分布式 ID ⽣成器
分布式 ID ⽣成器
分布式 ID 的特点
全局唯一性:不能出现有重复的 ID 标识,这是基本要求。
递增性:确保生成 ID 对于用户或业务是递增的。
高可用性:确保任何时候都能生成正确的 ID。
高性能:在高并发的环境下依然表现良好。
不仅仅是用于⽤户 ID,实际互联网中有很多场景都需要能够⽣成类似 MySQL ⾃增ID这样不断增大,同时又不会重复的 ID。以⽀持业务中的⾼并发场景。
⽐较典型的场景有:
- 电商促销时短时间内会有大量的订单涌⼊到系统,⽐如每秒 10w+;
- 明星出轨时微博短时间内会产⽣⼤量的相关微博转发和评论消息。
在这些业务场景下将数据插入数据库之前,我们需要给这些订单和消息先分配一个唯一ID,然后再保存到数据库中。对这个 ID 的要求是希望其中能带有⼀些时间信息,这样即使我们后端的系统对消息进行了分库分表,也能够以时间顺序对这些消息进行排序。
可能会问的问题
uid: 781261132115
Uid: 78943213101
req –> uid –> uid%100 –>
- userinfo_15
- userinfo_01
- 为什么不直接使用数据库主键 ID 做用户 ID ?
使用数据库自增 ID 作为用户 ID,无法满足超大用户量规模和分布式架构的需求。
分布式 ID 生成系统本身会是一个高度可靠、容错的分布式服务。
- 为什么不使用 UUID (Universally Unique Identifier) / GUID (Globally Unique Identifier)?
结构: 128位的值,通常表示为32个十六进制数字,以连字符分隔 (e.g.,
550e8400-e29b-41d4-a716-446655440000)。优点:
- 生成简单,几乎不可能冲突(概率极低)。
- 可以在客户端或应用服务器本地生成,无需中心协调。
缺点:
- 长度较长 (128位 vs 64位): 占用更多存储空间,索引效率相对较低。
- 无序性: 大部分版本的UUID是完全随机的,对数据库插入和某些查询性能不友好。
- 可读性差。
应用场景: 虽然对于核心用户 ID 可能不是首选(因为长度和无序性),但在某些不需要排序或对存储空间不那么敏感的场景下,或者需要去中心化生成 ID 时,UUID 仍然是一个可选方案。
snowflake算法介绍
雪花算法,它是 Twitter 开源的由 64 位整数组成分布式ID,性能较高,并且在单机上递增。
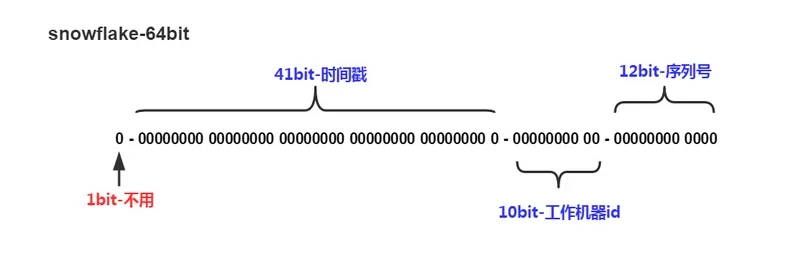
通常一个 64 位的 ID 会被划分为以下几个部分:
第一位 占⽤ 1 bit,其值始终是 0 ,没有实际作⽤用。
时间戳 占⽤ 41 bit,单位为毫秒,总共可以容纳约 69 年的时间。当然,我们的时间毫秒计数不会真的从 1970 年开始记,那样我们的系统跑到
2039/9/7 23:47:35就不能⽤了,所以这里的时间戳只是相对于某个时间的增量,⽐如我们的系统上线日期是2020-07-01,那么我们完全可以把这个 timestamp 当作是从2020-07-01 00:00:00.000的偏移量量。机器id 占用 10 bit,其中⾼位 5 bit 是数据中心ID,低位 5bit 是工作节点 ID,最多可以容纳 1024 个节点。
序列列号 占用 12 bit,⽤来记录同毫秒内产⽣的不同 ID。每个节点每毫秒 0 开始不断累加,最多可以累加到 4095 ,同⼀毫秒⼀共可以产生 4096 个ID。
SnowFlake算法在同一毫秒内最多可以生成多少个全局唯⼀ ID 呢?
同⼀毫秒的 ID 数量 = 1024 X 4096 = 4194304
snowflake的Go实现
1. bwmarrin/snowflake
github.com/bwmarrin/snowflake 是⼀个相当轻量化的 snowflake Go 实现。
产生的 64 位 ID结构如下所示:

安装依赖:
go get github.com/bwmarrin/snowflake使用示例:
package main
import (
"fmt"
"time"
"github.com/bwmarrin/snowflake"
)
func main() {
// 设置自定义的系统起始时间戳
startTime, _ := time.Parse(time.DateOnly, "2025-01-01")
snowflake.Epoch = startTime.UnixMilli()
// 创建 1 号节点,集群中不能使用重复的 node 序号
node, err := snowflake.NewNode(1)
if err != nil {
fmt.Println(err)
return
}
// 生成一个 snowflake ID.
id := node.Generate()
// 打印不同展示形式的 ID
fmt.Printf("Int64 ID: %d\n", id)
fmt.Printf("String ID: %s\n", id)
fmt.Printf("Base2 ID: %s\n", id.Base2())
fmt.Printf("Base64 ID: %s\n", id.Base64())
}2. sonyflake
sonyflake 是 Sony 公司的⼀个开源项目,基本思路和 snowflake 差不多,不过位分配上稍有不同:

这个库生成的 ID 中时间戳只用了 39 个bit,但时间的单位变成了10ms,所以理论上比 41 位表示的时间还要久(174年)。
Sequence ID 和之前的定义一致, Machine ID 其实就是 Node ID。
安装依赖:
go get github.com/sony/sonyflake/v2sonyflake 库有以下配置参数:
type Settings struct {
BitsSequence int
BitsMachineID int
TimeUnit time.Duration
StartTime time.Time
MachineID func() (int, error)
CheckMachineID func(int) bool
}其中:
StartTime 选项和我们之前的 Epoch差不多,如果不设置的话,默认是从 2014-09-01 00:00:00 +0000 UTC开始。
MachineID 可以由⽤户⾃定义的函数,如果⽤户不定义的话,会默认将本机 IP 的低16位作为 machine id。
CheckMachineID 是由用户提供的检查 MachineID 是否冲突的函数。
使用示例:
package main
import (
"fmt"
"github.com/sony/sonyflake/v2"
"time"
)
func main() {
st, _ := time.Parse(time.DateOnly, "2025-01-01")
settings := sonyflake.Settings{
StartTime: st,
}
sonyFlake, err := sonyflake.New(settings)
if err != nil {
panic(err)
}
id, err := sonyFlake.NextID()
fmt.Printf("id:%v err:%v\n", id, err)
}