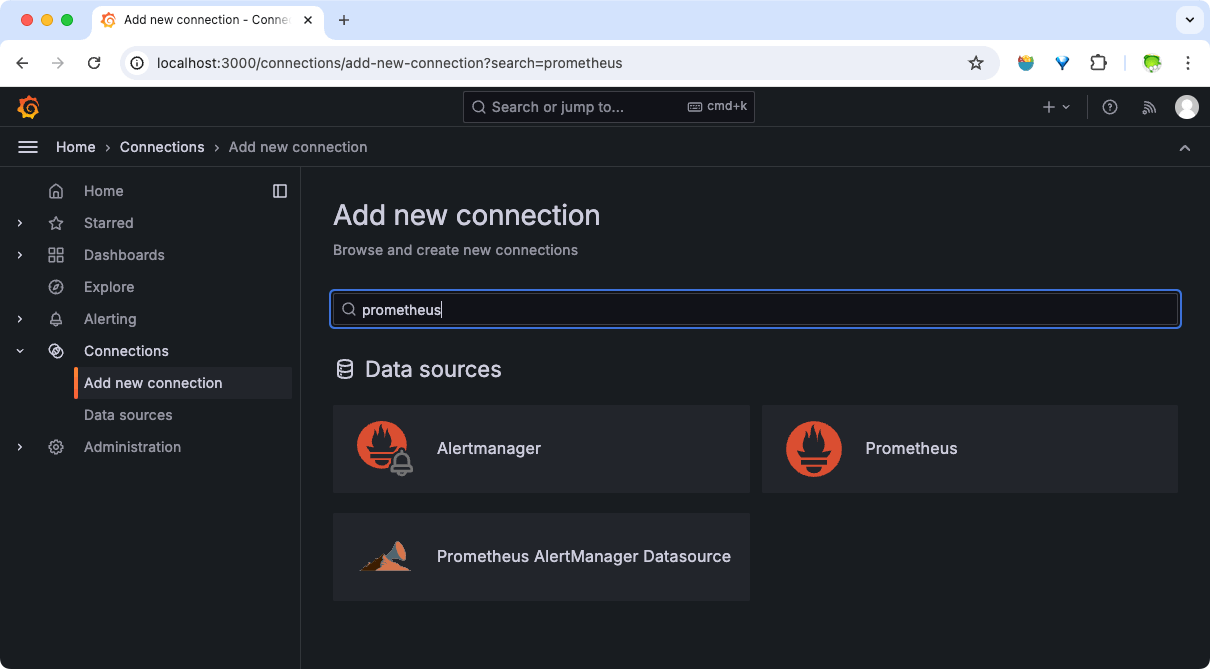
- 点击左侧菜单栏里的 『Connections』 图标。
- 在数据源列表里找到 『prometheus 图标』或者搜索框输入 “prometheus” 搜索。
- 点击 『prometheus 图标』,进入数据源页面。
- 点击页面右上角蓝色 『Add new data source』 按钮,添加数据源。
- 填写
Prometheus server URL(例如,http://localhost:9090/)。 - 根据需要调整其他数据源设置(例如, 认证或请求方法等)。
- 点击页面下方的 『Save & Test』保存并测试数据源连接。
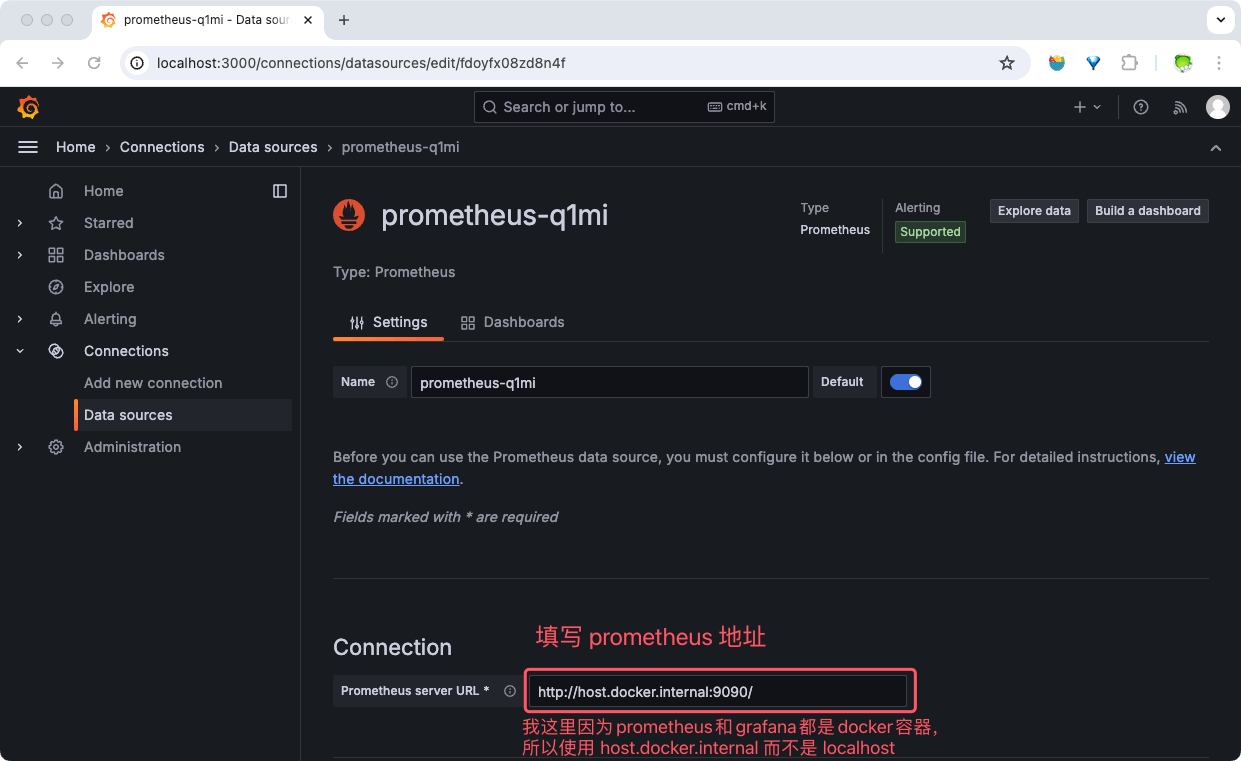
可以在这里配置完成后,点击旁边的『Dashboards』tab ,按模板导入仪表板配置。
也可以按下一节步骤手动添加仪表板。
添加仪表板
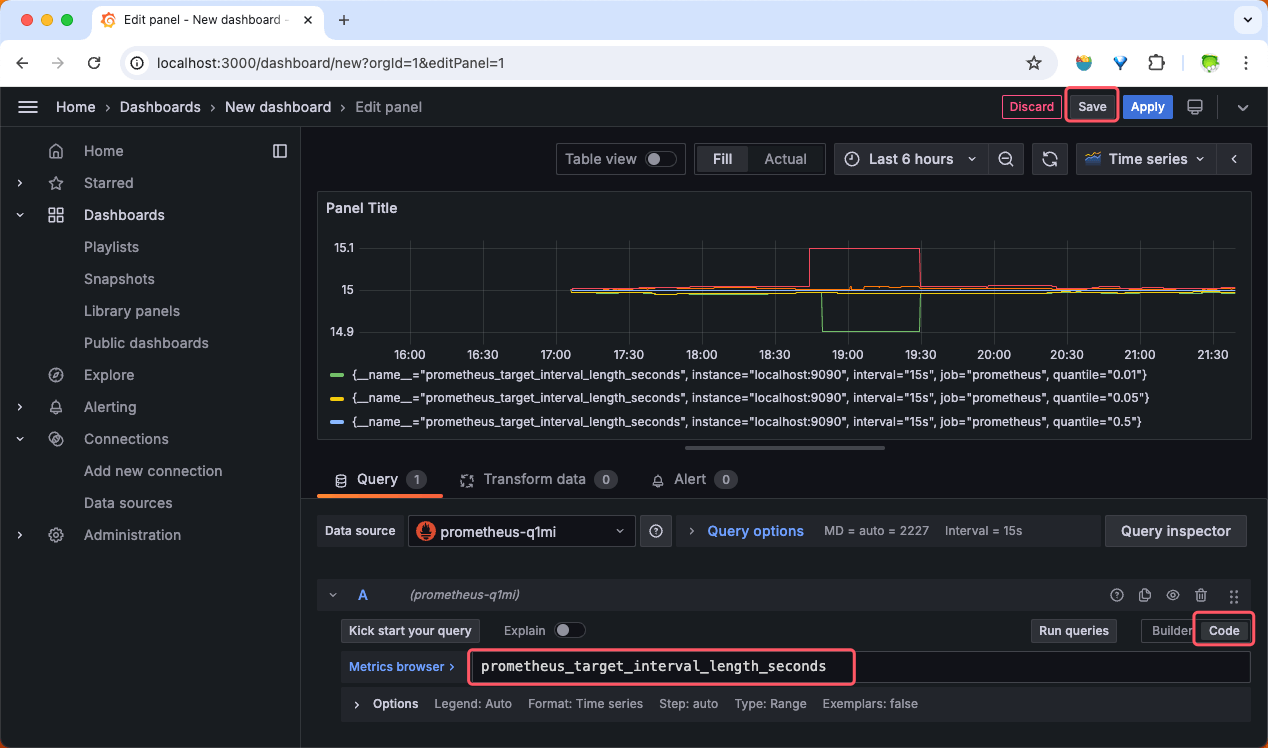
点击左侧菜单栏中的 『Dashboards』 。
点击页面中间的 『+ Create Dashboard』 按钮。
在打开的页面点击『+ Add visualization』按钮。
在打开的页面上选择上一节添加的 prometheus data source。
在打开的页面输入查询表达式
prometheus_target_interval_length_seconds,点击『Run queries』执行查询即可看到图表。点击右上角的『Save』保存仪表板。
Exporter 采集数据
在 Prometheus 的架构设计中,Prometheus Server 并不直接负责监控特定的目标,其主要任务负责数据的收集、存储以及对外提供数据查询支持。因此为了能够能够监控到某些指标,如主机的CPU使用率,我们需要使用到 Exporter。Prometheus 周期性的从 Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
广义上讲所有可以向 Prometheus 提供监控样本数据的程序都可以被称为一个 Exporter。而一个 Exporter 实例被称为 target,如下所示,Prometheus 通过轮询的方式定期从这些 target 中获取样本数据
Exporter 有两种运行方式:
- 独立运行(需使用独立运行的 Exporter 上报运行状态)
- 不能直接提供 HTTP 接口,如监控 Linux 系统状态指标。
- 项目发布时间较早,不支持 Prometheus 监控接口,如 MySQL、Redis;
- 集成到应用中(主动暴露运行状态给 Prometheus)
- 适用于需要较多自定义监控指标的项目。目前一些开源项目就增加了对 Prometheus 监控的原生支持,如 Kubernetes,ETCD 等。
- 可以在业务代码中增加自定义指标数据上报至 Prometheus 。
社区提供的 exporter
Prometheus 社区提供了丰富的 exporter 实现,涵盖了从基础设施、数据库、中间件等各个方面的监控功能。这些 exporter 可以实现大部分通用的监控需求。下表列举一些社区中常用的 exporter:
| 范围 | 常用Exporter |
|---|---|
| 数据库 | MySQL server exporter (official)、MSSQL server exporter、Elasticsearch exporter、MongoDB exporter、Redis exporter 等 |
| 硬件 | apcupsd exporter,Node/system metrics exporter (official),NVIDIA GPU exporter, Windows exporter等 |
| 问题跟踪和持续集成 | Jenkins exporter,JIRA exporter |
| 消息队列 | Kafka exporter, RabbitMQ exporter, RocketMQ exporter, NSQ exporter等 |
| 存储 | Ceph exporter, Hadoop HDFS FSImage exporter等 |
| HTTP服务 | Apache exporter, HAProxy exporter (official), Nginx metric library等 |
| API服务 | AWS ECS exporter,Azure Health exporter, Cloudflare exporter等 |
| 日志 | Fluentd exporter ,Grok exporter等 |
| 监控系统 | Alibaba Cloudmonitor exporter, AWS CloudWatch exporter (official), Azure Monitor exporter, JMX exporter (official), TencentCloud monitor exporter等 |
| 其它 | eBPF exporter,Kibana Exporter,SSH exporter,等 |
此外还有一些第三方软件默认就提供 Prometheus 格式的指标数据,因此不需要单独的 Exporter 。例如:
完整的第三方库支持可查看:exporters。
使用 prometheus client 库实现
想为自己的应用程序中添加 Prometheus 监控支持,就需要使用 Prometheus Client 库编写代码,并在应用程序实例上的 HTTP 端点定义和公开内部 metrics。Prometheus 官方提供的 Client 有:
当 Prometheus 抓取实例的 HTTP 端点时,客户端库将所有跟踪指标的当前状态发送到服务器。
Prometheus Go Client 示例
安装依赖:
go get github.com/gin-gonic/gin
go get github.com/prometheus/client_golang/prometheus
go get github.com/prometheus/client_golang/prometheus/promhttp
下面的代码在 gin 框架搭建的应用程序中引入了 Prometheus 支持。对外暴露了Go 编译信息、Go runtime 指标和自定义的接口业务状态码指标数据。
package main
import (
"github.com/gin-gonic/gin"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/collectors"
"github.com/prometheus/client_golang/prometheus/promhttp"
"math/rand"
"regexp"
"strconv"
)
// 自定义业务状态码 Counter 指标
var statusCounter = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "api_response_status_count",
},
[]string{"method", "path", "status"},
)
func initRegistry() *prometheus.Registry {
// 创建一个 registry
reg := prometheus.NewRegistry()
// 添加 Go 编译信息
reg.MustRegister(collectors.NewBuildInfoCollector())
// Go runtime metrics
reg.MustRegister(collectors.NewGoCollector(
collectors.WithGoCollectorRuntimeMetrics(
collectors.GoRuntimeMetricsRule{Matcher: regexp.MustCompile("/.*")},
),
))
// 注册自定义的业务指标
reg.MustRegister(statusCounter)
return reg
}
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
// mock 业务逻辑,异常情况下返回 status = 1
status := 0
if rand.Intn(10)%3 == 0 {
status = 1
}
// 记录
statusCounter.WithLabelValues(
c.Request.Method,
c.Request.URL.Path,
strconv.Itoa(status),
).Inc()
c.JSON(200, gin.H{
"status": status,
"message": "pong",
})
})
reg := initRegistry()
// 对外提供 /metrics 接口,支持 prometheus 采集
r.GET("/metrics", gin.WrapH(promhttp.HandlerFor(
reg,
promhttp.HandlerOpts{Registry: reg},
)))
r.Run(":8083")
}
参考资料






