评价/评论系统项目实战
这个项目是一个相对比较通用的微服务项目,在公司内部通常作为中台服务,独立开发、独立部署。在公司内部通过RPC方式与业务方对接。
通过这个项目,带领大家了解大厂真实项目的架构设计方案,锻炼大家的系统分析和系统设计能力,同时帮助大家掌握企业常用中间件的使用。
项目介绍
目前市面上有比较多业务场景需要用到评价/评论系统,不同业务形态下对评价/评论系统的要求不尽相同。
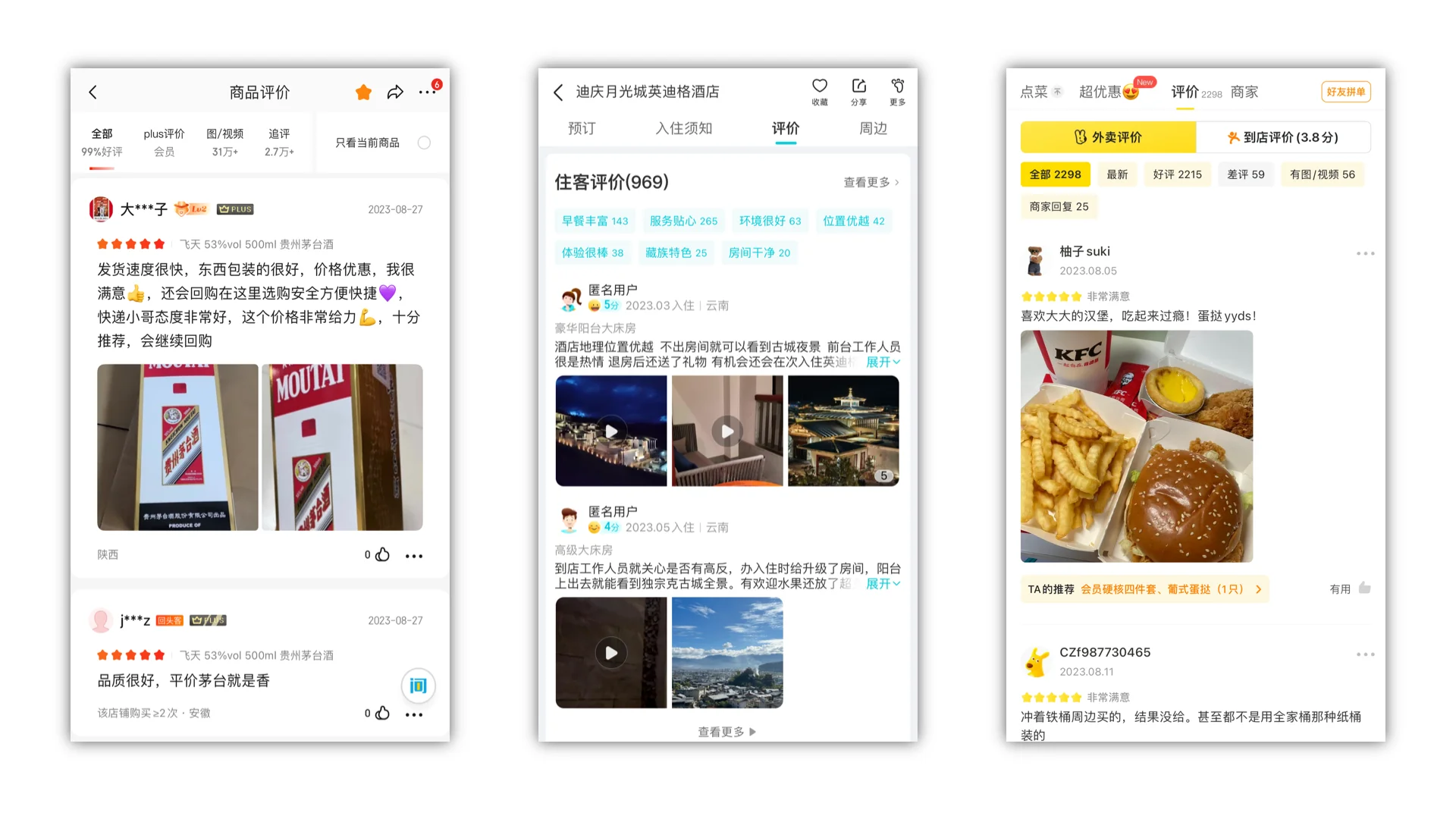
电商类评价系统
电商类网站/APP搭建用户评价系统,在用户购买后会收集用户评价,可以提高消费者的购买决策,提升商家的服务和产品质量,增加用户参与度和忠诚度,提高电商平台的口碑和知名度,同时也能加强商家之间的竞争。
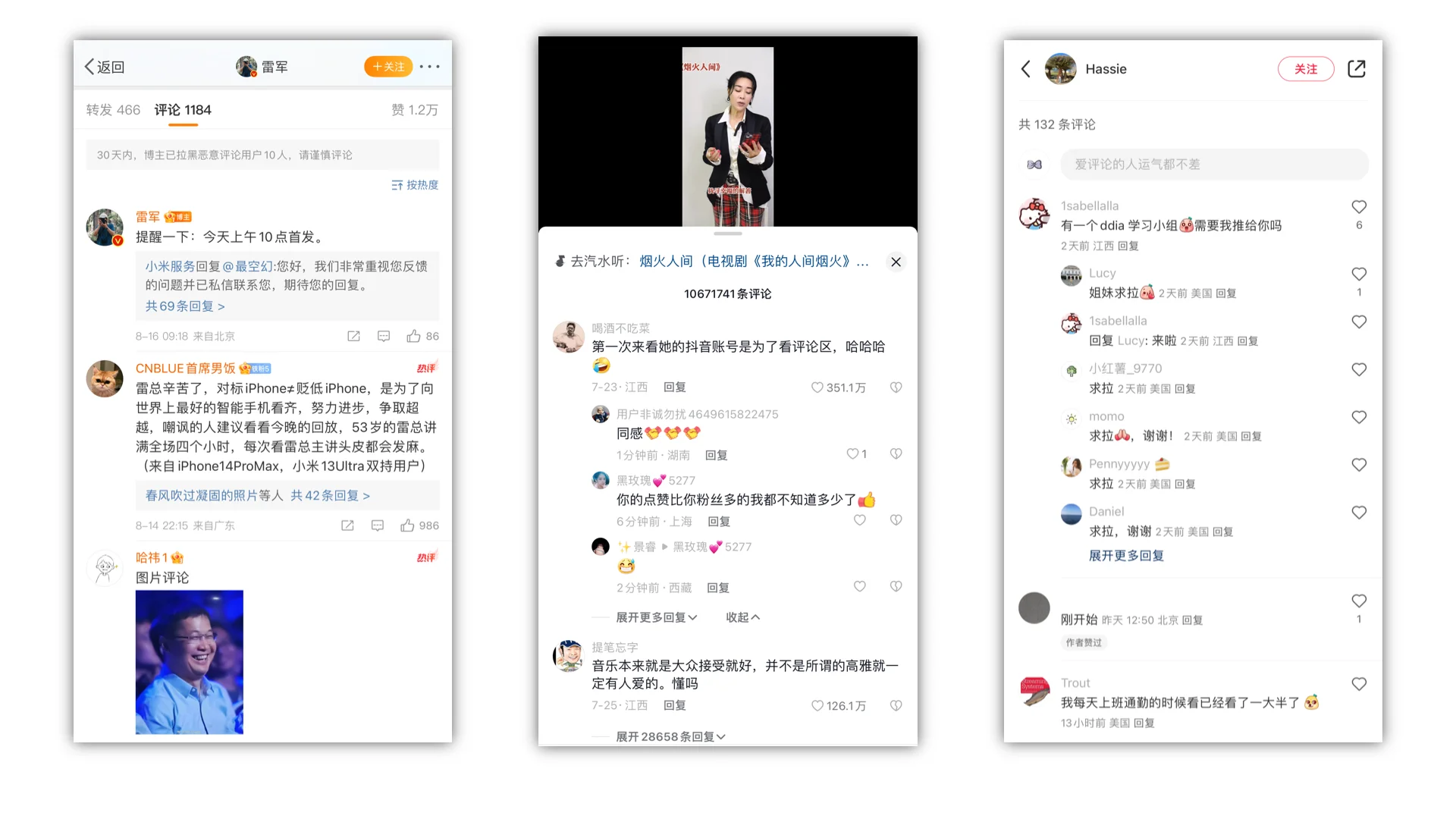
UGC 社区评论系统
UGC(User Generated Content)社区支持用户评论可以带来增加用户参与度和互动性、增加用户黏性和留存率、增加社区的内容丰富度、提升用户体验以及加强社区社交属性等多重好处。
两种业务形态的异同
相同点
从产品角度看都是为了增加用户参与度和忠诚度。
从技术角度看底层逻辑一致,都是支持用户对某一对象发布关联信息。
区别
从产品角度看:
电商类评价系统主要是为了对购买的商品进行评价,以便其他用户参考和选择,属于购物流程的一部分,会多一些与电商业务相关的内容,例如标签、关联SPU/SKU等。
UGC社区的评论系统拥有更多的社交属性,更注重用户的互动和参与度。
从技术角度看:
- 电商类评价系统主要侧重对商品的描述、质量、价格等方面的评价,需要有关联的SKU/SPU和订单等信息,数据方面更强调标签化,好评数、中评数、差评数等。
- UGC区的评论可以包含更多维度的信息,不仅有文字还可以添加图片、视频等多媒体信息,评论数据则以数量、点赞数、回复数等形式进行统计,更注重用户的互动和参与度。
当然无论是电商还是UGC社区,对于评价/评论系统,每个公司根据自身业务形态的不同,实际上都会有些区别。(不会有完全相同的两个业务产品。)
就以电商场景的发表评价为例,B2C和O2O的可能就不一样,抖音商城不同类型订单的评价页面。
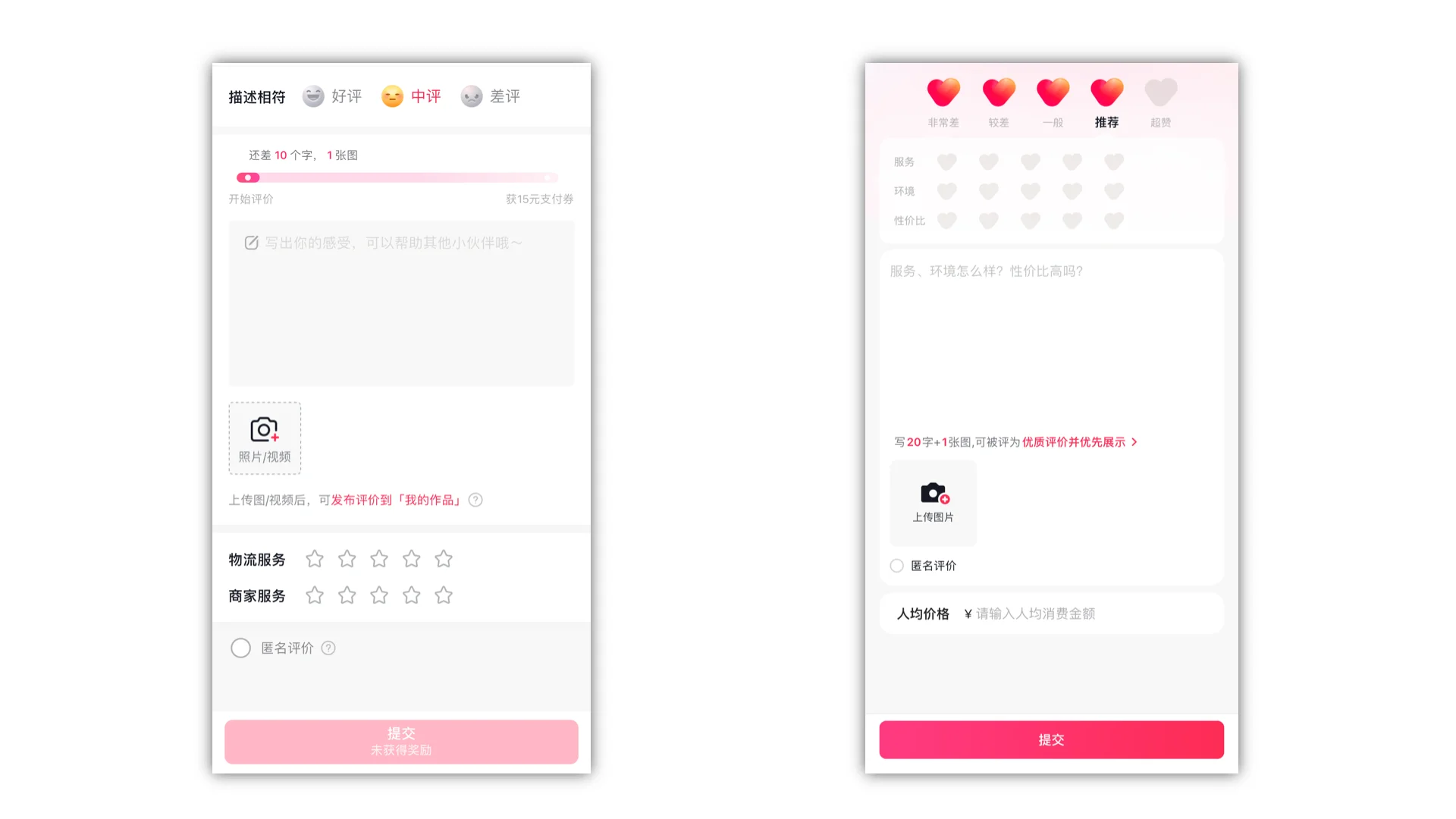
项目背景
站在开发者角度,从电商类评价系统和UGC社区评论系统两者中总结出共性,设计出一套具有普适性的技术方案。以实现一套电商评价服务为主。
项目设计
系统分析
输入输出
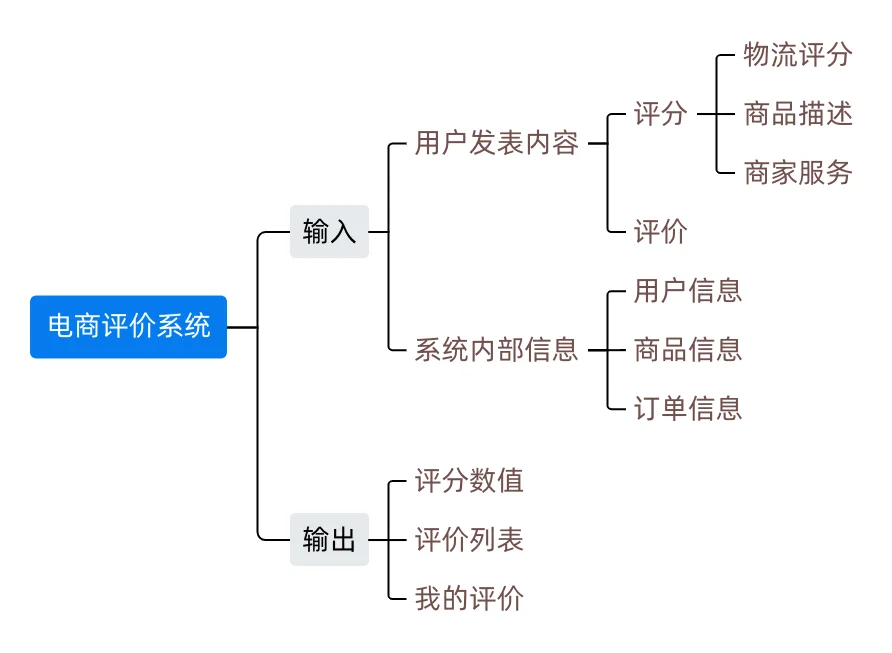
功能模块
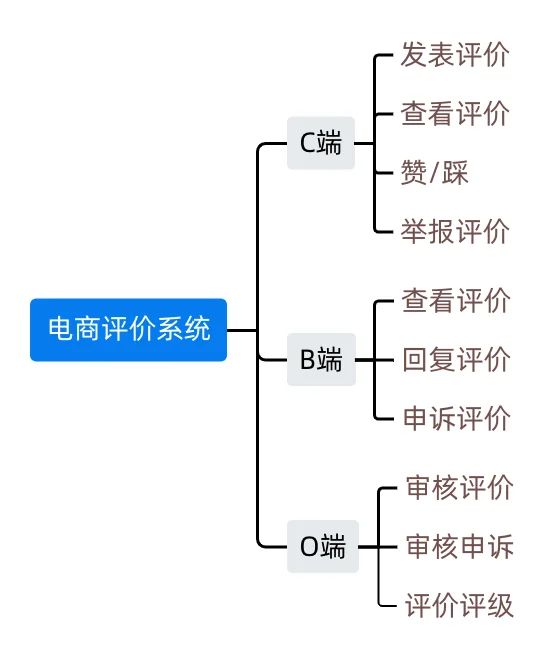
C端:用户端,包括发评用户和看评用户。
B端:商家端,店铺商家端,店铺管理者,商品发布者。
O端:运营端,运营同学在运营后台负责审核用户评价,处理商家申诉,以及基于评价进行运营活动。
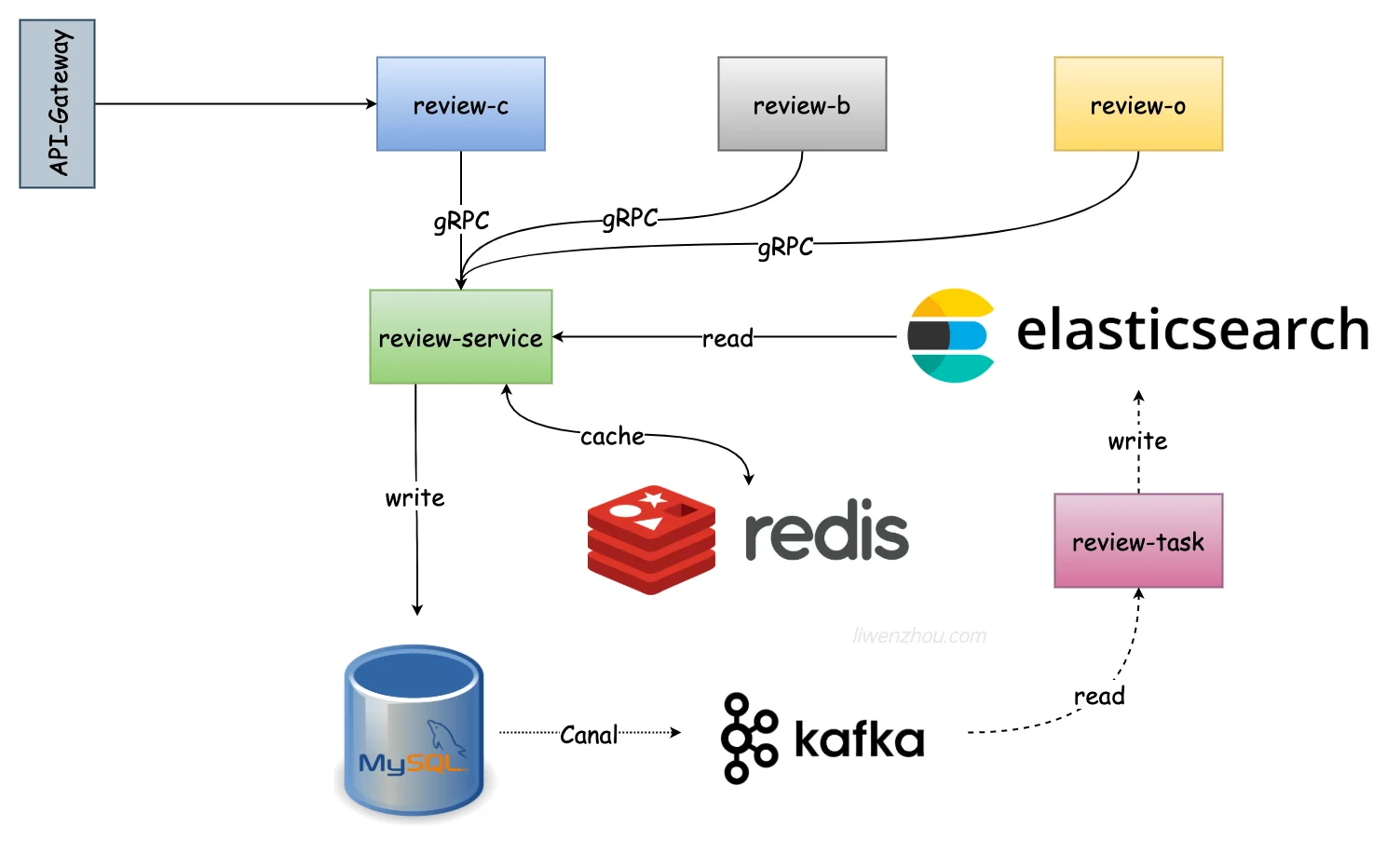
总体架构设计
顺着数据流动的方向去思考。
电商评价系统架构
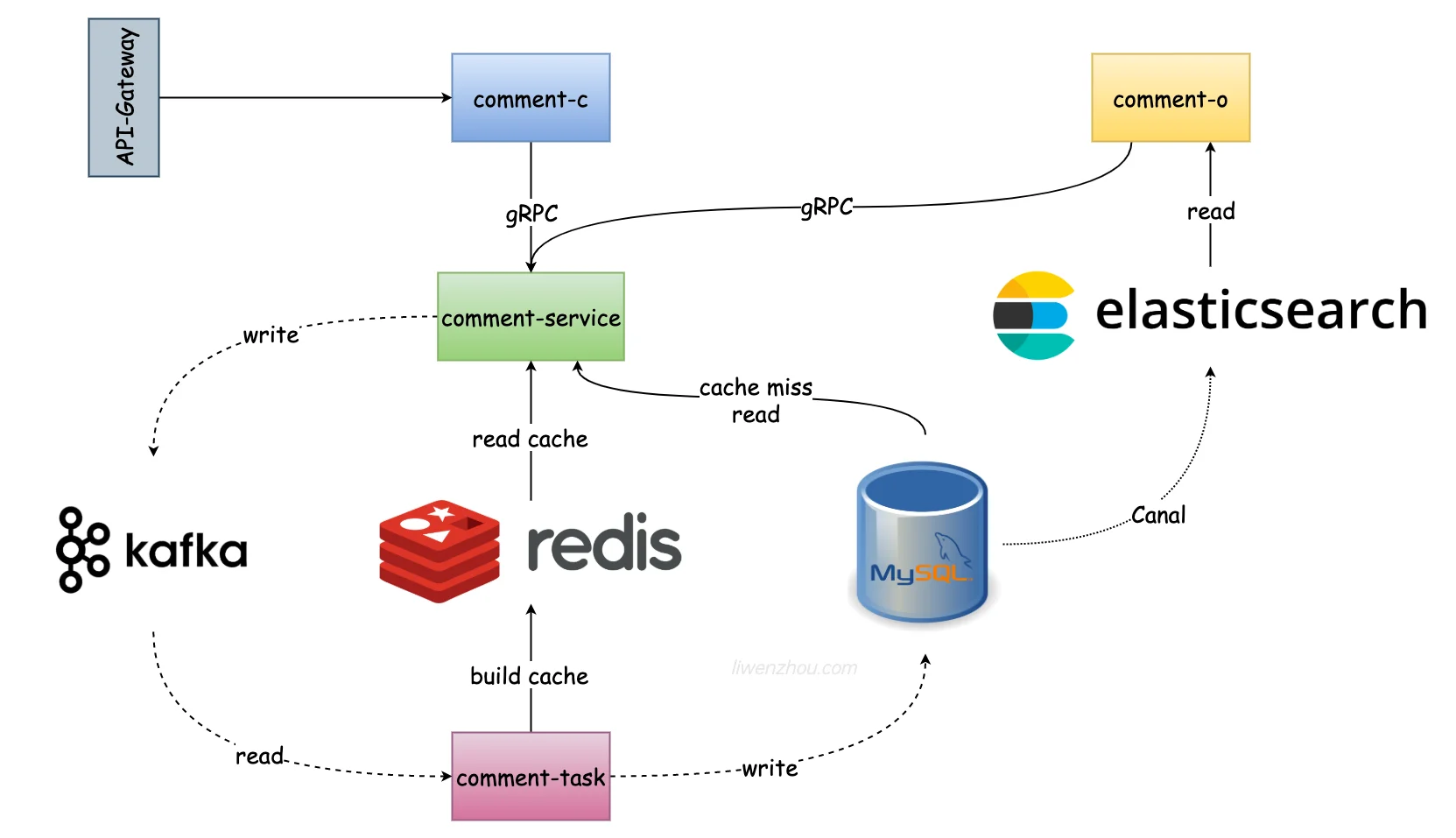
UGC社区评论系统架构
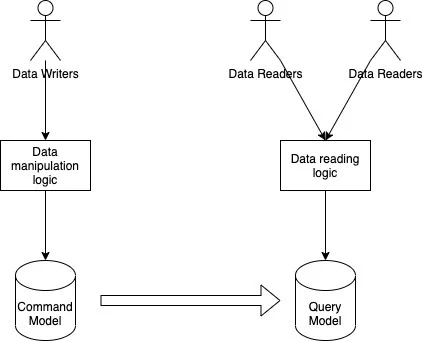
CQRS架构(扩展知识点)
扩展 - CQRS架构模式
CQRS 是“命令查询职责分离”(Command Query Responsibility Segregation)的缩写。在基于 CQRS 的系统中,命令(写操作)和查询(读操作)所使用的数据模型是有区别的。命令模型用于有效地执行写/更新操作,而查询模型用于有效地支持各种读模式。通过领域事件或其他各种机制将命令模型中的变更传播到查询模型中,让两个模型之间的数据保持同步。
推荐阅读
表结构
想清楚当前这个业务都需要哪些表,每个表都需要有哪些字段。
每个公司应该都会有类似 数据表设计规约 这类内部规定或要求。
参考资料:alibaba MySQL 规约
评价表
用户在订单到达指定状态后可以对订单发表评价。
CREATE TABLE review_info (
`id` bigint(32) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`create_by` varchar(48) NOT NULL DEFAULT '' COMMENT '创建方标识',
`update_by` varchar(48) NOT NULL DEFAULT '' COMMENT '更新方标识',
`create_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`delete_at` timestamp COMMENT '逻辑删除标记',
`version` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '乐观锁标记',
`review_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '评价id',
`content` varchar(512) NOT NULL COMMENT '评价内容',
`score` tinyint(4) NOT NULL DEFAULT '0' COMMENT '评分',
`service_score` tinyint(4) NOT NULL DEFAULT '0' COMMENT '商家服务评分',
`express_score` tinyint(4) NOT NULL DEFAULT '0' COMMENT '物流评分',
`has_media` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否有图或视频',
`order_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '订单id',
`sku_id` bigint(32) NOT NULL DEFAULT '0' COMMENT 'sku id',
`spu_id` bigint(32) NOT NULL DEFAULT '0' COMMENT 'spu id',
`store_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '店铺id',
`user_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '用户id',
`anonymous` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否匿名',
`tags` varchar(1024) NOT NULL DEFAULT '' COMMENT '标签json',
`pic_info` varchar(1024) NOT NULL DEFAULT '' COMMENT '媒体信息:图片',
`video_info` varchar(1024) NOT NULL DEFAULT '' COMMENT '媒体信息:视频',
`status` tinyint(4) NOT NULL DEFAULT '10' COMMENT '状态:10待审核;20审核通过;30审核不通过;40隐藏',
`is_default` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否默认评价',
`has_reply` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否有商家回复:0无;1有',
`op_reason` varchar(512) NOT NULL DEFAULT '' COMMENT '运营审核拒绝原因',
`op_remarks` varchar(512) NOT NULL DEFAULT '' COMMENT '运营备注',
`op_user` varchar(64) NOT NULL DEFAULT '' COMMENT '运营者标识',
`goods_snapshoot` varchar(2048) NOT NULL DEFAULT '' COMMENT '商品快照信息',
`ext_json` varchar(1024) NOT NULL DEFAULT '' COMMENT '信息扩展',
`ctrl_json` varchar(1024) NOT NULL DEFAULT '' COMMENT '控制扩展',
PRIMARY KEY (`id`),
KEY `idx_delete_at` (`delete_at`) COMMENT '逻辑删除索引',
UNIQUE KEY `uk_review_id` (`review_id`) COMMENT '评价id索引',
KEY `idx_order_id` (`order_id`) COMMENT '订单id索引',
KEY `idx_user_id` (`user_id`) COMMENT '用户id索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='评价表';评价回复表
保存商家后台对用户发表评价的回复。
CREATE TABLE review_reply_info (
`id` bigint(32) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`create_by` varchar(48) NOT NULL DEFAULT '' COMMENT '创建方标识',
`update_by` varchar(48) NOT NULL DEFAULT '' COMMENT '更新方标识',
`create_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`delete_at` timestamp COMMENT '逻辑删除标记',
`version` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '乐观锁标记',
`reply_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '回复id',
`review_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '评价id',
`store_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '店铺id',
`content` varchar(512) NOT NULL COMMENT '评价内容',
`pic_info` varchar(1024) NOT NULL DEFAULT '' COMMENT '媒体信息:图片',
`video_info` varchar(1024) NOT NULL DEFAULT '' COMMENT '媒体信息:视频',
`ext_json` varchar(1024) NOT NULL DEFAULT '' COMMENT '信息扩展',
`ctrl_json` varchar(1024) NOT NULL DEFAULT '' COMMENT '控制扩展',
PRIMARY KEY (`id`),
KEY `idx_delete_at` (`delete_at`) COMMENT '逻辑删除索引',
UNIQUE KEY `uk_reply_id` (`reply_id`) COMMENT '回复id索引',
KEY `idx_review_id` (`review_id`) COMMENT '评价id索引',
KEY `idx_store_id` (`store_id`) COMMENT '店铺id索引'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='评价商家回复表';评价申诉表
商家可对用户提交的评价进行申诉,比如用户提交的评价中出现其他品牌广告或要挟商家等恶意评价内容。
CREATE TABLE review_appeal_info (
`id` bigint(32) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`create_by` varchar(48) NOT NULL DEFAULT '' COMMENT '创建方标识',
`update_by` varchar(48) NOT NULL DEFAULT '' COMMENT '更新方标识',
`create_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`delete_at` timestamp COMMENT '逻辑删除标记',
`version` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '乐观锁标记',
`appeal_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '回复id',
`review_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '评价id',
`store_id` bigint(32) NOT NULL DEFAULT '0' COMMENT '店铺id',
`status` tinyint(4) NOT NULL DEFAULT '10' COMMENT '状态:10待审核;20申诉通过;30申诉驳回',
`reason` varchar(255) NOT NULL COMMENT '申诉原因类别',
`content` varchar(255) NOT NULL COMMENT '申诉内容描述',
`pic_info` varchar(1024) NOT NULL DEFAULT '' COMMENT '媒体信息:图片',
`video_info` varchar(1024) NOT NULL DEFAULT '' COMMENT '媒体信息:视频',
`op_remarks` varchar(512) NOT NULL DEFAULT '' COMMENT '运营备注',
`op_user` varchar(64) NOT NULL DEFAULT '' COMMENT '运营者标识',
`ext_json` varchar(1024) NOT NULL DEFAULT '' COMMENT '信息扩展',
`ctrl_json` varchar(1024) NOT NULL DEFAULT '' COMMENT '控制扩展',
PRIMARY KEY (`id`),
KEY `idx_delete_at` (`delete_at`) COMMENT '逻辑删除索引',
KEY `idx_appeal_id` (`appeal_id`) COMMENT '申诉id索引',
UNIQUE KEY `uk_review_id` (`review_id`) COMMENT '评价id索引',
KEY `idx_store_id` (`store_id`) COMMENT '店铺id索引'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='评价商家申诉表';数据库分表技巧
为了防止单表数据流量过大,需要根据实际的业务规模和情况做拆表。
垂直拆分:将不常用字段或占用空间较大的字段拆分出去,例如,关键的摘要数据与大篇幅内容分表存储等。
水平拆分:按数据表中的某个字段维度进行拆分,例如,电商场景下按用户或店铺维度进行分表。
具体按什么分表也是根据业务场景来决定的。
例如:购物车一般按用户分表,商品信息按商家分表。想一想,为什么?
将购物车水平拆分成100张表,cart_info_00~cart_info_99 , user_id:176003, 176003%100=3 => cart_info_03
允许部分冗余
当然也允许部分表的部分字段有冗余,前提是可以通过冗余减少查询次数或查询时间(本质上也算是一种空间换时间)。
补充 软删除相关
GORM的软删除:https://gorm.io/zh_CN/docs/delete.html#%E8%BD%AF%E5%88%A0%E9%99%A4
is_deltinyint(3) unsigned NOT NULL DEFAULT ‘0’ COMMENT ‘逻辑删除标记:0正常;1删除’,
delete_attimestamp COMMENT ‘逻辑删除标记’,
模块及实现
管理项目代码的方式(扩展知识)
扩展 - 如何管理项目代码?
- meno-repo(monolithic repository)
- multi-repo+submodule
项目框架搭建
先升级下自己本地的kratos
kratos upgrade课程中使用的kratos版本
❯ kratos -v
kratos version v2.7.0创建项目:
kratos new review-service进入项目目录下。
cd review-service添加proto:
kratos proto add api/review/v1/review.proto根据需要修改api/review/v1/review.proto文件。
生成代码:
1、生成客户端代码
kratos proto client api/review/v1/review.proto2、生成服务端代码
kratos proto server api/review/v1/review.proto -t internal/service接下来要在internal下面进行开发,顺着请求流程开始写(service->biz->data)。
项目依赖准备
0、准备MySQL环境
docker run --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root1234 -d mysql准备Redis环境
docker run --name redis507 -p 6379:6379 -d redis:5.0.71、数据库建表
启动MySQL cli容器连接MySQL Server,创建数据库和数据表。
docker run -it --network host --rm mysql:latest mysql --default-character-set=utf8mb4 -h127.0.0.1 -P3306 -uroot -p 2、修改项目中的配置文件configs/config.yml
MySQL和Redis要使用自己的地址。
3、定义配置pb文件internal/conf/conf/proto ,生成配置代码
注意!配置文件要和定义的pb文件层级、字段一一对应!!!
否则配置文件与结构体字段对不上,项目中就无法正确解析到配置。
make config或者,电脑上没有make的同学可执行以下命令:
protoc --proto_path=./internal \
--proto_path=./third_party \
--go_out=paths=source_relative:./internal \
internal/conf/conf.protoGORM Gen框架生成代码
借助Gen框架生成dal层代码,提升开发效率。
开发接口流程
1、定义API文件
按照需要编写proto文件
2、生成客户端和服务端代码
make api
3、填充业务逻辑
internal目录下
server -> service -> biz -> data
4、更新ProviderSet执行Wire实现依赖注入
默认的还是 GreeterService 相关的,需要换成我们的服务。
业务开发
功能点
评价服务(review-service)
创建评价
- 雪花算法生成ID
- validate参数校验
- https://go-kratos.dev/docs/component/middleware/validate
- 使用方法
- 下载插件:
go install github.com/envoyproxy/protoc-gen-validate@latest - 在pb文件中按要求编写字段校验规则:在我们项目的
api/review/v1/review.proto文件中 - 生成代码
- 注意复制粘贴到Makefile文件中的代码格式
- 注意在
api/review/v1/review.proto要导入import "validate/validate.proto";
- 注册参数校验中间件
import github.com/go-kratos/kratos/v2/middleware/validate

- 下载插件:
- 错误处理
- https://go-kratos.dev/docs/component/errors
- 使用方法
- 定义proto文件
- 生成代码
- 业务代码中使用生成的代码返回错误
评价详情
审核评价
申诉评价
回复评价
- review-service 新增RPC方法
- GORM-GEN事务操作
- 防水平越权
- review-service 新增RPC方法
查询评价
⭐️评价列表(筛选)
评价服务C端(review-c)
- 发表评价
- 查看评价
- 查看自己的全部评价
评价B端(review-b)
- 店铺评价列表
- 店铺评价详情
- 回复评价
- 申诉评价
评价O端(review-o)
- 评价列表(筛选)
- 评价详情
- 审核评价
- 审核申诉
关键点
- 雪花算法生成ID
- validate参数校验
- GORM事务操作
- 接口幂等
- 接口防止水平越权
项目中如何管理pb文件
- proto文件要用一个
- protoc要使用同一个版本
通常在公司中都是把 proto 文件和生成的不同语言的代码都放在一个单独的公用代码库中。
别的项目直接引用这个公用代码库。
review-b –RPC–> review-service
git submodule
语法:git子模块
项目中添加子模块。将 git@github.com:Q1mi/reviewapis.git作为当前项目的子目录,目录名为api。
也就是说,当前项目下的 api 目录是引用了另外一个git项目。
git submodule add git@github.com:Q1mi/reviewapis.git ./api当前目录下会多一个.gitmodules文件
❯ cat .gitmodules
[submodule "api"]
path = api
url = git@github.com:Q1mi/reviewapis.git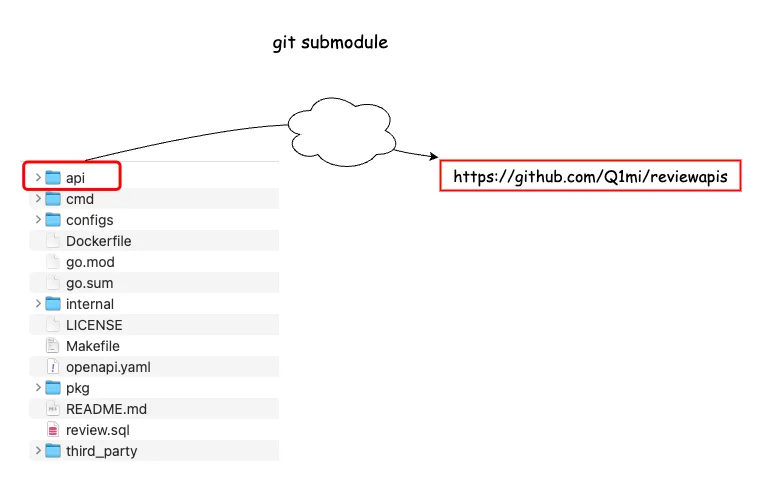
常用命令:
# 用来初始化本地配置文件
git submodule init
# 从该项目中抓取所有数据并检出父项目中列出的合适的提交。
git submodule updatekratos项目gRPC客服端调用
kratos框架服务注册与服务发现
新增注册中心配置(实现准备好注册中心以consul为例)
- internal/conf/xx.proto
- configs/xx.yaml
review-service添加服务注册流程
- 注册的时机 –> internal/server层 –> 提供构造函数–> wire注入
- main函数传入conf.Registry配置
- 指定应用程序的name和version,在注册时使用
review-b添加服务发现流程
服务发现的时机 –> internal/data 层 –> 提供构造函数 –> wire注入
main函数传入conf.Registry配置
review-o、review-b、review-service 速览
每个评价只允许申诉一次。
评价申诉时如果有一个未审核的审核则更新该申诉。
如果存在则更新否则新增数据
INSERT INTO `table` *** ON DUPLICATE KEY UPDATE ***;canal介绍和使用
https://liwenzhou.com/posts/go/canal/
Kafka简介
Apache Kafka是一个开源的分布式流系统,该项目旨在提供一个统一的、高吞吐量、低延迟的平台,用于处理实时数据流。它具有以下特点:
- 支持消息的发布和订阅,类似于 RabbtMQ、RocketMQ 等消息队列;
- 支持数据实时处理;
- 能保证消息的可靠性投递;
- 支持消息的持久化存储,并通过多副本分布式的存储方案来保证消息的容错;
- 高吞吐率,单 Broker 可以轻松处理数千个分区以及每秒百万级的消息量。
Kafka最初是由领英开发,并随后于2011年初开源。并于2012年10月23日由Apache Incubator孵化出站。
架构
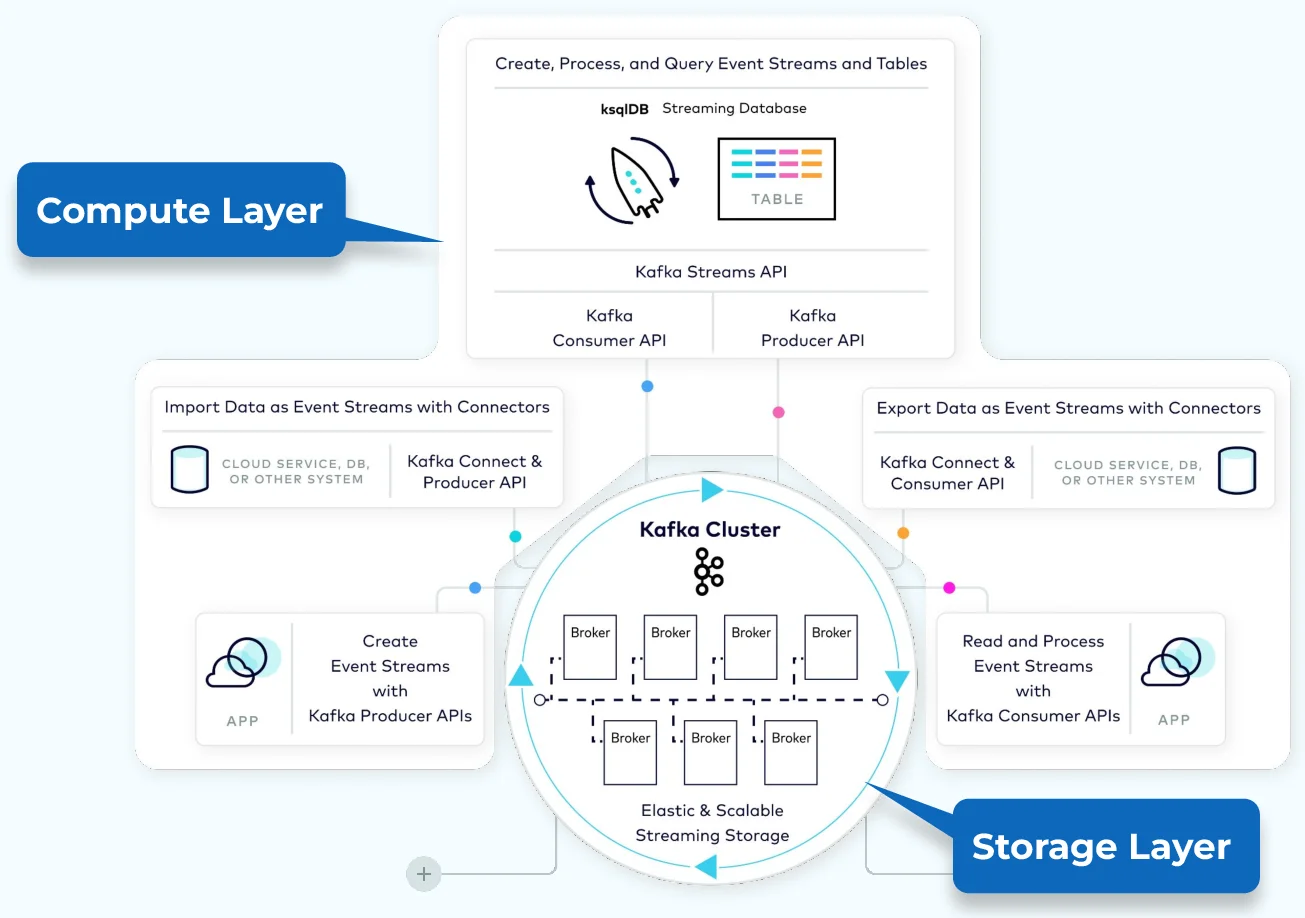
Kafka是一个数据流系统,允许开发人员在新事件发生时实时做出反应。Kafka体系结构由存储层和计算层组成。存储层旨在高效地存储数据,是一个分布式系统,可以轻松地扩展系统以适应增长。
计算层由四个核心组件组成——生产者、消费者、流和连接器API,它们允许Kafka在分布式系统中扩展应用程序。
生产者(Producer)
消费者(Consumer)
流处理(Streams)
连接器(Connectors)APIs
相关术语
Messages And Batches:Kafka 的基本数据单元被称为 message(消息),为减少网络开销,提高效率,多个消息会被放入同一批次 (Batch) 中后再写入。
Topic:用来对消息进行分类,每个进入到Kafka的信息都会被放到一个Topic下
Broker:用来实现数据存储的主机服务器,kafka节点
Partition:每个Topic中的消息会被分为若干个Partition,以提高消息的处理效率
Producer:消息的生产者
Consumer:消息的消费者
Consumer Group:消息的消费群组
主题
Kafka 的消息通过 Topics(主题) 进行分类,一个主题可以被分为若干个 Partitions(分区),一个分区就是一个提交日志 (commit log)。消息以追加的方式写入分区,然后以先入先出的顺序读取。Kafka 通过分区来实现数据的冗余和伸缩性,分区可以分布在不同的服务器上,这意味着一个 Topic 可以横跨多个服务器,以提供比单个服务器更强大的性能。
由于一个 Topic 包含多个分区,因此无法在整个 Topic 范围内保证消息的顺序性,但可以保证消息在单个分区内的顺序性。
主题分区
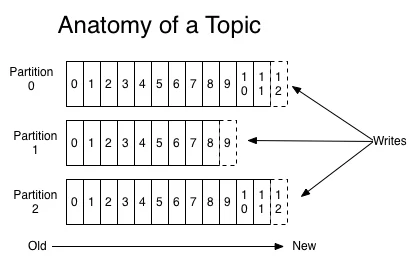
为了分散主题中事件的存储和处理,Kafka使用了分区的概念。一个主题由一个或多个分区组成,这些分区可以位于Kafka集群中的不同节点上。
每个分区都是一个有序的,不可变的记录序列,不断附加到结构化的提交日志中。分区中的记录每个都分配了一个称为偏移的顺序ID号,它唯一地标识分区中的每个记录。
Kafka集群支持按配置持久化保存所有已发布的记录。例如,如果保留策略设置为两天,则在发布记录后的两天内,它可供消费,之后将被丢弃以释放空间。
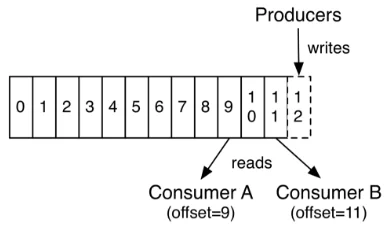
生产者
生产者负责创建消息。一般情况下,生产者在把消息均衡地分布到在主题的所有分区上,而并不关心消息会被写到哪个分区。如果我们想要把消息写到指定的分区,可以通过自定义分区器来实现。
消费者
消费者是消费者群组的一部分,消费者负责消费消息。消费者可以订阅一个或者多个主题,并按照消息生成的顺序来读取它们。消费者通过检查消息的偏移量 (offset) 来区分读取过的消息。偏移量是一个不断递增的数值,在创建消息时,Kafka 会把它添加到其中,在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的偏移量保存在 Zookeeper 或 Kafka 上,如果消费者关闭或者重启,它还可以重新获取该偏移量,以保证读取状态不会丢失。
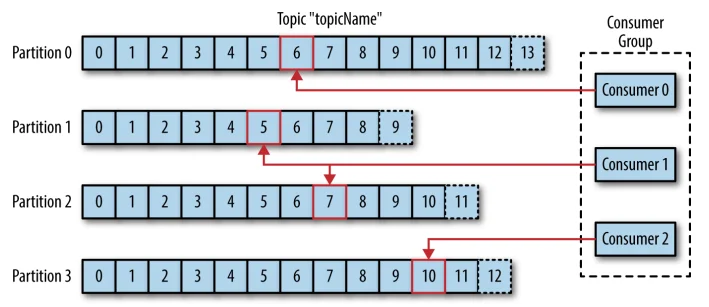
消费者组
一个分区只能被同一个消费者群组里面的一个消费者读取,但可以被不同消费者群组中所组成的多个消费者共同读取。多个消费者群组中消费者共同读取同一个主题时,彼此之间互不影响。
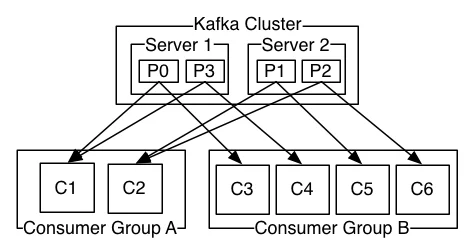
Brokers And Clusters
一个独立的 Kafka 服务器被称为 Broker。Broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。Broker 为消费者提供服务,对读取分区的请求做出响应,返回已经提交到磁盘的消息。
Broker 是集群 (Cluster) 的组成部分。每一个集群都会选举出一个 Broker 作为集群控制器 (Controller),集群控制器负责管理工作,包括将分区分配给 Broker 和监控 Broker。
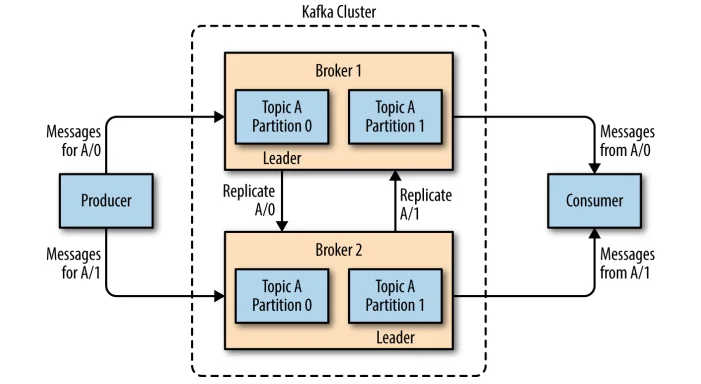
在集群中,一个分区 (Partition) 从属一个 Broker,该 Broker 被称为分区的首领 (Leader)。一个分区可以分配给多个 Brokers,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果有一个 Broker 失效,其他 Broker 可以接管领导权。
参考资料
https://developer.confluent.io/courses/architecture/get-started/
https://github.com/heibaiying/BigData-Notes/blob/master/notes/Kafka%E7%AE%80%E4%BB%8B.md
其他补充
目前社区还有一个pulsar 是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐以及低延时的高可扩展流数据存储特性。
搭建Kafka环境和Go客户端
Kafka Go客户端Kafka-go 使用: https://liwenzhou.com/posts/go/kafka-go/
ES介绍
https://liwenzhou.com/posts/go/elasticsearch/
go-elasticsearch 使用
https://liwenzhou.com/posts/go/go-elasticsearch/
review-job / review-task
后端服务分类:
service:微服务,提供API
job:流式服务,处理实时流
task:定时任务,定时处理业务
查询评价(ES查询)
ES查询方式: https://zhuanlan.zhihu.com/p/344773076
- 精确查询Term:term是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇
- 匹配查询match:elasticsearch会根据你给定的字段提供合适的分析器,而term查询不会有分析器分析的过程,match查询相当于模糊匹配,只包含其中一部分关键词就行(分词+匹配)
- bool查询:包含四种操作符,分别是must,should,must_not,query。它们均是一种数组,数组里面是对应的判断条件
- 过滤器Filter:会查询对结果进行缓存,不会计算相关度,避免计算分值,执行速度非常快。
补充:
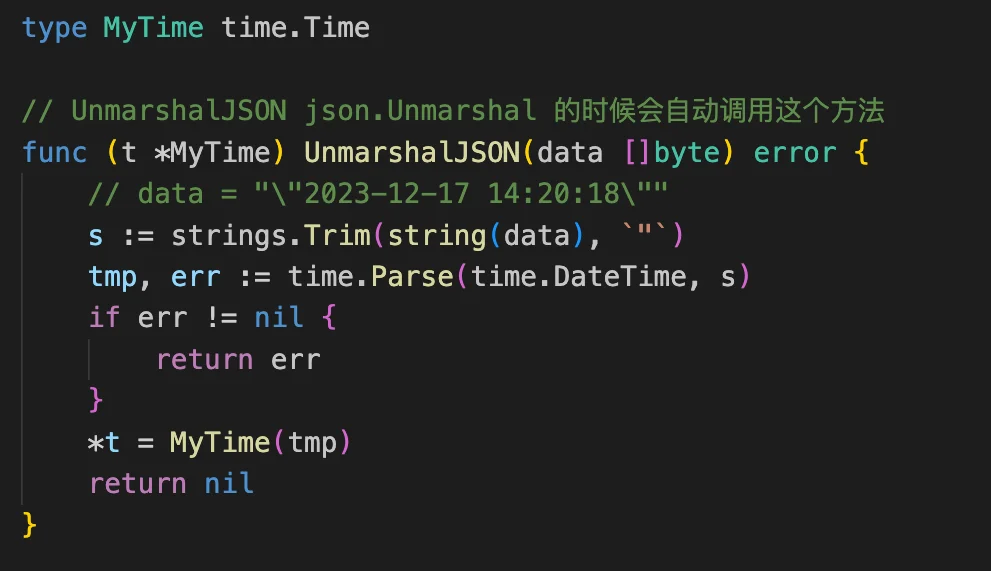
1、Go语言里面的时间格式化
Json.Unmarshal “2023-12-17 14:20:18” –> time.Time
“2006-01-02T15:04:05Z07:00”
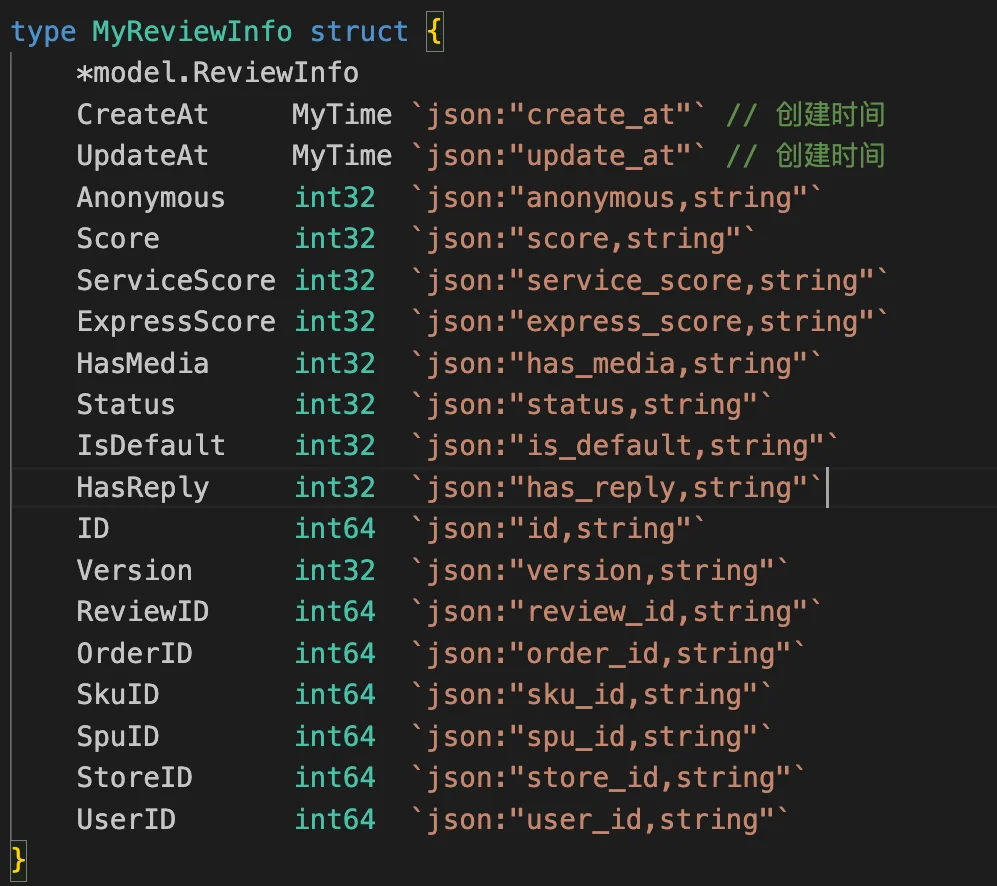
2、灵活运用 json:"id,string"
缓存设计
首先在查询ES时尽量使用filter,使得ES使用缓存。
其次,在ES前可增加一层Redis缓存,通过 singleflight 在语言层面合并多次并发的查询ES的请求,将ES的返回结果缓存到Redis中。
补充知识点:更新缓存的的Design Pattern有四种:Cache aside、Read through、Write through 、Write behind caching
针对我们这个评价服务而言,其对数据一致性要求没有那么高,所以缓存的更新相对容易实现。(没有太多的顾虑,直接查询完更新即可)
API文档
生成openapi.yaml
kratos 框架支持生成 openapi.yaml 文件。 👉 https://go-kratos.dev/docs/guide/openapi
只需执行以下两步:
1、安装生成openapi文件的 protoc 插件
go install github.com/google/gnostic/cmd/protoc-gen-openapi@latest2、项目根目录下执行以下命令根据API的 proto文件生成 openapi.yaml文件
make api如何使用 openapi.yaml文件?/如何生成API文档?
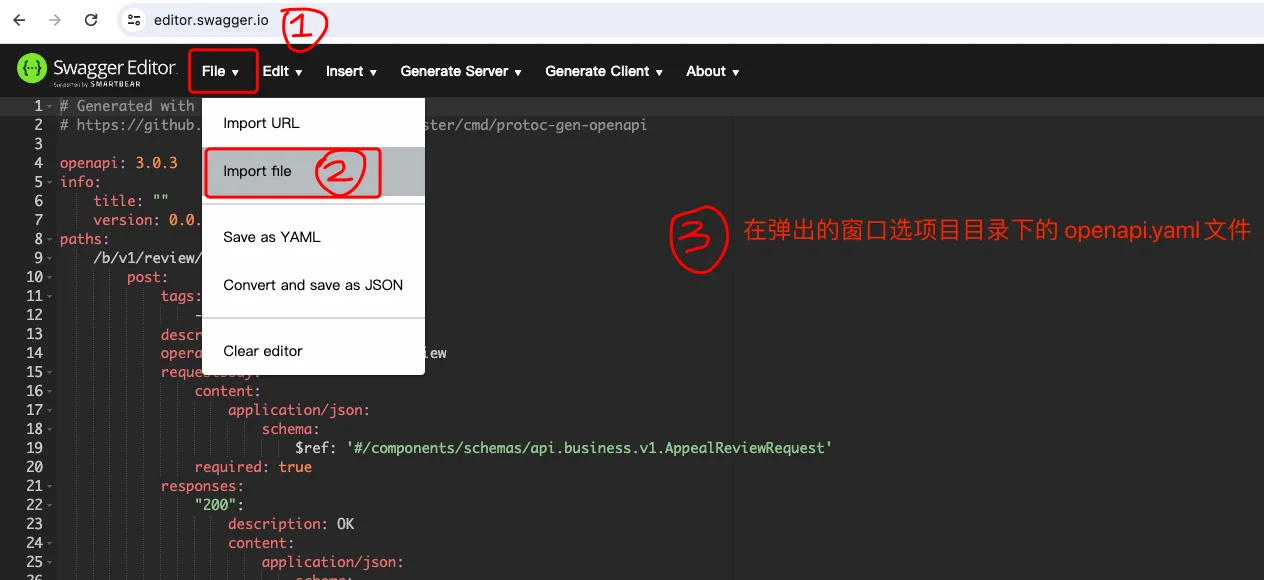
swagger.io 提供了开源的 Swagger Editor ,直接导入项目目录下的 openapi.yaml 文件皆可。
1、打开 https://editor.swagger.io/
2、导入文件
3、大功告成。如下图
当然也可以使用任意支持 openapi 的其他程序渲染API文档。
补充说明
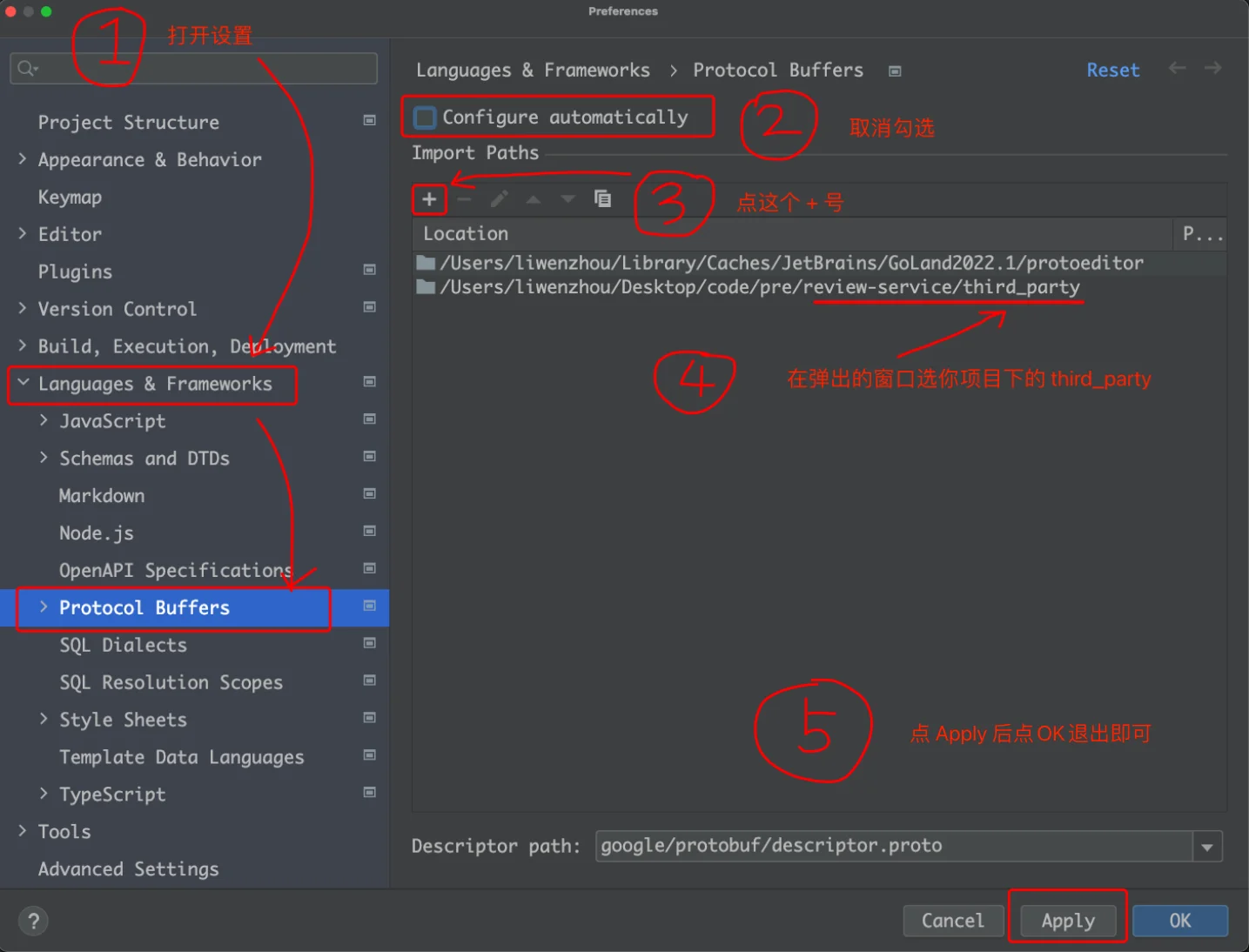
Goland proto文件里面有标红提示 看这个!!!
项目总结
项目收益
了解了大型中台项目的架构设计。
锻炼了自己使用常用中间件解决业务问题的能力。
对微服务的理解更深刻了。
对kratos框架及组件更熟悉了。
简历辅导
简历怎么写?
**黄金法则:**清晰!亮点!匹配度! 👉🏻 让别人看了你的简历就想约你面试!
项目介绍:说清楚你写了个什么项目,能干啥,有啥用,有数据支撑最好!
个人职责:写清楚你在项目里作为什么角色,做了哪些事情,抓住重点写!写到别人的心坎里。
项目收获:这个项目给公司带来啥收益,你从这个项目学到了啥。
评价系统项目简历示例:
项目介绍:评价服务为公司电商业务提供了用户评价相关能力。整个评价服务包含C端、B端和O端三部分,涉及C端用户发表评价,O端运营审核评价以及B端商家查看/回复评价等主要业务流程。 个人职责:
- 负责项目的整体架构设计,根据业务发展需要持续演进架构设计。
- 采用CQRS架构模式实现项目中读、写操作采用不同的存储模型。
- 编写review-job服务采用Canal+Kafka将MySQL中的评价数据同步至ES。
- C端查看评价增加Redis缓存,代码层面使用 singleflight 合并短时间内并发请求。
项目收获
- 主导评价服务向服务化、平台化发展,成为独立的评价中台能力。
- 熟悉了Kratos微服务框架,能够熟练使用Kratos各组件进行业务开发。
- 熟练使用Canal、Kafka和ES等各种中间件解决业务问题。
- 锻炼了自己的自主学习能力,积累了大型项目设计和开发经验。
补充说明:我们课上虽然讲的是『评价服务』,但是 『评论服务』 也是类似的。如果你觉着简历上写『评价服务』不合适,你也可以写『评论服务』,项目思路和使用到的中间件都类似。
面试怎么说
说清楚项目背景
- 最开始是一个大单体的电商项目,里面有一个模块是评价相关的。后面随着业务发展整个项目重构了,顺势把评价拆分成一个独立的微服务中台项目。
说清楚项目架构
- 能够画出实际的架构图,并能够清楚的说出每个组件的功能。
项目是如何部署的?
- 作为单独的微服务部署了一个集群。大概C端xx个实例、B端x个实例,O端x个实例,job模块x个实例。
说清楚项目实现过程中的重点和难点
- CQRS架构
- 这个可以当成是简历上的钩子,面试的时候多说一下。
- Canal的原理及使用
- 用的什么工具不重要,重要的是要有解决问题的思路和方法。
- Kafka的原理及使用
- 网上搜下kafka的面试八股文,多看!
- ES的原理及使用
- 网上搜下ES的面试八股文,多看!
- 缓存的更新模式 👉 缓存更新的套路
- 也是一个面试的时候可以多说的点。
- CQRS架构
推荐大家一本书 《微服务架构设计模式》
扩展资料
产品设计角度
社交APP的评论功能分析 ——基于微博、网易云音乐、Keep等的产品分析
Designing Better Online Review Systems