容器与Docker
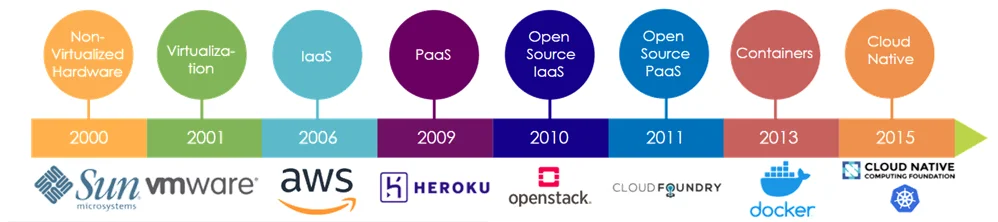
云计算发展
云计算需要我们继续购买大量的服务器,而我们的应用程序是构建在物理硬件上。从非虚拟化的硬件世界到虚拟化(虽然托管的硬件较少,但仍托管在物理服务器上),到平台即服务(PaaS),到开源的,云对接容器,再到现在的云原生世界,现代应用程序越来越多地使用容器构建。
硬件虚拟化采用虚拟机的方式进行应用隔离,属于重型隔离(一台服务器装多个操作系统),会浪费服务器的性能。
传统的 PaaS 模式,准备应用的依赖环境、打包和部署应用都非常的繁琐。想象一下有些程序明明在开发环境能够正常运行,可部署到服务器上就是跑不起来。
Docker 用镜像来实现本地环境和云端环境的高度一致,解决了打包困难的问题,取代了 Cloud Foundry 这类 PaaS 项目中的“沙盒”。Docker 因此崛起。
随着 Docker 被大范围使用,PaaS 的定义逐渐演变成了一套以容器技术为核心,全新的”容器化“思路。
为什么现在业界都在使用容器化?
为了资源利用最大化,需要在一台服务器上部署多个应用,而且是高效的部署。
- 云厂商可以将一个服务器卖给多个用户,也就是同一台服务器上可能会部署不同用户的不同应用,他们之间需要隔离。
- 大厂内部也会把不同的应用进行混布,提高资源利用率。
总结一下就是:
- 成本低
- 简单易用
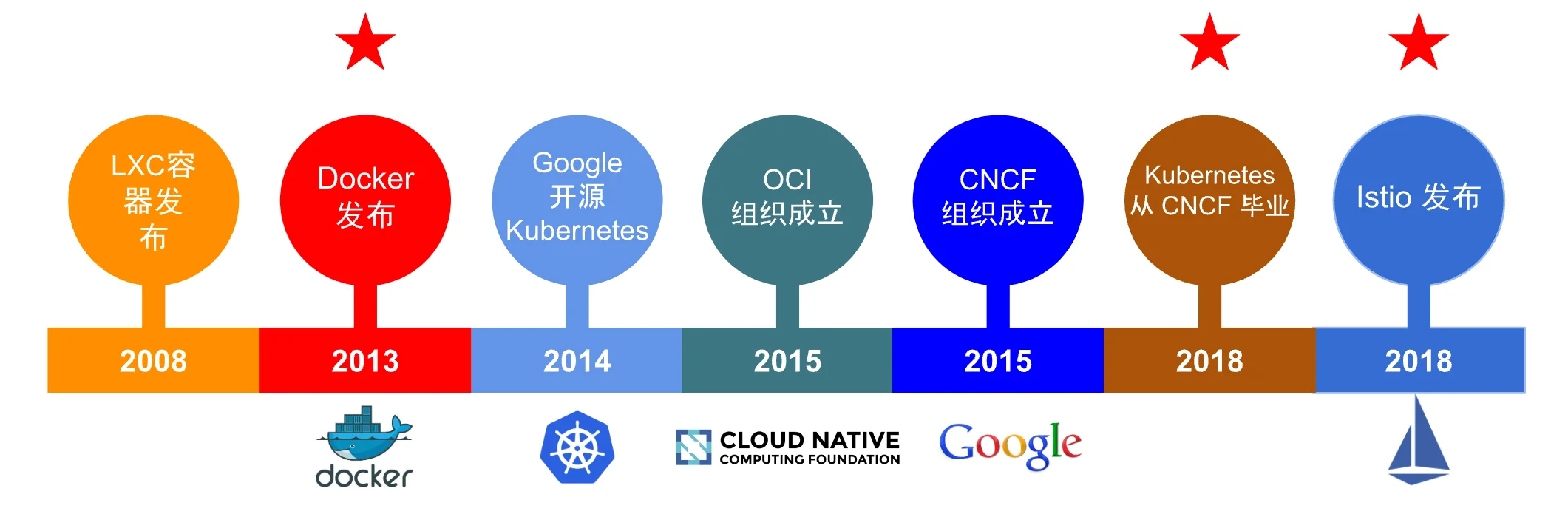
容器技术发展
容器简介
容器其实就是一种沙盒技术,沙盒指的是像集装箱一样把你的应用装起来,不同的集装箱之间是隔离的、互不干扰,应用可以像集装箱一样很容易的搬来搬去,在不同的地方运行。
要实现这种沙盒机制,就需要实现『隔离』和『限制』。
容器概念
程序
程序员编写了应用程序代码,在运行的时候通常需要给它提供所需数据,这些数据加上代码本身的二进制文件,放在磁盘上,就是我们平常所说的一个“程序”。
进程
首先,操作系统将“程序”运行需要的数据加载到内存中待命,同时,操作系统又读取程序指令,调用 CPU 完成操作、与内存协作,以及与各种各样的 I/O 设备交互。“程序”被执行起来,它就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。像这样一个程序运行起来后的计算机执行环境的总和,就称为进程。
容器
而容器本质上就是一个加了限定参数的进程,是一组与系统其余部分隔离的一个或多个进程。
容器的实现原理
容器的实现,主要归结于三大技术:命名空间 ( Namespaces ) 、控制组 ( Control Groups ) 和联合文件系统 ( Union File System ) 。
NameSpace
Namespace 作为 Linux 内核的组成部分大约出现于 2002 年,随着时间的推移,Linux 内核添加了更多的工具和 namespace 类型。然而,直到 2013 年,Linux 内核才添加了真正的容器支持。至此,namespace 开始大显身手,并得到了广泛应用。
Namespace 是 Linux 内核的一项功能,它对内核资源进行分区,以便一组进程看到一组资源,而另一组进程看到一组不同的资源。Docker 容器实际上是在创建容器进程时,指定了这个进程所需要启用的一组 Namespace 参数。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
Namespace 的类型
Linux 内核包含了不同类型的 namespace。每个命名空间可以隔离某个全局系统资源。
查看Linux 系统内核:
usname -a不同的内核命名空间不同,例如:
4.6加入cgroup namespce,5.6加入time namespace。我这里使用 ubuntu22.04 ,内核版本
5.15。
使用 lsns 或 ls -lai /proc/<PID>/ns查看名称空间。
root@ubuntu2204:~# lsns
NS TYPE NPROCS PID USER COMMAND
4026531834 time 118 1 root /sbin/init noibrs
4026531835 cgroup 118 1 root /sbin/init noibrs
4026531836 pid 118 1 root /sbin/init noibrs
4026531837 user 118 1 root /sbin/init noibrs
4026531838 uts 114 1 root /sbin/init noibrs
4026531839 ipc 118 1 root /sbin/init noibrs
4026531840 net 118 1 root /sbin/init noibrs
4026531841 mnt 110 1 root /sbin/init noibrsref:https://en.wikipedia.org/wiki/Linux_namespaces
其中:
Time namespace:隔离了
CLOCK_MONOTONIC和CLOCK_BOOTTIME系统时钟,它们影响了针对这些时钟(如系统正常运行时间)测量的 API。Cgroup namespace:隔离 cgroup 根目录,控制着进程能看到的 cgroup 。
PID namespace:隔离进程标识符(PID)、进程列表及其详细信息。虽然新的命名空间与其他同级命名空间隔离,但其“父”命名空间中的进程仍然可以看到子命名空间中的所有进程,尽管PID号码不同。
User namespace :该命名空间隔离了用户 ID、组 ID、根目录等。这样,进程就可以在命名空间内成为 root 进程,而不能在命名空间外(如在 host 中)成为 root 进程。
UTS namespace:隔离主机名和域名
IPC namespace:隔离进程间通信机制,如 System V 和 POSIX 消息队列。
Mount namespace:隔离每个名称空间中的挂载点列表。在单独的 mount namespace 中运行的进程可以挂载和卸载,而不会影响其他 namespace。
network namespace :隔离了(物理或虚拟的)网络接口控制器、iptables 防火墙规则、路由表等。网络命名空间可以使用"veth"虚拟以太网设备连接在一起。
创建 namespace
从上面的内容我们已经简单了解了 namespace 是什么,接下来看看如何与 namespace 交互。在 Linux 中,有一组允许创建、加入和发现 namespace 的系统调用。
clone:这个系统调用实际上创建了一个新进程。但借助 flags 参数,新进程将创建自己的新命名空间。setns:此系统调用允许正在运行的进程加入现有的命名空间。unshare:该系统调用实际上与 clone 相同,但不同之处在于,unshare 是在隔离的命名空间运行当前进程,而clone将创建一个具有新命名空间的新进程。
fork和vfork内部系统调用只是使用不同的参数调用clone()。
上面这些系统调用在创建 namespace 时需要用到以下 namespace flag 。
CLONE_NEWCGROUP Cgroup namespaces
CLONE_NEWIPC IPC namespaces
CLONE_NEWNET Network namespaces
CLONE_NEWNS Mount namespaces
CLONE_NEWPID PID namespaces
CLONE_NEWTIME Time namespaces
CLONE_NEWUSER User namespaces
CLONE_NEWUTS UTS namespaces例如,如果你想为当前进程创建一个新的 UTS namespace,你应该用 CLONE_NEWUTS 标记调用unshare 命令。
如果你想使用 User namespaces 和 UTS namespace 创建新进程,你应该用CLONE_NEWUSER|CLONE_NEWUTS 调用 clone。
举个例子:
下面使用 unshare 命令创建一个新的 namespace ,它有自己的用户名称空间和 PID 名称空间。我将根用户映射到新的名称空间(换句话说,我在新的名称空间中具有根特权) ,挂载一个新的 proc 文件系统,并在新创建的名称空间中 fork 我的进程(在本例中是 bash)。
root@ubuntu2204:~# unshare --user --pid --map-root-user --mount-proc --fork bash
root@ubuntu2204:~# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 10:34 pts/0 00:00:00 bash
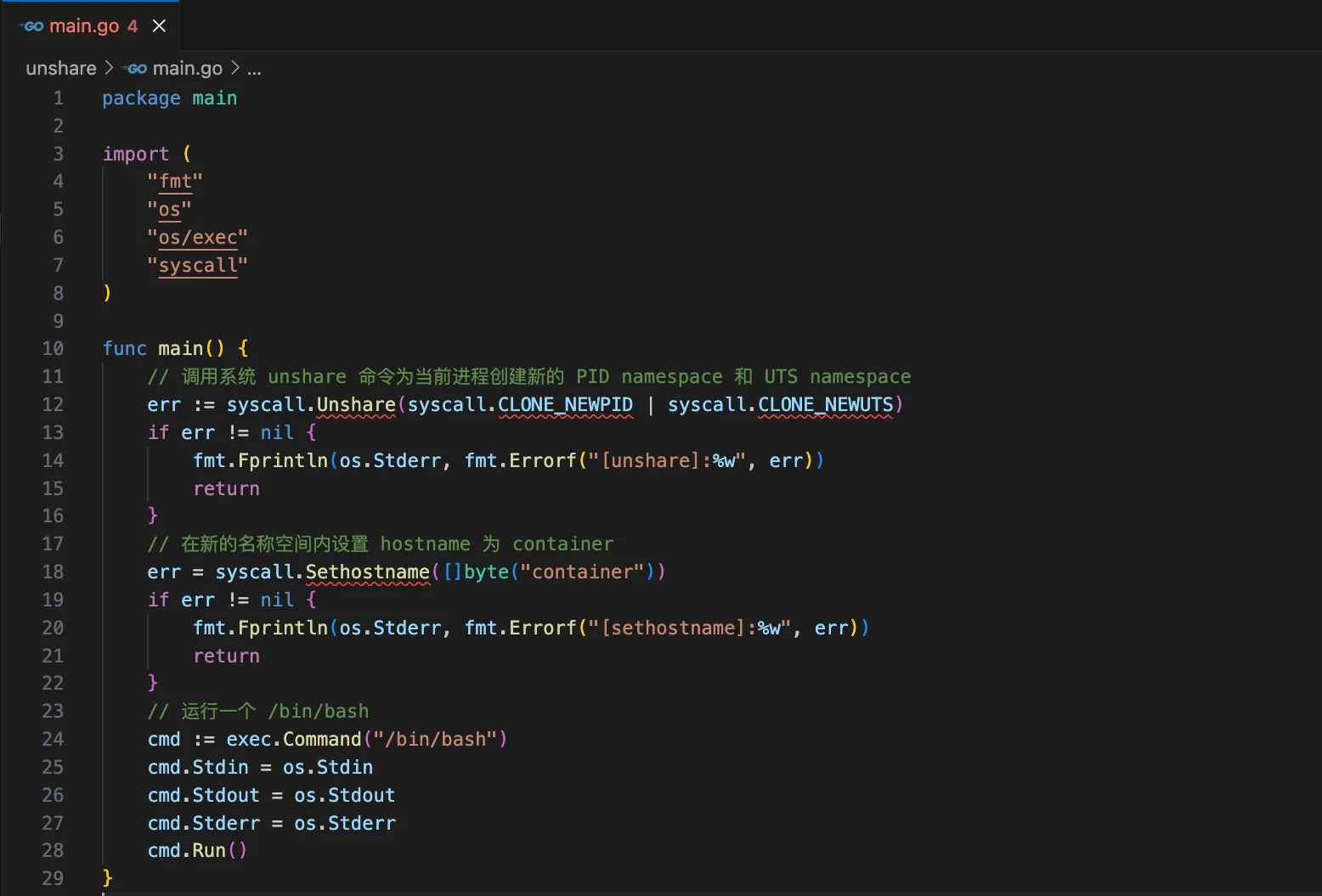
root 8 1 0 10:35 pts/0 00:00:00 ps -ef我们这里使用 Go 语言演示如何创建 PID namespace 和 UTS namespace。
//go:build linux
// +build linux
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
// 调用系统 unshare 命令为当前进程创建新的 PID namespace 和 UTS namespace
err := syscall.Unshare(syscall.CLONE_NEWPID | syscall.CLONE_NEWUTS)
if err != nil {
fmt.Fprintln(os.Stderr, err)
}
// 在新的名称空间内设置 hostname 为 container
err = syscall.Sethostname([]byte("container"))
if err != nil {
fmt.Fprintln(os.Stderr, err)
}
// 运行一个 /bin/bash
cmd := exec.Command("/bin/bash")
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Run()
}将上述程序编译后在我们的 Ubuntu 上执行。
注意:创建除了
UID namespace之外的任何 namespace 都需要 root 权限。
qimi@ubuntu2204:namespace$ sudo ./unshare_demo
[sudo] password for qimi:
root@container:/home/qimi/workspace/namespace# hostname
container
root@container:/home/qimi/workspace/namespace# id
uid=0(root) gid=0(root) groups=0(root)
root@container:/home/qimi/workspace/namespace# exit
exit
qimi@ubuntu2204:namespace$ hostname
ubuntu2204
qimi@ubuntu2204:namespace$ id
uid=1000(qimi) gid=1000(qimi) groups=1000(qimi)可以看到新建的 UTS namespace 内的 hostname 和主机的不一样,这就实现了主机名隔离。
那如何只列出命名空间内可见的进程呢?
实现挂载一个新的 /proc。
proc 文件系统是一个伪文件系统,为内核数据结构提供了一个接口。它通常挂载在 /proc。进程信息存储在 /proc 文件夹下,proc 文件系统中的大部分文件都是只读文件,它们是动态的,存储在内存中。
默认情况下,每个人都可以访问所有 /proc/[pid]目录,除了进程信息,你还可以更新进程配置。
为了将容器的进程列表与主机隔离,我们需要挂载一个新的 /proc 目录,而不是共享主机的 /proc。
在容器内执行以下命令:
root@container:/home/qimi/workspace/namespace# mount -t proc proc /proc即可实现只列出当前命名空间内的进程。
root@container:/home/qimi/workspace/namespace# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 22:34 pts/3 00:00:00 /bin/bash
root 10 1 0 22:34 pts/3 00:00:00 ps -ef进阶:
有了自己的
/proc目录后就支持独立进程信息,但我们仍然与主机共享其他文件系统,如果我们想拥有一个全新的文件系统,我们需要准备一个新的根文件系统,并用新的文件系统替换默认根文件系统。容器中的文件系统怎么来?需要先挂载一个容器自己的
rootfs,然后再用chroot或pivot_root切换根目录。rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。
再配置上网络,这样就能逐步创建出一个容器了。
注意:
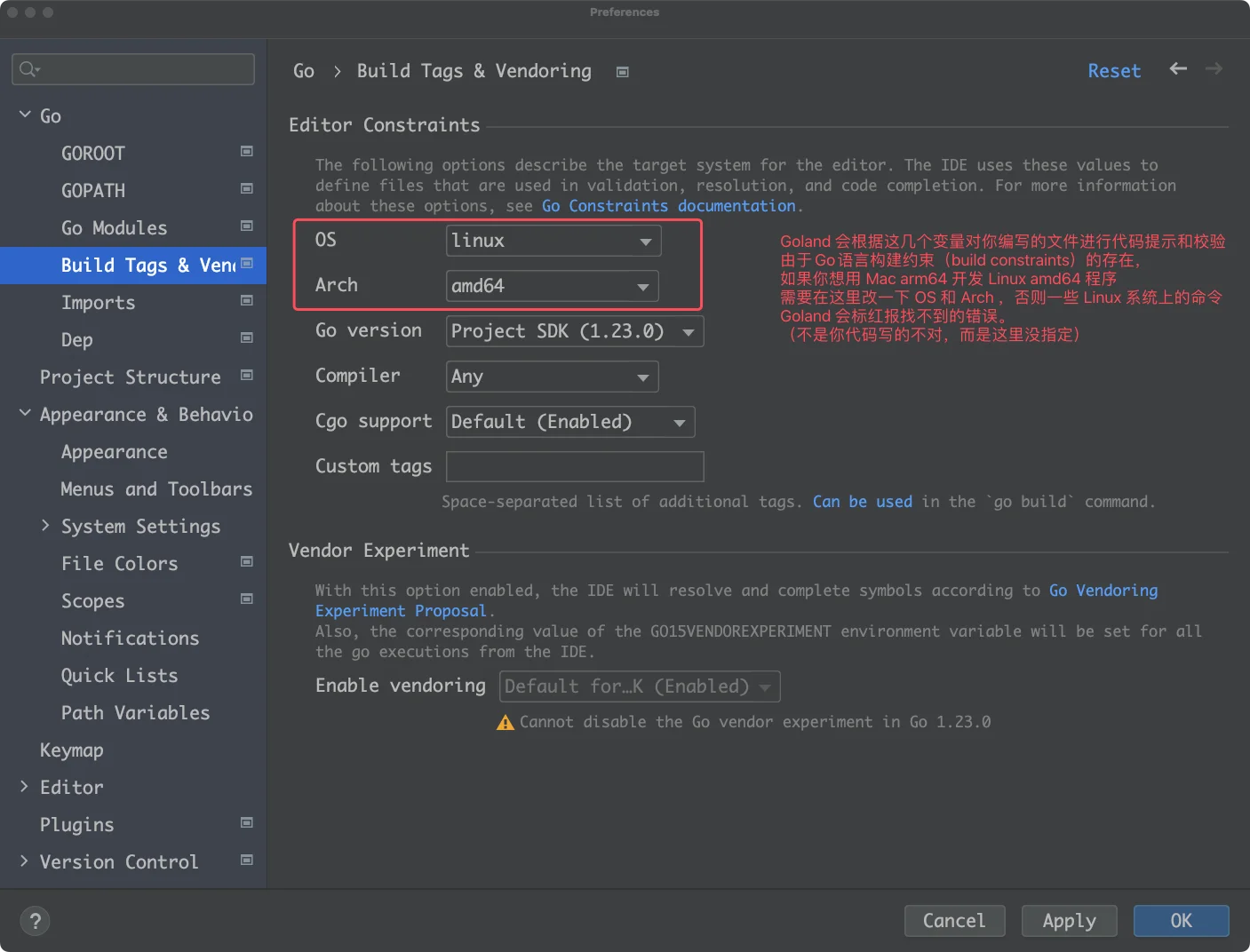
Go 语言构建约束 👉 https://pkg.go.dev/cmd/go#hdr-Build_constraints
如果你使用 VS Code 遇到如下的飘红报错提示,不要紧张。
在文件最上面添加 go:build 构建约束即可。// 和go:build 之前没有空格。
//go:build linux老版本写法
// +build linux
加了这个构建约束后编辑器会按照指定的编译平台完成自动补全和语法提示,要编译时记得指定GOOS 和GOARCH。
❯ GOOS=linux GOARCH=amd64 go build # 在 Mac 编译 Linux 程序如果你使用 Goland 还有另外一种方法是按照下图修改下配置即可。
PID namespace 示例
下面以 PID namespace 为例介绍 namespace 隔离。
下图中共有三个 PID namespace:一个父 namespace 和两个子 namespace。父 namespace 中共有四个进程,PID1 至 PID4。这些都是正常的进程,它们可以看到彼此并共享资源。
父 namespace 中使用 PID2 和 PID3 的子进程也属于它们各自的 PID namespace(PID 为 1)。在子 namespace 中,PID1 进程看不到任何外部资源。例如,两个子 namespace 中的 PID1 看不到父 namespace 中的 PID4。
在这种情况下,这使得不同 namespace 中的进程之间得以隔离。

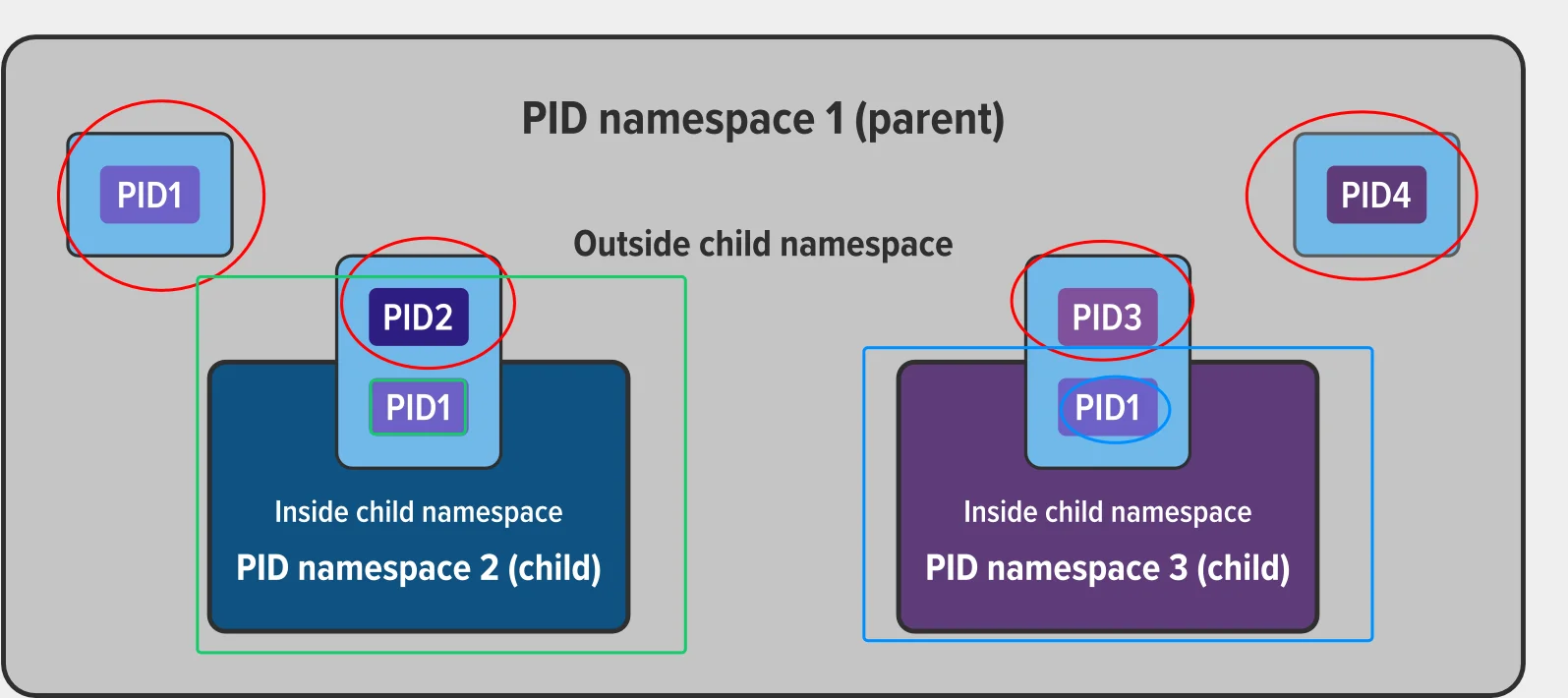
Namespace 是容器的基础技术之一,用于隔离资源。
你可以手动创建 namespace,Docker、rkt 和 podman 等容器运行时可为你创建 namespace,不需要开发者手动创建。
Control Groups
控制组 (cgroup) 是 Linux 内核的一个特性,用于限制、记录和隔离一组进程的资源使用(CPU、内存、磁盘 I/O、网络等)。
Cgroup 具有以下特性:
- 资源限制 —— 可以配置 cgroup,从而限制进程可以对特定资源(例如内存或 CPU)的使用量。
- 优先级 —— 当资源发生冲突时,可以控制一个进程相比另一个 cgroup 中的进程可以使用的资源量(CPU、磁盘或网络)。
- 记录 —— 在 cgroup 级别监控和报告资源限制。
- 控制 —— 可以使用单个命令更改 cgroup 中所有进程的状态(冻结、停止或重新启动)。
Cgroup 配置是按文件系统层级组织的,按照惯例,cgroup 目录挂载在 /sys/fs/cgroup 下,我们可以在这个目录下设置进程相关的资源限制。
注意,本文使用的是 cgroup v2。
目前有 cgroup v1和 cgroup v2 两个版本,使用上会有些许区别。
- v1 为每个控制器使用独立的树(例如
/sys/fs/cgroup/cpu/GROUPNAME和/sys/fs/cgroup/memory/GROUPNAME)。- v2 将统一
/sys/fs/cgroup/GROUPNAME中的树,如果进程 X 加入/sys/fs/cgroup/test,则启用 test 的每个控制器都将控制进程 X。
Cgroup 配置适用于进程,如果父进程的资源受到限制,其子进程也会自动根据父进程的 Cgroup 限制受到限制。
举个例子:
root@ubuntu2204:~# cd /sys/fs/cgroup/
root@ubuntu2204:/sys/fs/cgroup# ls
aegis cgroup.subtree_control dev-mqueue.mount memory.numa_stat sys-kernel-debug.mount
aegisMonitor cgroup.threads init.scope memory.pressure sys-kernel-tracing.mount
cgroup.controllers cpu.pressure io.cost.model memory.stat system.slice
cgroup.max.depth cpuset.cpus.effective io.cost.qos misc.capacity user.slice
cgroup.max.descendants cpuset.mems.effective io.pressure proc-sys-fs-binfmt_misc.mount
cgroup.procs cpu.stat io.prio.class sys-fs-fuse-connections.mount
cgroup.stat dev-hugepages.mount io.stat sys-kernel-config.mount
root@ubuntu2204:/sys/fs/cgroup# mkdir qimi-container # 创建一个 qimi-container 目录
root@ubuntu2204:/sys/fs/cgroup# cd qimi-container/
root@ubuntu2204:/sys/fs/cgroup/qimi-container# ls
cgroup.controllers cgroup.type cpu.stat memory.current memory.stat
cgroup.events cpu.idle cpu.uclamp.max memory.events memory.swap.current
cgroup.freeze cpu.max cpu.uclamp.min memory.events.local memory.swap.events
cgroup.kill cpu.max.burst cpu.weight memory.high memory.swap.high
cgroup.max.depth cpu.pressure cpu.weight.nice memory.low memory.swap.max
cgroup.max.descendants cpuset.cpus io.max memory.max pids.current
cgroup.procs cpuset.cpus.effective io.pressure memory.min pids.events
cgroup.stat cpuset.cpus.partition io.prio.class memory.numa_stat pids.max
cgroup.subtree_control cpuset.mems io.stat memory.oom.group
cgroup.threads cpuset.mems.effective io.weight memory.pressureCPU限制
执行一个死循环,记住返回的 PID,后面要用上。
root@ubuntu2204:/sys/fs/cgroup/qimi-container# while : ; do : ; done &
[1] 1575查看这个进程的 CPU 占用,默认会占用 100% CPU 。
top -p 1575
top - 16:52:56 up 29 min, 2 users, load average: 1.09, 0.41, 0.15
Tasks: 1 total, 1 running, 0 sleeping, 0 stopped, 0 zombie
%Cpu(s): 50.2 us, 0.2 sy, 0.0 ni, 49.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 1685.0 total, 1139.2 free, 196.3 used, 349.6 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1333.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1575 root 20 0 8792 1772 0 R 100.0 0.1 1:54.28 bash 将进程加入到 qimi-container 这个 cgroup 下
root@ubuntu2204:/sys/fs/cgroup/qimi-container# echo 1575 > cgroup.procs限制这个 cgroup 只能使用 20% cpu。
echo 2000 10000 > cpu.max表示 10000 微秒的 CPU 时间周期内,分配给本 cgroup 2000 微秒,也就是本 cgroup 管理的进程在单核 CPU 上的使用率不会超过 20%。
再次查看 CPU 占用:
top -p 1575
top - 16:56:17 up 32 min, 2 users, load average: 0.49, 0.50, 0.24
Tasks: 1 total, 1 running, 0 sleeping, 0 stopped, 0 zombie
%Cpu(s): 12.1 us, 6.1 sy, 0.0 ni, 81.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 1685.0 total, 1138.5 free, 197.0 used, 349.6 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1332.6 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1575 root 20 0 8792 1772 0 R 20.0 0.1 3:24.85 bash 可以看到 CPU 占用已经被限制到了 20%。
同理要限制 qimi-container 的内存占用上限,只需要设置 memory.max 即可。
例如下面设置内存使用上限为 1048576,即 1024*1024=1M
echo 1048576 > memory.max下图演示了 namespace 和 cgroup 在 Docker 中的作用。
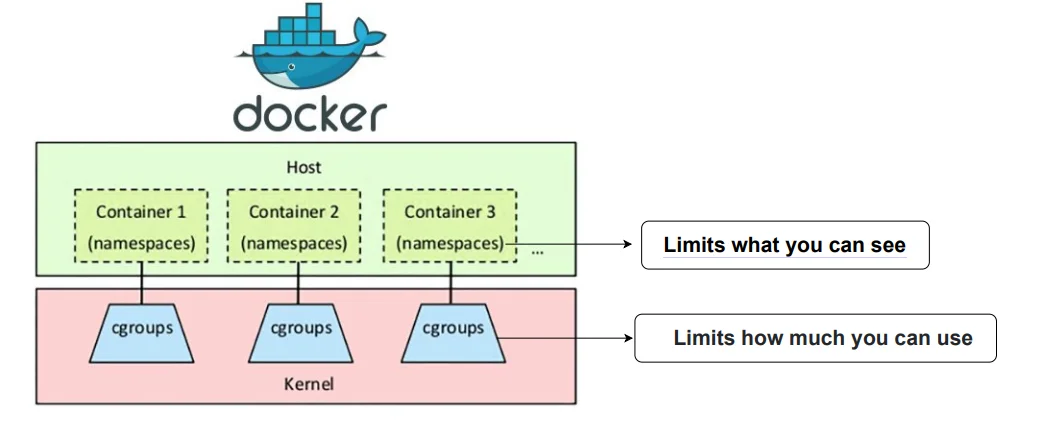
Linux 容器只能运行在Linux内核的操作系统之上,而且内核版本也有所限制。因为必须要有
Cgroups和Namespace。
Union File System
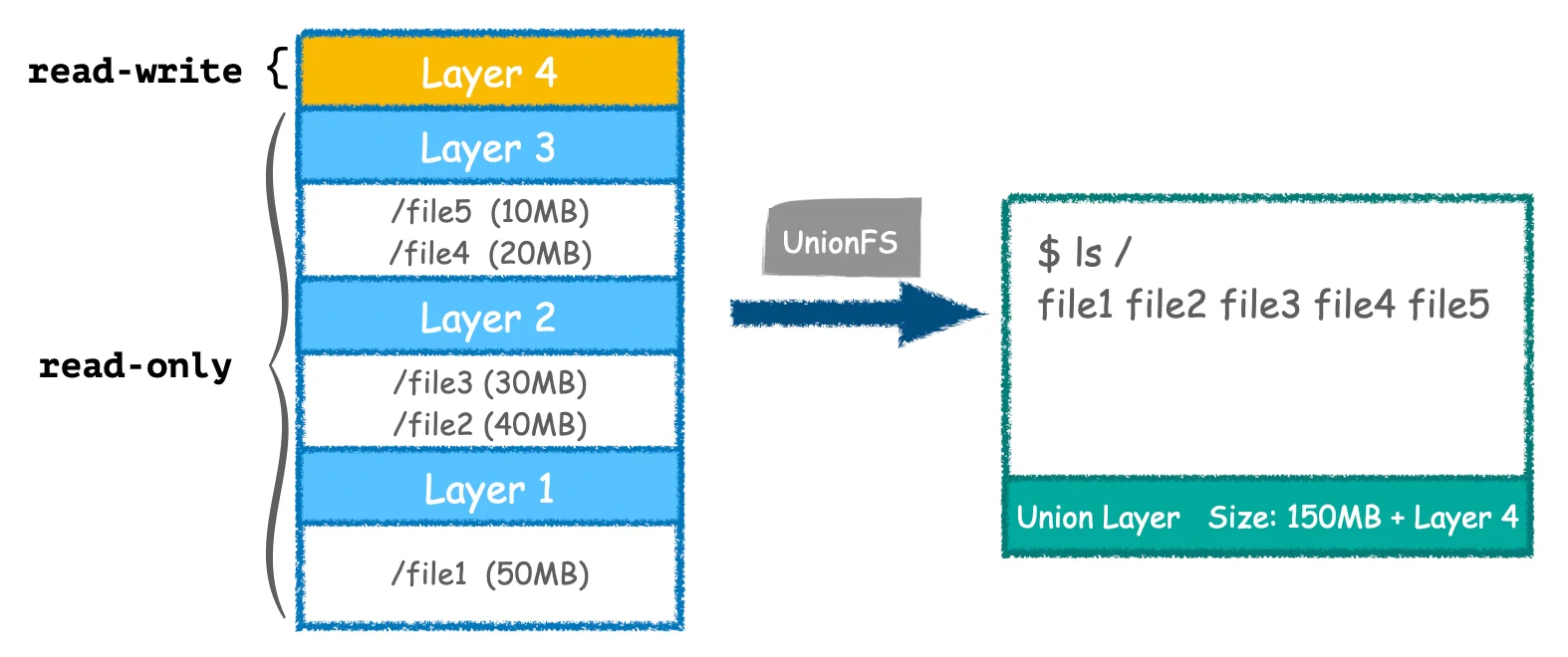
Docker 在镜像的设计中,引入了层(layer)的概念。一个镜像可能包含很多层,然后使用 UnionFS 将这多个层挂载到一个目录下面,这样这个目录就包含了完整的文件了。
联合文件系统(也称为 UnionFS)在 Docker 的整体功能中起着至关重要的作用。它是一种独特的文件系统,通过覆盖多个目录来创建虚拟的分层文件结构。UnionFS 不需要修改原始文件系统或合并目录,而是能在单个挂载点上同时挂载多个目录,同时保持它们的内容分离。这一功能对 Docker 尤为有利,因为它允许我们通过尽量减少重复和缩小容器镜像大小来管理和优化存储性能。
下面是联合文件系统的一些基本特征:
- 分层结构:UnionFS 构建了一个分层结构,由多个只读层和一个顶部可写层组成。这种结构只更新可写层,而只读层则保留原始数据,从而有效地处理更改。
- 写时复制:写入时复制(COW)机制是 UnionFS 不可或缺的功能。如果容器对现有文件进行修改,系统会在可写层创建一个文件副本,而只读层中的原始文件则保持不变。这一过程将修改限制在最上层,确保了快速和资源高效的运行。
- 资源共享:联合文件系统允许多个容器在单独运行时共享共同的基础层。这一功能可防止资源重复,节省大量存储空间。
- 快速容器初始化: 联合文件系统只需在现有的只读层上创建一个新的可写层,就能立即创建新的容器。这种快速初始化减少了重复文件操作的开销,最终提高了性能。
目前 UnionFS 有很多种实现:AUFS、Btrfs、zfs、overlay、overlay2 和 DeviceMapper等。Docker 支持不同的 UnionFS 实现,详见https://docs.docker.com/engine/storage/drivers/。
这里简单演示下
1、有以下目录和文件,其中./upper/a.txt 。
qimi@ubuntu2204:unionfs$ tree .
.
├── lower
│ └── a.txt
└── upper
└── b.txt
qimi@ubuntu2204:unionfs$ cat ./lower/a.txt
a.txt in lower
qimi@ubuntu2204:unionfs$ cat ./upper/b.txt
b.txt in upper2、新建一个空的 ./merged 目录和 ./work 目录。
qimi@ubuntu2204:unionfs$ mkdir work merged
qimi@ubuntu2204:unionfs$ tree .
.
├── lower
│ └── a.txt
├── merged
├── upper
│ └── b.txt
└── work3、执行下面的代码将 ./lower 和 ./upper 联合挂载到 ./merged 目录。
mount -t overlay -o lowerdir=./lower,upperdir=./upper,workdir=./work overlay ./merged其中,workdir 选项是必需的,用于在以原子操作方式将文件切换到覆盖目的地之前准备文件( workdir 需要与 upperdir 位于同一文件系统)。
qimi@ubuntu2204:unionfs$ sudo mount -t overlay -o lowerdir=./lower,upperdir=./upper,workdir=./work overlay ./merged
qimi@ubuntu2204:unionfs$ tree .
.
├── lower
│ └── a.txt
├── merged
│ ├── a.txt
│ └── b.txt
├── upper
│ └── b.txt
└── work
└── work [error opening dir]
5 directories, 4 files最终 ./merged/a.txt 的内容是
qimi@ubuntu2204:unionfs$ cat ./merged/a.txt
a.txt in lower在联合挂载的情况下,当我们尝试修改共享文件(或只读文件)时,它首先被复制到顶部可写分支(upperdir),该分支的优先级高于只读的较低分支(lowerdir)。然后 (它处于可写分支中时 )可以安全地修改它,并且它的新内容将在合并视图中可见,因为顶层具有更高的优先级。
qimi@ubuntu2204:unionfs$ echo edit a.txt >> ./merged/a.txt
qimi@ubuntu2204:unionfs$ tree .
.
├── lower
│ └── a.txt
├── merged
│ ├── a.txt
│ └── b.txt
├── upper
│ ├── a.txt
│ └── b.txt
└── work
└── work [error opening dir]
5 directories, 5 files
qimi@ubuntu2204:unionfs$ cat ./upper/a.txt
a.txt in lower
edit a.txt4、取消挂载
umount ./mergedDocker 中 image 和 container 都使用到了 unionfs 。
使用 docker inspect 任意镜像,在输出中找到 GraphDriver 也会看到类似的目录。
❯ docker inspect nginx
...
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/b2b05a735847b0f81596da8550de1edab4d7754c9a8b1549ef362f1a83706c37/diff:/var/lib/docker/overlay2/3342132c6106123504be239ad8794e4dbd1c565bb681fcbf6aca9ad1f1317a69/diff:/var/lib/docker/overlay2/f5d0ff8da7eb3dfd8230b7f44cb74da6f1165359c48c3377957a81027d758cce/diff:/var/lib/docker/overlay2/89c6623975e12f99efe3fd2592aa5a8dfe2465ebe83579a8285fa5d88164b2fb/diff:/var/lib/docker/overlay2/8de8f56af7bb4709466fbddb9981d6504a2b9f636c473dd63fd5b7305414b2aa/diff:/var/lib/docker/overlay2/6780f0a60fc9bf6a0e188ba3978835dd5ee0e1367d4e9dfafbe2a22181883678/diff",
"MergedDir": "/var/lib/docker/overlay2/b9fea9463e4ea8613ff23cc10beccc7e621ec8f4a7e6b1f10475adaac735eb74/merged",
"UpperDir": "/var/lib/docker/overlay2/b9fea9463e4ea8613ff23cc10beccc7e621ec8f4a7e6b1f10475adaac735eb74/diff",
"WorkDir": "/var/lib/docker/overlay2/b9fea9463e4ea8613ff23cc10beccc7e621ec8f4a7e6b1f10475adaac735eb74/work"
},
"Name": "overlay2"
},
...
关于容器中的文件系统
因为容器中的文件系统经过 Mount Namespace 隔离,所以容器中的文件是独立于主机的。
其中 Mount Namespace 修改的是容器进程对文件系统“挂载点”的认知。只有在“挂载”这个操作发生之后,进程的视图才会被改变。而在此之前,新创建的容器会直接继承宿主机的各个挂载点。
我们可以在容器进程启动之前重新挂载它的整个根目录“/”。而由于 Mount Namespace 的存在,这个挂载对宿主机不可见,所以容器进程就可以在容器里操作自己的文件而不影响主机。
虚拟机VS容器
- 虚拟化技术依赖的是物理CPU和内存,是硬件级别的;
- 而容器化技术是构建在操作系统层面的。
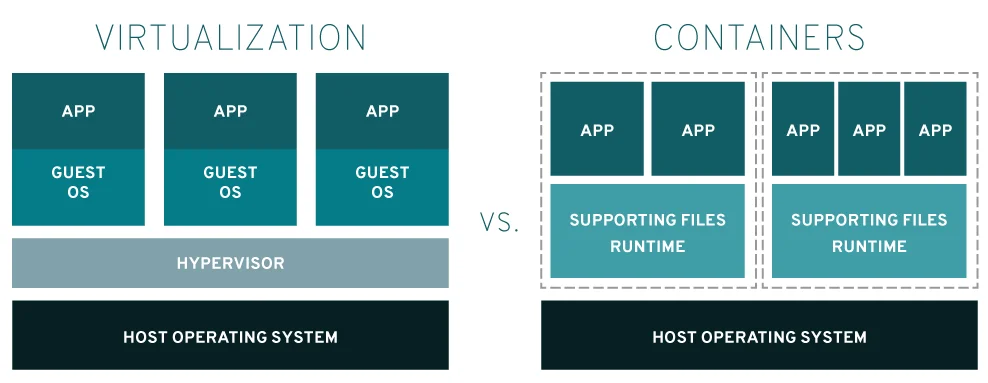
容器的劣势
基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
从技术上来讲没有银弹,关键是在隔离与性能之间做出平衡。
Docker简介
Docker是什么
Docker的英文翻译是“搬运工”的意思,它的Logo是个鲸鱼,Docker 最初是 dotCloud 公司创始人 Solomon Hykes 在法国期间发起的一个公司内部项目,它是基于 dotCloud 公司多年云服务技术的一次革新,并于 2013 年 3 月以 Apache 2.0 授权协议开源,主要项目代码在 GitHub (moby)上进行维护。
Docker 项目后来还加入了 Linux 基金会,并成立推动 开放容器联盟(OCI)。
2013年底它的公司名(dotCloud)也改成了Docker Inc。
2019年11月13日,Mirantis 收购了 Docker (软件)企业技术平台和所有相关的 IP: Docker Enterprise Engine, Docker Trusted Registry, Docker Unified Control Plane 和 Docker CLI。
“Docker” 一词指代了多个概念,包括开源社区项目、开源项目使用的工具、主导支持此类项目的公司 Docker Inc.,以及该公司官方支持的工具。
目前,我们通常会在本地使用 docker 快速搭建开发、测试环境,而在企业中会使用 k8s 实现容器编排。
Docker 架构

- Docker Damon:dockerd,用来监听 Docker API 的请求和管理 Docker 对象,比如镜像、容器、网络和 Volume。
- Docker Client:docker,docker client 是我们和 Docker 进行交互的最主要的方式方法,比如我们可以通过 docker run 命令来运行一个容器,然后我们的这个 client 会把命令发送给上面的 Dockerd,让他来做真正事情。
- Docker Registry:用来存储 Docker 镜像的仓库,Docker Hub 是 Docker 官方提供的一个公共仓库,而且 Docker 默认也是从 Docker Hub 上查找镜像的,当然你也可以很方便的运行一个私有仓库,当我们使用 docker pull 或者 docker run 命令时,就会从我们配置的 Docker 镜像仓库中去拉取镜像,使用 docker push 命令时,会将我们构建的镜像推送到对应的镜像仓库中。
- Images:镜像,镜像是一个只读模板,带有创建 Docker 容器的说明,一般来说的,镜像会基于另外的一些基础镜像并加上一些额外的自定义功能。比如,你可以构建一个基于 CentOS 的镜像,然后在这个基础镜像上面安装一个 Nginx 服务器,这样就可以构成一个属于我们自己的镜像了。
- Containers:容器,容器是一个镜像的可运行的实例,可以使用 Docker REST API 或者 CLI 来操作容器,容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间。因此容器可以拥有自己的 root 文件系统、网络配置、进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。
- 底层技术支持:Namespaces(做隔离)、CGroups(做资源限制)、UnionFS(镜像和容器的分层)等。
Docker 底层架构
Docker Daemon 将镜像准备成一个 OCI (Open Container Image)包,并调用 containerd 的 API 来启动 OCI 包。然后通过 containerd-shim 去调用 runc 来启动容器的,runc 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd。而containerd 通过shim 这一层去兼容不同的容器运行时。
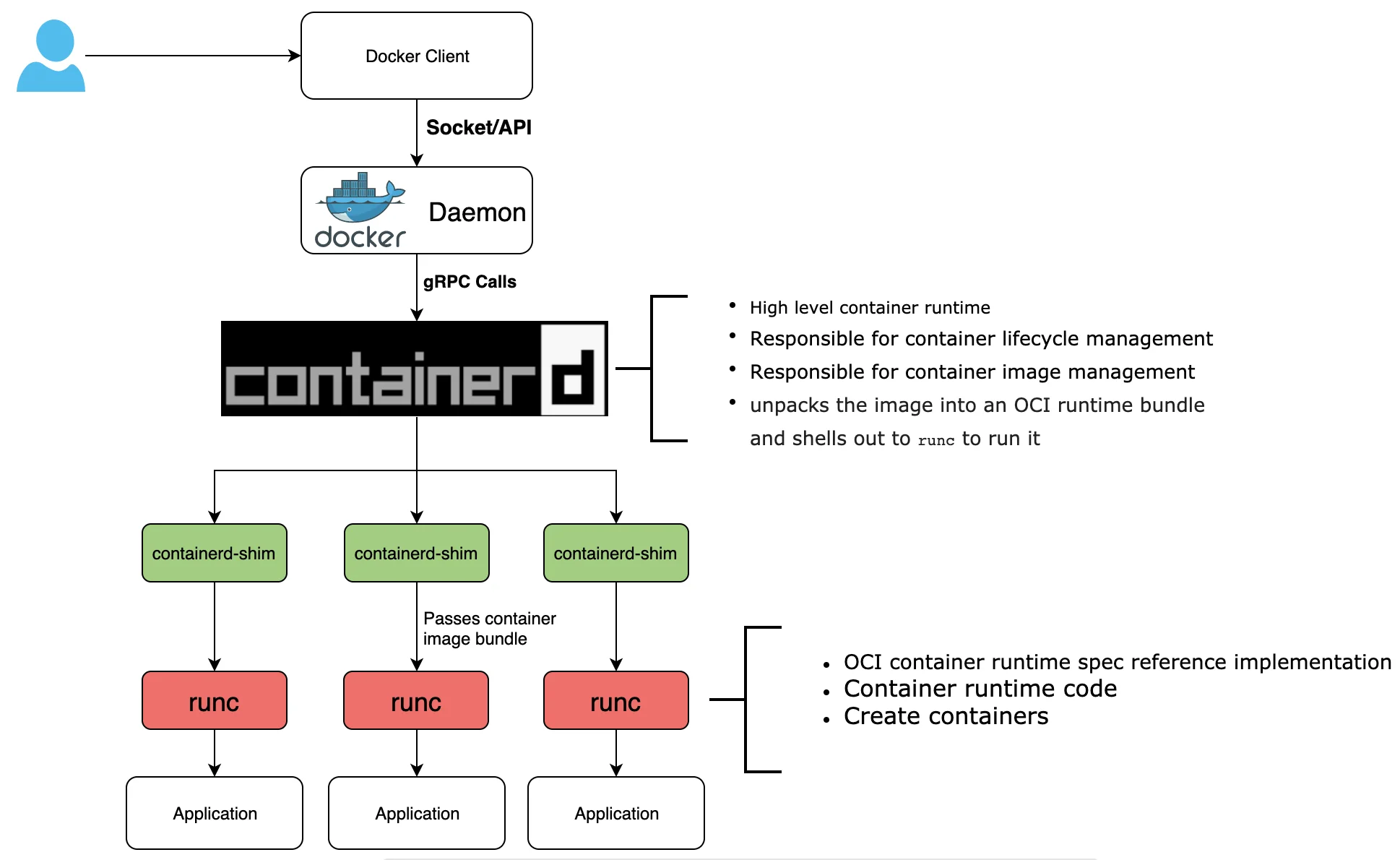
- containerd 是一个容器运行时,它可以管理从镜像传输/存储到容器执行、监控和联网的整个容器生命周期。
- container-shim 处理无头容器,因为一旦 runc 初始化了容器,它就会退出,将容器交给 container-shim,后者充当中间人。
- runc 是遵守 OCI 规范的轻量级通用运行时容器。
- grpc 用于 containerd 和 docker-engine 之间的通信。
Docker安装
官方相关文档:
Windows : https://docs.docker.com/desktop/install/windows-install/
Mac :https://docs.docker.com/desktop/install/mac-install/
Linux : https://docs.docker.com/desktop/install/linux-install/
Windows
Docker Desktop 支持 Hyper-V 和 WSL
直接下载Docker Desktop可执行文件,双击安装。
Mac
方法一:使用 Homebrew 安装
Homebrew 的 Cask 已经支持 Docker Desktop for Mac,因此可以很方便的使用 Homebrew Cask 来进行安装:
❯ brew install --cask docker方法二:下载 Docker Desktop
下载可执行文件,双击安装。
镜像
容器镜像(Container Image)是容器的模板,用于创建和运行容器。它包含了一个应用程序和其依赖关系、运行时所需的程序、库、资源、配置文件等。容器镜像可以被看作是一个特殊的文件系统,其内容在构建之后不会改变。
Docker 项目通过“容器镜像”,解决了应用打包这个根本性难题。
PaaS 之所以能够帮助用户大规模部署应用到集群里,是因为它提供了一套应用打包的功能。可偏偏就是这个打包功能,却成了 PaaS 日后不断遭到用户诟病的一个“软肋”。
出现这个问题的根本原因是,一旦用上了 PaaS,用户就必须为每种语言、每种框架,甚至每个版本的应用维护一个打好的包。这个打包过程,没有任何章法可循,更麻烦的是,明明在本地运行得好好的应用,却需要做很多修改和配置工作才能在 PaaS 里运行起来。而这些修改和配置,并没有什么经验可以借鉴,所以就有一定的门槛。
题外话,越是简单易用的技术越容易流行起来。
而 Docker 镜像解决的,恰恰就是打包这个根本性的问题。 所谓 Docker 镜像,其实就是一个压缩包。但是这个压缩包里的内容,比 PaaS 的应用可执行文件 + 启停脚本的组合就要丰富多了。实际上,大多数 Docker 镜像是直接由一个完整操作系统的所有文件和目录构成的,所以这个压缩包里的内容跟你本地开发和测试环境用的操作系统是完全一样的。你不再需要考虑最终执行的环境了,因为你把你的应用程序和应用程序的执行环境都打包到一个"压缩包"里了。
这就是 Docker 镜像最厉害的地方:只要有这个"压缩包"在手,你就可以使用某种技术创建一个“沙盒”,在“沙盒”中解压这个压缩包,然后就可以运行你的程序了。
在这个过程中,你完全不需要进行任何配置或者修改,因为这个压缩包赋予了你一种极其宝贵的能力:本地环境和云端环境的高度一致!
这,正是 Docker 镜像的精髓。
镜像仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。
一个 Docker Registry 中可以包含多个 仓库(Repository);每个仓库可以包含多个 标签(Tag);每个标签对应一个镜像。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
以 Ubuntu 镜像 为例,ubuntu 是仓库的名字,其内包含有不同的版本标签,如,16.04, 18.04。我们可以通过 ubuntu:16.04,或者 ubuntu:18.04 来具体指定所需哪个版本的镜像。如果忽略了标签,比如 ubuntu,那将视为 ubuntu:latest。
仓库名通常是以 两段式路径 形式出现,比如 q1mi/gin_demo,前面是用户名,后面是对应的软件名。
Docker Registry
Docker Registry 公开服务是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
最常使用的 Registry 公开服务是官方的 Docker Hub,这也是默认的 Registry,并拥有大量的高质量的 官方镜像。除此以外,还有 Red Hat 的 Quay.io;Google 的 Google Container Registry;代码托管平台 GitHub 推出的 ghcr.io。
由于某些原因,在国内访问这些服务可能会比较慢。国内的一些云服务商提供了针对 Docker Hub 的镜像服务(Registry Mirror),这些镜像服务被称为 加速器。
补充说明:国内的 docker 镜像 mirror 站在 2024.06 后都陆续下架了。
{ "builder": { "gc": { "defaultKeepStorage": "20GB", "enabled": true } }, "experimental": false, "registry-mirrors": [ "https://docker.m.daocloud.io" ] }
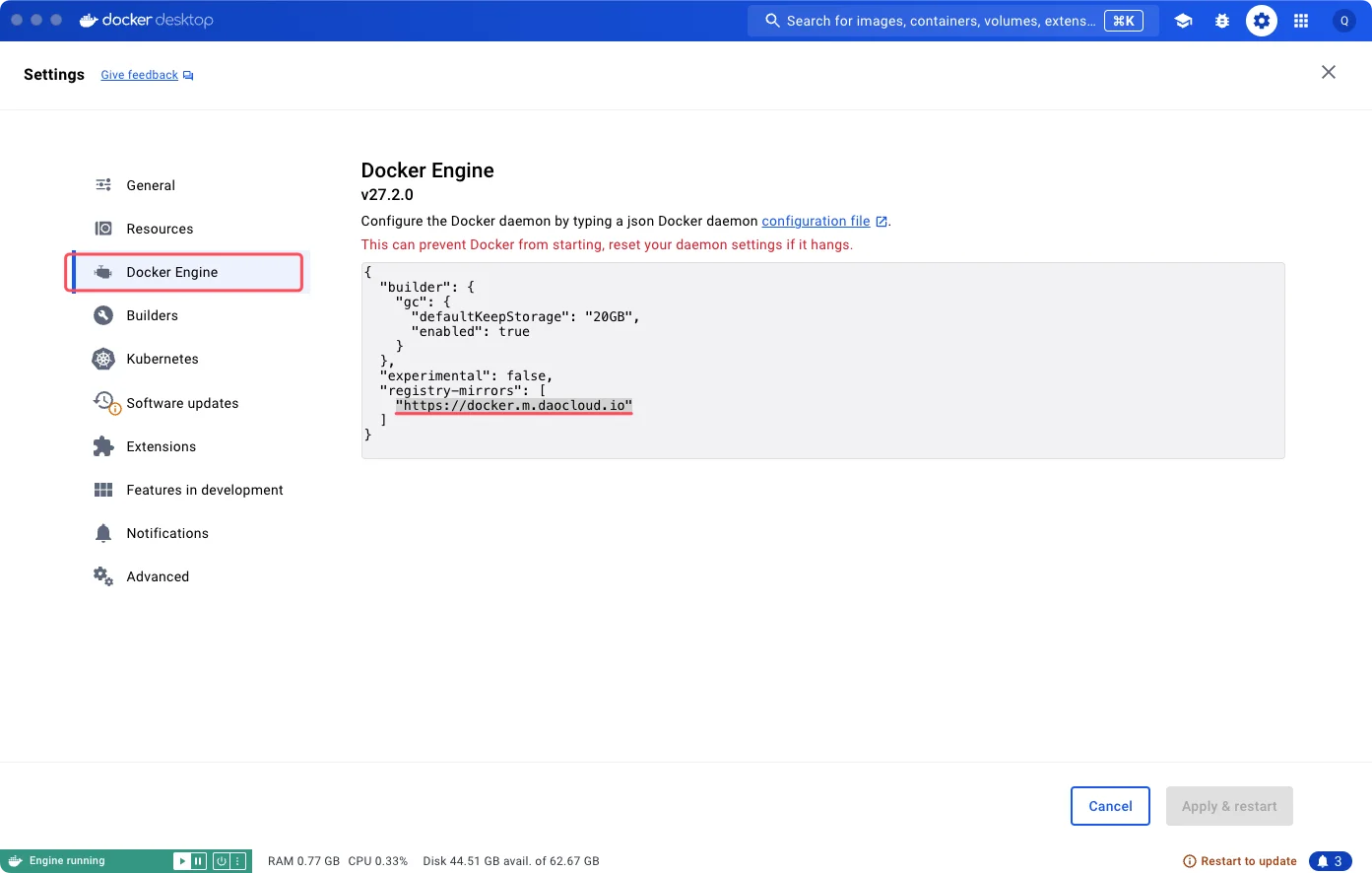
此外,国内也有一些云服务商提供类似于 Docker Hub 的公开服务。
私有 Registry
除了使用公开服务外,用户还可以在本地搭建私有 Docker Registry。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。
开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
除了官方的 Docker Registry 外,还有第三方软件实现了 Docker Registry API,甚至提供了用户界面以及一些高级功能。比如,Harbor 等。
镜像操作
搜索镜像
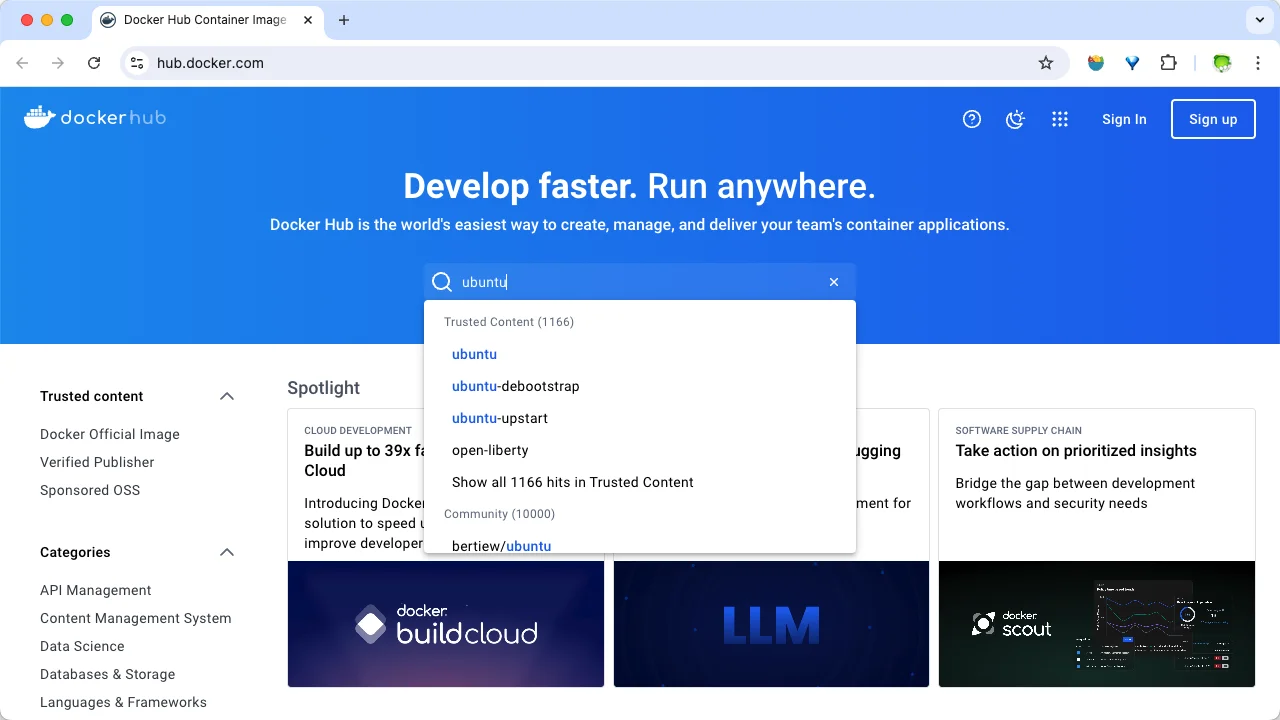
方法一:打开 https://hub.docker.com/ ,在搜索框搜索。
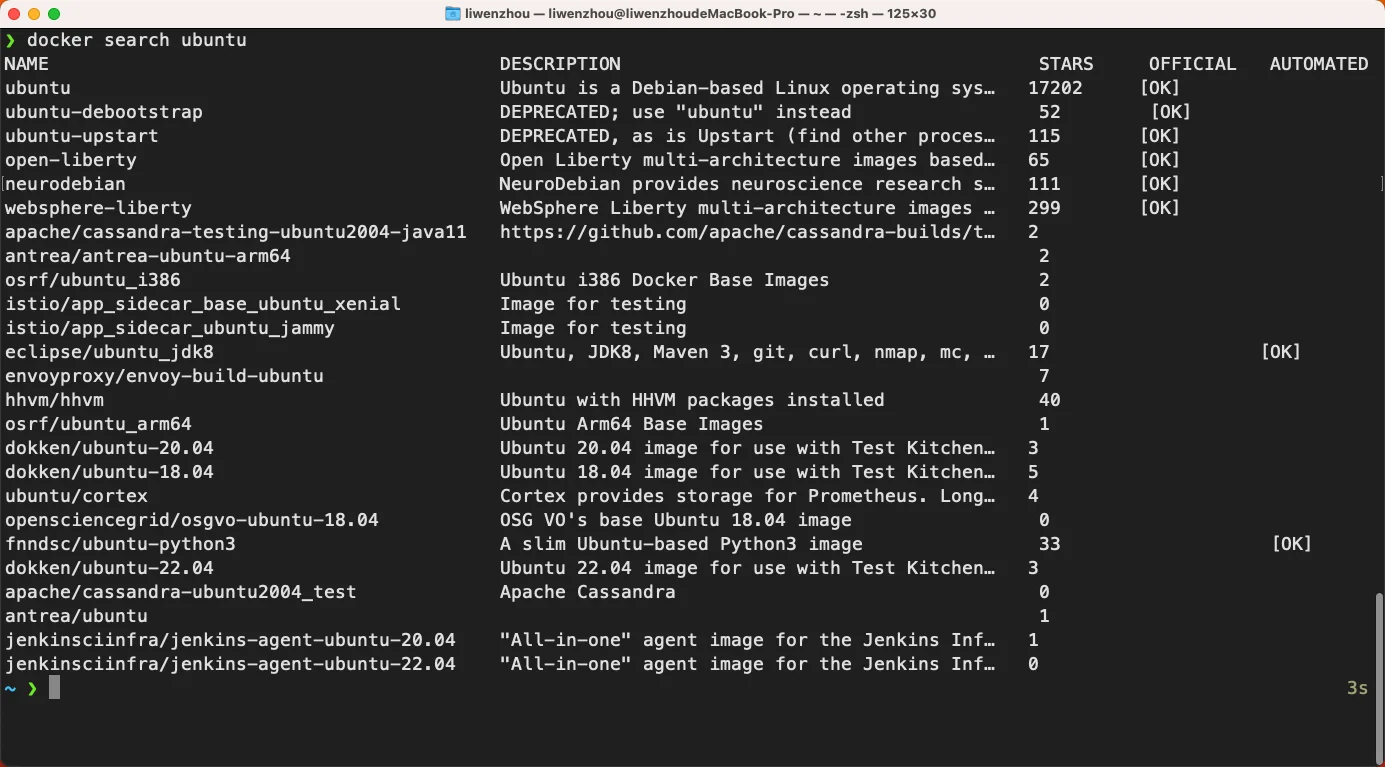
方法二:命令行执行docker search xxx
比如:
获取镜像
从 Docker 镜像仓库获取镜像的命令是 docker pull。其命令格式为:
❯ docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签]- Docker 镜像仓库地址:地址的格式一般是 <域名/IP>[:端口号],默认地址是 Docker Hub。
- 仓库名:这里的仓库名是两段式名称,即 <用户名>/<软件名>。对于 Docker Hub,如果不给出用户名,则默认为 library,也就是官方镜像。
- 比如:
❯ docker pull ubuntu:18.04
18.04: Pulling from library/ubuntu
92dc2a97ff99: Pull complete
be13a9d27eb8: Pull complete
c8299583700a: Pull complete
Digest: sha256:4bc3ae6596938cb0d9e5ac51a1152ec9dcac2a1c50829c74abd9c4361e321b26
Status: Downloaded newer image for ubuntu:18.04
docker.io/library/ubuntu:18.04上面的命令中没有给出 Docker 镜像仓库地址,因此将会从 Docker Hub (docker.io)获取镜像。而镜像名称是 ubuntu:18.04,因此将会获取官方镜像 library/ubuntu 仓库中标签为 18.04 的镜像。docker pull 命令的输出结果最后一行给出了镜像的完整名称,即: docker.io/library/ubuntu:18.04。
从下载过程中可以看到我们之前提及的分层存储的概念,镜像是由多层存储所构成。下载也是一层层的去下载,并非单一文件。下载过程中给出了每一层的 ID 的前 12 位。并且下载结束后,给出该镜像完整的 sha256 的摘要,以确保下载一致性。
在使用上面命令的时候,你可能会发现,你所看到的层 ID 以及 sha256 的摘要和这里的不一样。这是因为官方镜像是一直在维护的,有任何新的 bug,或者版本更新,都会进行修复再以原来的标签发布,这样可以确保任何使用这个标签的用户可以获得更安全、更稳定的镜像。
运行
有了镜像后,我们就能够以这个镜像为基础启动并运行一个容器。以上面的 ubuntu:18.04 为例,如果我们打算启动里面的 bash 并且进行交互式操作的话,可以执行下面的命令。
❯ docker run -it --rm ubuntu:18.04 bash
root@03c9df38f34f:/# cat /etc/os-release
NAME="Ubuntu"
VERSION="18.04.6 LTS (Bionic Beaver)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 18.04.6 LTS"
VERSION_ID="18.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic
root@03c9df38f34f:/# exit
exitdocker run 就是运行容器的命令,具体格式我们会在 容器 一节进行详细讲解,我们这里简要的说明一下上面用到的参数。
-it:这是两个参数,一个是-i:交互式操作,一个是-t终端。我们这里打算进入bash执行一些命令并查看返回结果,因此我们需要交互式终端。--rm:这个参数是说容器退出后随之将其删除。默认情况下,为了排障需求,退出的容器并不会立即删除,除非手动docker rm。我们这里只是随便执行个命令,看看结果,不需要排障和保留结果,因此使用--rm可以避免浪费空间。ubuntu:18.04:这是指用ubuntu:18.04镜像为基础来启动容器。bash:放在镜像名后的是 命令,这里我们希望进入容器后有个交互式 Shell,因此用的是bash。
进入容器后,我们可以在 Shell 下操作,执行任何所需的命令。这里,我们执行了 cat /etc/os-release,这是 Linux 常用的查看当前系统版本的命令,从返回的结果可以看到容器内是 Ubuntu 18.04.1 LTS 系统。
最后我们通过 exit 退出了这个容器。
列出镜像
要想列出已经下载到本地的镜像,可以使用 docker images 命令。
❯ docker images --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Aliases:
docker image ls, docker image list, docker images
Options:
-a, --all Show all images (default hides intermediate images)
--digests Show digests
-f, --filter filter Filter output based on conditions provided
--format string Format output using a custom template:
'table': Print output in table format with column headers (default)
'table TEMPLATE': Print output in table format using the given Go template
'json': Print in JSON format
'TEMPLATE': Print output using the given Go template.
Refer to https://docs.docker.com/go/formatting/ for more information about formatting output
with templates
--no-trunc Don't truncate output
-q, --quiet Only show image IDs例如:
列表包含了仓库名、标签、镜像 ID、创建时间以及所占用的空间。镜像 ID 则是镜像的唯一标识,一个镜像可以对应多个标签。
❯ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
danielqsj/kafka-exporter latest 4a057b79787a 6 weeks ago 21.4MB
grafana/grafana-oss latest 75242a870669 3 months ago 432MB
grafana/grafana-enterprise latest 7df8242e5804 3 months ago 439MB
prom/prometheus latest c695686d2a39 3 months ago 266MB
gin_demo latest c94ffd96de6b 5 months ago 16MB
<none> <none> 5a27ab9d38b9 5 months ago 16MB
kong latest 84509ccc6beb 6 months ago 285MB
canal/canal-server latest eb67fb66f50b 10 months ago 1.19GB
docker.elastic.co/kibana/kibana 8.9.1 f5ec32117c7f 12 months ago 945MB
docker.elastic.co/elasticsearch/elasticsearch 8.9.1 180d266daa33 12 months ago 754MB
mysql latest 54fea0bc79f9 12 months ago 599MB
provectuslabs/kafka-ui latest cf4ebffbd785 13 months ago 260MB
ubuntu 18.04 d1a528908992 14 months ago 56.7MB
postgres 9.5 c5b690c13b21 3 years ago 190MB
redis 5.0.7 bc29ea3d51e5 4 years ago 92.5MB镜像体积
如果仔细观察,会注意到,这里标识的所占用空间和在 Docker Hub 上看到的镜像大小不同。比如,ubuntu:18.04 镜像大小,在这里是 63.3MB,但是在 Docker Hub 显示的却是 25.47 MB。这是因为 Docker Hub 中显示的体积是压缩后的体积。在镜像下载和上传过程中镜像是保持着压缩状态的,因此 Docker Hub 所显示的大小是网络传输中更关心的流量大小。而 docker image ls 显示的是镜像下载到本地后,展开的大小,准确说,是展开后的各层所占空间的总和,因为镜像到本地后,查看空间的时候,更关心的是本地磁盘空间占用的大小。
另外一个需要注意的问题是,docker image ls 列表中的镜像体积总和并非是所有镜像实际硬盘消耗。由于 Docker 镜像是多层存储结构,并且可以继承、复用,因此不同镜像可能会因为使用相同的基础镜像,从而拥有共同的层。由于 Docker 使用 Union FS,相同的层只需要保存一份即可,因此实际镜像硬盘占用空间很可能要比这个列表镜像大小的总和要小的多。
你可以通过 docker system df 命令来便捷的查看镜像、容器、数据卷所占用的空间。
❯ docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 19 14 6.643GB 1.396GB (21%)
Containers 17 2 2.698GB 2.698GB (100%)
Local Volumes 15 11 1.759GB 0B (0%)
Build Cache 17 0 638.7MB 638.7MB悬空镜像
上面的镜像列表中,还可以看到一个特殊的镜像,这个镜像既没有仓库名,也没有标签,均为 <none>。
<none> <none> 5a27ab9d38b9 5 months ago 16MB这个镜像原本是有镜像名和标签的(gin_demo:latest),docker build 构建了新版本后,镜像名被转移到了新的镜像身上,而旧的镜像上的这个名称则被取消,从而成为了 <none>。 docker pull 拉取镜像时也可能会出现这种情况,旧镜像名称被取消,从而出现仓库名、标签均为 <none> 的镜像。这类无标签镜像也被称为 悬空镜像(dangling image) ,可以用下面的命令专门显示这类镜像:
❯ docker images -f dangling=true
REPOSITORY TAG IMAGE ID CREATED SIZE
<none> <none> 5a27ab9d38b9 5 months ago 16MB一般来说,虚悬镜像已经失去了存在的价值,是可以随意删除的。
删除镜像
如果要删除本地的镜像,可以使用docker image rm命令,其格式为:
❯ docker image rm [选项] <镜像1> [<镜像2> ...]或者
❯ docker rmi 镜像名其中,删除命令中的<镜像> 可以是 镜像短 ID、镜像长 ID、镜像名 或者 镜像摘要。我们可以用镜像的完整 ID,也称为 长 ID,来删除镜像。使用脚本的时候可能会用长 ID,但是人工输入就太麻烦了,所以更多的时候是用 短 ID 来删除镜像。docker image ls默认列出的就已经是短 ID 了,一般取前3个字符以上,只要足够区分于别的镜像就可以了。
发布镜像
可以将自己制作的镜像发布到 Registry,比如 docker hub或者公司内部的 Registry。
格式:
❯ docker image push [OPTIONS] NAME[:TAG]这里以发布到 docker hub 为例。首先,去 hub.docker.com 注册一个账户。然后,用下面的命令登录。
❯ docker login接着,为本地的 image 标注用户名和版本。
❯ docker image tag gin_demo:latest q1mi/gin_demo:latest最后,发布 image 文件。
❯ docker image push q1mi/gin_demo:latest
The push refers to repository [docker.io/q1mi/gin_demo]
2e4c79edb12d: Pushed
c3d82e1af266: Pushed
d80e0208345a: Mounted from library/alpine
latest: digest: sha256:04b20cc741be287f940a3f018e0cbb90fe25fd8b23c2736b76fb8b3f1b41f24e size: 945发布成功以后,登录 hub.docker.com,就可以看到已经发布的 image 文件
例如:我上面发布的 gin_demo。你可以通过以下命令拉取我的镜像。
❯ docker pull q1mi/gin_demo镜像相关命令
❯ docker image --help
Usage: docker image COMMAND
Manage images
Commands:
build Build an image from a Dockerfile
history Show the history of an image
import Import the contents from a tarball to create a filesystem image
inspect Display detailed information on one or more images
load Load an image from a tar archive or STDIN
ls List images
prune Remove unused images
pull Download an image from a registry
push Upload an image to a registry
rm Remove one or more images
save Save one or more images to a tar archive (streamed to STDOUT by default)
tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE容器
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程在属于自己的独立 命名空间 中运行。所以容器可以拥有自己的 root 文件系统、网络配置、进程空间、用户 ID 空间等。容器内的进程是运行在一个隔离的环境里,使用起来就好像是在一个独立于宿主的系统下操作一样。
在前面的章节讲过镜像使用的是分层存储,容器也是如此。每一个容器运行时,是以镜像为基础层,在其上创建一个当前容器的存储层,我们可以称这个为容器运行时读写而准备的存储层为容器存储层。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 数据卷(Volume)、或绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失。
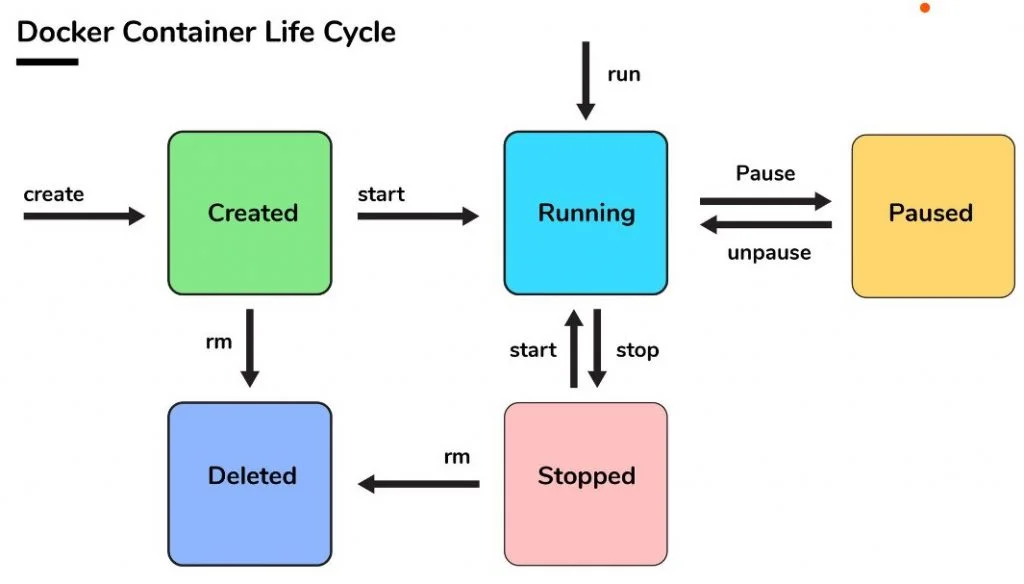
容器生命周期
启动容器
启动容器有两种方式,一种是基于镜像新建一个容器并启动,另外一个是将在终止状态(exited)的容器重新启动。
新建并启动
新建并启动容器的命令为 docker run。
比如:利用我们先前拉取的ubuntu:18.04镜像启动一个容器,并启动一个 bash 终端,允许用户进行交互。
❯ docker run -i -t ubuntu:18.04 /bin/bash
root@8c75c13b1711:/# pwd
/
root@8c75c13b1711:/# ls
bin boot dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var其中:
-t选项让 Docker 分配一个伪终端(pseudo-tty)并绑定到容器的标准输入上-i则让容器的标准输入保持打开。
我们也可以启动并运行一个nginx容器,因为我们本地没有事先拉取nginx镜像,所以会先拉取镜像。
❯ docker run nginx
Unable to find image 'nginx:latest' locally
latest: Pulling from library/nginx
aa6fbc30c84e: Pull complete
168914bf900e: Pull complete
13b3fceec7e4: Pull complete
f9fa58e3da0f: Pull complete
00146e6e5257: Pull complete
50e4fc85b5d4: Pull complete
a408e3af440a: Pull complete
Digest: sha256:98f8ec75657d21b924fe4f69b6b9bff2f6550ea48838af479d8894a852000e40
Status: Downloaded newer image for nginx:latest
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Sourcing /docker-entrypoint.d/15-local-resolvers.envsh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2024/08/15 13:11:43 [notice] 1#1: using the "epoll" event method
2024/08/15 13:11:43 [notice] 1#1: nginx/1.27.0
2024/08/15 13:11:43 [notice] 1#1: built by gcc 12.2.0 (Debian 12.2.0-14)
2024/08/15 13:11:43 [notice] 1#1: OS: Linux 6.3.13-linuxkit
2024/08/15 13:11:43 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2024/08/15 13:11:43 [notice] 1#1: start worker processes
2024/08/15 13:11:43 [notice] 1#1: start worker process 30
2024/08/15 13:11:43 [notice] 1#1: start worker process 31
2024/08/15 13:11:43 [notice] 1#1: start worker process 32
2024/08/15 13:11:43 [notice] 1#1: start worker process 33当利用 docker run 来创建容器时,Docker 在后台运行的标准操作包括:
- 检查本地是否存在指定的镜像,不存在就从 registry 下载
- 利用镜像创建并启动一个容器
- 分配一个文件系统,并在只读的镜像层外面挂载一层可读写层
- 从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去
- 从地址池配置一个 ip 地址给容器
- 执行用户指定的应用程序
- 执行完毕后容器被终止
启动已终止容器
可以利用 docker container start 命令,直接将一个已经终止(exited)的容器启动运行。
容器的核心为所执行的应用程序,所需要的资源都是应用程序运行所必需的。除此之外,并没有其它的资源。可以在伪终端中利用 ps 或 top 来查看进程信息。
例如,启动我本地之前的redis容器。
❯ docker container start redis前台运行/后台运行
启动容器时,默认情况下容器在前台运行。如果希望在后台运行容器,可以使用 --detach (或 -d )标志。这将在不占用终端窗口的情况下启动容器。
下面举两个例子来说明一下。
如果不使用 -d 参数运行容器。
❯ docker run ubuntu:18.04 /bin/sh -c "while true; do echo hello world; sleep 1; done"
hello world
hello world
hello world容器会把输出的结果 (STDOUT) 打印到宿主机上面
如果使用了 -d 参数运行容器。
❯ docker run -d ubuntu:18.04 /bin/sh -c "while true; do echo hello world; sleep 1; done"
27c037b944b3e5bab6be7854425de3f8db251f867af03b34499beed6fd25207b此时容器会在后台运行并不会把输出的结果 (STDOUT) 打印到宿主机上面(输出结果可以用 docker logs 查看)。
注: 容器是否会长久运行,是和
docker run指定的命令有关,和-d参数无关。
使用 -d 参数启动后会返回一个唯一的 id,也可以通过 docker container ls 命令来查看容器信息。
❯ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
27c037b944b3 ubuntu:18.04 "/bin/sh -c 'while t…" 2 minutes ago Up 2 minutes elegant_mestorf要获取容器的输出信息,可以通过 docker container logs 命令。
❯ docker container logs 27c037b944b3
hello world
hello world
hello world
hello world
hello world终止容器
可以使用 docker container stop 来终止一个运行中的容器。
此外,当 Docker 容器中指定的应用终结时,容器也自动终止。
例如对于上一章节中只启动了一个终端的容器,用户通过 exit 命令或 Ctrl+d 来退出终端时,所创建的容器立刻终止。
终止状态的容器可以用 docker container ls -a 命令看到。例如
❯ docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
27c037b944b3 ubuntu:18.04 "/bin/sh -c 'while t…" 5 minutes ago Exited (137) About a minute ago elegant_mestorf
5fb52bbca61f nginx "/docker-entrypoint.…" 10 minutes ago Exited (0) 9 minutes ago fervent_bas处于终止状态的容器,可以通过 docker container start 命令来重新启动。
重启容器
docker container restart 命令会将一个运行态的容器终止,然后再重新启动它。
进入容器
在使用 -d 参数时,容器启动后会进入后台。
某些时候需要进入容器进行操作,包括使用 docker attach 命令或 docker exec 命令,推荐大家使用 docker exec 命令,原因会在下面说明。
attach 命令
下面示例演示如何使用 docker attach 命令。
❯ docker run -d -it ubuntu:18.04
752bdea607ada42d61029c7a3fc12b73981cf1b8961b20a3406e1d2625d63f6b
❯ docker attach 752bdea607ada42d61029c7a3fc12b73981cf1b8961b20a3406e1d2625d63f6b
root@752bdea607ad:/# ls
bin boot dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
root@752bdea607ad:/# exit
exit注意: 如果从这个 stdin 中 exit,会导致容器的停止。
exec 命令
-i -t 参数
docker exec 后边可以跟多个参数,这里主要说明 -i -t 参数。
只用 -i 参数时,由于没有分配伪终端,界面没有我们熟悉的 Linux 命令提示符,但命令执行结果仍然可以返回。
当 -i -t 参数一起使用时,则可以看到我们熟悉的 Linux 命令提示符。
❯ docker run -d -it ubuntu:18.04
a888d61df1693596ed6bd5b5ed883eedf47d02b3e872a993a859792c306e8bdb
❯ docker exec -it a888 /bin/bash
root@a888d61df169:/# ls
bin boot dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
root@a888d61df169:/# exit
exit如果从这个 stdin 中 exit,不会导致容器的停止。这就是为什么推荐大家使用 docker exec 的原因。
更多参数说明请使用 docker exec --help 查看。
导出和导入容器
导出容器到tar文件
如果要导出本地某个容器,可以使用 docker export 命令。
❯ docker export a888 > ubuntu1804.tar这样将导出容器快照到本地文件。
导入
可以使用 docker import 从容器快照文件中再导入为镜像,例如:
❯ docker import ubuntu1804.tar test/ubuntu:v1.0
sha256:eadbd74e1017d796c7dbba970fbc41702ccbe5372473fef755c6b92391057b85此外,也可以通过指定 URL 或者某个目录来导入,例如
❯ docker import http://example.com/exampleimage.tar example/imagerepo注:我们既可以使用*
*docker load*来导入镜像存储文件到本地镜像库,也可以使用*docker import**来导入一个容器快照到本地镜像库。这两者的区别在于容器快照文件将丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态),而镜像存储文件将保存完整记录,体积也要大。此外,从容器快照文件导入时可以重新指定标签等元数据信息。
删除容器
删除容器
可以使用 docker container rm 来删除一个处于终止状态的容器。例如
❯ docker container rm 752bdea6如果要删除一个运行中的容器,可以添加 -f 参数。Docker 会发送 SIGKILL 信号给容器。
❯ docker container rm -f a888d61df169
a888d61df169清理所有处于终止状态的容器
用 docker container ls -a 命令可以查看所有已经创建的包括终止状态的容器,如果数量太多要一个个删除可能会很麻烦,用下面的命令可以清理掉所有处于终止状态的容器。
❯ docker container prunedocker 容器相关命令
❯ docker container --help
Usage: docker container COMMAND
Manage containers
Commands:
attach Attach local standard input, output, and error streams to a running container
commit Create a new image from a container's changes
cp Copy files/folders between a container and the local filesystem
create Create a new container
diff Inspect changes to files or directories on a container's filesystem
exec Execute a command in a running container
export Export a container's filesystem as a tar archive
inspect Display detailed information on one or more containers
kill Kill one or more running containers
logs Fetch the logs of a container
ls List containers
pause Pause all processes within one or more containers
port List port mappings or a specific mapping for the container
prune Remove all stopped containers
rename Rename a container
restart Restart one or more containers
rm Remove one or more containers
run Create and run a new container from an image
start Start one or more stopped containers
stats Display a live stream of container(s) resource usage statistics
stop Stop one or more running containers
top Display the running processes of a container
unpause Unpause all processes within one or more containers
update Update configuration of one or more containers
wait Block until one or more containers stop, then print their exit codes
Run 'docker container COMMAND --help' for more information on a command.docker commit 定制镜像
镜像是容器的基础,每次执行docker run的时候都会指定哪个镜像作为容器运行的基础。在之前的例子中,我们所使用的都是来自于 Docker Hub 的镜像。直接使用这些镜像是可以满足一定的需求,而当这些镜像无法直接满足需求时,我们就需要定制这些镜像。
镜像是多层存储,每一层是在前一层的基础上进行的修改;而容器同样也是多层存储,是在以镜像为基础层,在其基础上加一层作为容器运行时的存储层。
现在让我们以定制一个 Web 服务器为例子,来讲解镜像是如何构建的。
❯ docker run --name webserver -d -p 80:80 nginx这条命令会用 nginx 镜像启动一个容器,命名为 webserver,并且映射了 80 端口,这样我们可以用浏览器去访问这个 nginx 服务器。
如果是在 Linux 本机运行的 Docker,或者如果使用的是 Docker for Mac、Docker for Windows,那么可以直接访问:http://localhost;
如果使用的是在虚拟机、云服务器上安装的 Docker,则需要将 localhost 换为虚拟机地址或者实际云服务器地址。
直接用浏览器访问的话,我们会看到默认的 Nginx 欢迎页面。
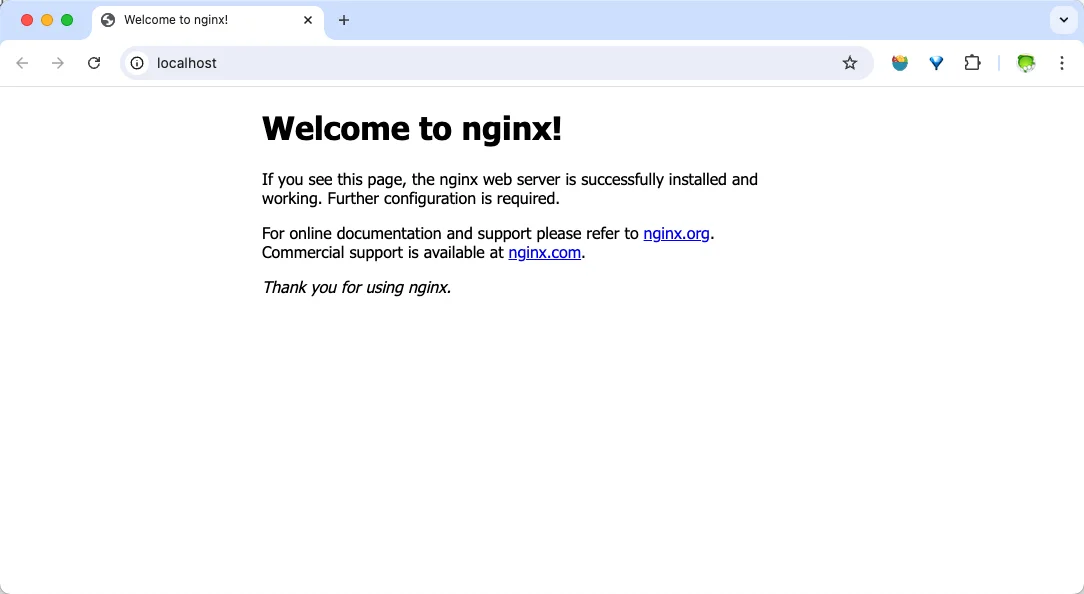
现在,假设我们不太喜欢这个古板的欢迎页面,我们希望修改下这个页面,我们可以使用 docker exec命令进入容器,修改其内容。
❯ docker exec -it webserver bash
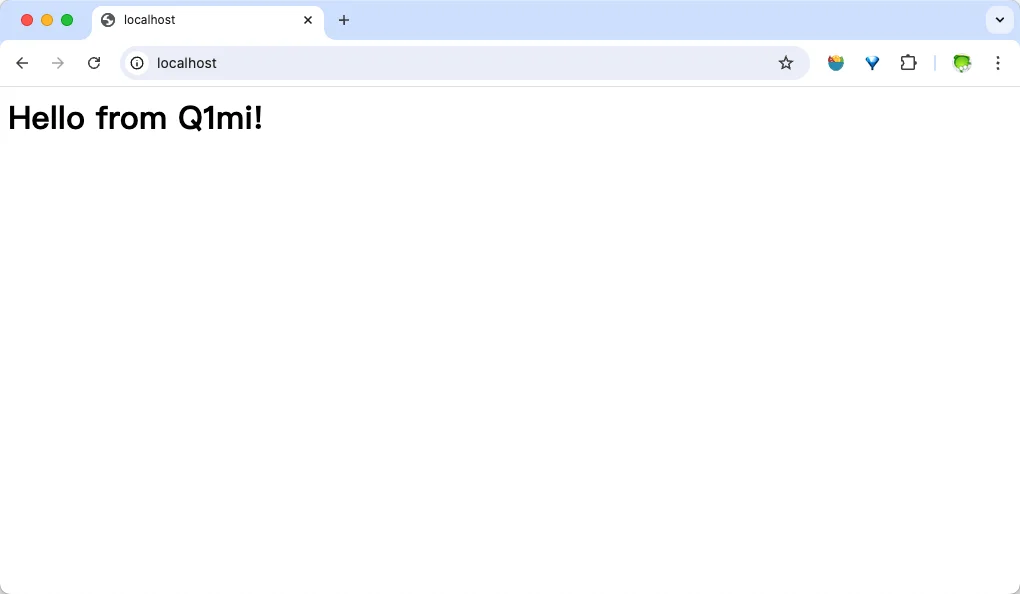
root@4e2cf2ce3977:/# echo '<h1>Hello from Q1mi!</h1>' > /usr/share/nginx/html/index.html
root@4e2cf2ce3977:/# exit
exit通过执行上面的命令,我们以交互式终端方式进入 webserver 容器,并执行了 bash 命令,也就是获得一个可操作的 Shell。 然后,我们用<h1>Hello from Q1mi!</h1>覆盖了 /usr/share/nginx/html/index.html 的内容。 现在我们再刷新浏览器的话,会发现内容被改变了。
我们修改了容器的文件,也就是改动了容器的存储层。我们可以通过docker diff命令看到具体的改动。
❯ docker diff webserver
C /var
C /var/cache
C /var/cache/nginx
A /var/cache/nginx/client_temp
A /var/cache/nginx/fastcgi_temp
A /var/cache/nginx/proxy_temp
A /var/cache/nginx/scgi_temp
A /var/cache/nginx/uwsgi_temp
C /root
A /root/.bash_history
C /usr
C /usr/share
C /usr/share/nginx
C /usr/share/nginx/html
C /usr/share/nginx/html/index.html
C /etc
C /etc/nginx
C /etc/nginx/conf.d
C /etc/nginx/conf.d/default.conf
C /run
A /run/nginx.pid现在我们做了一些定制操作,希望能将其保存下来形成镜像。
要知道,当我们运行一个容器的时候(如果不使用数据卷的话),我们做的任何文件修改都会被记录于容器存储层里。而 Docker 提供了一个docker commit命令,可以将容器的存储层保存下来成为镜像。换句话说,就是在原有镜像的基础上,再叠加上容器的存储层,并构成新的镜像。以后我们运行这个新镜像的时候,就会拥有原有容器最后的文件变化。
我们可以用下面的命令将容器保存为镜像:
❯ docker commit \
--author "Q1mi" \
--message "修改默认首页" \
webserver \
nginx:v0.1其中
--author是指定修改的作者--message则是记录本次修改的内容。
这里的操作和 git 版本控制有些相似,不过这里这些信息可以省略留空。
我们可以在docker image ls中看到这个新定制的镜像:
❯ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx v0.1 036a285f37a9 About a minute ago 193MB
test/ubuntu v1.0 eadbd74e1017 2 days ago 56.7MB我们还可以用docker history具体查看镜像内的历史记录,如果比较 nginx:latest 的历史记录,我们会发现新增了我们刚刚提交的这一层。
❯ docker history nginx:v0.1
IMAGE CREATED CREATED BY SIZE COMMENT
036a285f37a9 2 minutes ago nginx -g daemon off; 1.19kB 修改默认首页
235ff27fe795 8 weeks ago CMD ["nginx" "-g" "daemon off;"] 0B buildkit.dockerfile.v0
<missing> 8 weeks ago STOPSIGNAL SIGQUIT 0B buildkit.dockerfile.v0
<missing> 8 weeks ago EXPOSE map[80/tcp:{}] 0B buildkit.dockerfile.v0
<missing> 8 weeks ago ENTRYPOINT ["/docker-entrypoint.sh"] 0B buildkit.dockerfile.v0
<missing> 8 weeks ago COPY 30-tune-worker-processes.sh /docker-ent… 4.62kB buildkit.dockerfile.v0
<missing> 8 weeks ago COPY 20-envsubst-on-templates.sh /docker-ent… 3.02kB buildkit.dockerfile.v0
<missing> 8 weeks ago COPY 15-local-resolvers.envsh /docker-entryp… 336B buildkit.dockerfile.v0
<missing> 8 weeks ago COPY 10-listen-on-ipv6-by-default.sh /docker… 2.12kB buildkit.dockerfile.v0
<missing> 8 weeks ago COPY docker-entrypoint.sh / # buildkit 1.62kB buildkit.dockerfile.v0
<missing> 8 weeks ago RUN /bin/sh -c set -x && groupadd --syst… 95.9MB buildkit.dockerfile.v0
<missing> 8 weeks ago ENV PKG_RELEASE=2~bookworm 0B buildkit.dockerfile.v0
<missing> 8 weeks ago ENV NJS_RELEASE=2~bookworm 0B buildkit.dockerfile.v0
<missing> 8 weeks ago ENV NJS_VERSION=0.8.4 0B buildkit.dockerfile.v0
<missing> 8 weeks ago ENV NGINX_VERSION=1.27.0 0B buildkit.dockerfile.v0
<missing> 8 weeks ago LABEL maintainer=NGINX Docker Maintainers <d… 0B buildkit.dockerfile.v0
<missing> 8 weeks ago /bin/sh -c #(nop) CMD ["bash"] 0B
<missing> 8 weeks ago /bin/sh -c #(nop) ADD file:4aa9ddc52f0465927… 97.1MB 新的镜像定制好后,我们可以来运行这个镜像。
❯ docker run --name webserver2 -d -p 81:80 nginx:v0.1
e677547ec307a171b990925193c3ba71d6c8078d46ede32287dbd4ae575ca054这里我们命名为新的服务为 webserv2,并且映射到 81 端口。如果是 Docker for Mac/Windows 或 Linux 桌面的话,我们就可以直接访问 http://localhost:81 看到结果,其内容应该和之前修改后的 webserver 一样。
至此,我们第一次完成了定制镜像,使用的是docker commit命令,手动操作给旧的镜像添加了新的一层,形成新的镜像,对镜像多层存储应该有了更直观的感觉。
使用 docker commit 命令虽然可以比较直观的帮助理解镜像分层存储的概念,但是实际环境中并不会这样使用。
首先,如果仔细观察之前的 docker diff webserver 的结果,你会发现除了真正想要修改的 /usr/share/nginx/html/index.html 文件外,由于命令的执行,还有很多文件被改动或添加了。这还仅仅是最简单的操作,如果是安装软件包、编译构建,那会有大量的无关内容被添加进来,将会导致镜像极为臃肿。
此外,使用 docker commit 意味着所有对镜像的操作都是黑箱操作,生成的镜像也被称为 黑箱镜像,换句话说,就是除了制作镜像的人知道执行过什么命令、怎么生成的镜像,别人根本无从得知。而且,即使是这个制作镜像的人,过一段时间后也无法记清具体的操作。这种黑箱镜像的维护工作是非常痛苦的。
而且,回顾之前提及的镜像所使用的分层存储的概念,除当前层外,之前的每一层都是不会发生改变的,换句话说,任何修改的结果仅仅是在当前层进行标记、添加、修改,而不会改动上一层。如果使用 docker commit 制作镜像,以及后期修改的话,每一次修改都会让镜像更加臃肿一次,所删除的上一层的东西并不会丢失,会一直如影随形的跟着这个镜像,即使根本无法访问到。这会让镜像更加臃肿。
注意: docker commit 命令除了学习之外,还有一些特殊的应用场合,比如被入侵后保存现场等。但是,不要使用 docker commit 定制镜像,定制镜像应该使用
Dockerfile来完成。
Dockerfile
从刚才的 docker commit 的学习中,我们可以了解到,镜像的定制实际上就是定制每一层所添加的配置、文件。如果我们可以把每一层修改、安装、构建、操作的命令都写入一个脚本,用这个脚本来构建、定制镜像,那么之前提及的无法重复的问题、镜像构建透明性的问题、体积的问题就都会解决。这个脚本就是 Dockerfile。
官方指南:https://docs.docker.com/reference/dockerfile/
重要!重要!重要!
使用M芯片的Mac电脑的同学注意啦!
由于 在安装某些软件包的时候,比如curl 命令获取的软件包列表引用了系统的架构,因此并非所有软件都可以在 Apple M1(arm64)上使用。
你可以在你的Dockerfile 第一行指定 platform
FROM --platform=linux/amd64 your-image-name或者修改你的环境变量
export DOCKER_DEFAULT_PLATFORM=linux/amd64
介绍
Dockerfile 是一个文本文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。
还以之前定制 nginx 镜像为例,这次我们使用 Dockerfile 来定制。在一个空白目录(我这里新建了一个mynginx目录)中,建立一个名为Dockerfile的文本文件:
❯ mkdir mynginx
❯ cd mynginx
❯ touch Dockerfile把以下内容粘贴到 Dockerfile中:
FROM nginx
RUN echo '<h1>Hello from Q1mi again!</h1>' > /usr/share/nginx/html/index.html这个 Dockerfile 很简单,一共就两行。涉及到了两条指令,FROM 和 RUN。
FROM 指定基础镜像
所谓定制镜像,那一定是以一个镜像为基础,在其上进行定制。就像我们之前运行了一个 nginx 镜像的容器,再进行修改一样,基础镜像是必须指定的。而FROM就是指定基础镜像,因此一个 Dockerfile 中 FROM 是必备的指令,并且必须是第一条指令。
在Docker Store上有非常多的高质量的官方镜像,有可以直接拿来使用的服务类的镜像,如 nginx、redis、mongo、mysql、httpd、php、tomcat 等;也有一些方便开发、构建、运行各种语言应用的镜像,如 node、openjdk、python、ruby、golang 等。可以在其中寻找一个最符合我们最终目标的镜像为基础镜像进行定制。
如果没有找到对应服务的镜像,官方镜像中还提供了一些更为基础的操作系统镜像,如 ubuntu、debian、centos、fedora、alpine 等,这些操作系统的软件库为我们提供了更广阔的扩展空间。
除了选择现有镜像为基础镜像外,Docker 还存在一个特殊的镜像,名为scratch。这个镜像是虚拟的概念,并不实际存在,它表示一个空白的镜像。
FROM scratch
...如果你以scratch为基础镜像的话,意味着你不以任何镜像为基础,接下来所写的指令将作为镜像第一层开始存在。有的同学可能感觉很奇怪,没有任何基础镜像,我怎么去执行我的程序呢,其实对于 Linux 下静态编译的程序来说,并不需要有操作系统提供运行时支持,所需的一切库都已经在可执行文件里了,因此直接FROM scratch会让镜像体积更加小巧。使用 Go 语言开发的应用很多会使用这种方式来制作镜像,这也是为什么有人认为 Go 是特别适合容器微服务架构的语言的原因之一。
相反,创建一个python程序的容器就需要准备一个python环境,创建一个java程序的容器就需要给它准备一个 jvm。
RUN 执行命令
RUN 指令是用来执行命令行命令的。由于命令行的强大能力,RUN 指令在定制镜像时是最常用的指令之一。其格式有两种:
shell 格式:
RUN <命令>,就像直接在命令行中输入的命令一样。刚才写的 Dockerfile 中的RUN指令就是这种格式。exec 格式:
RUN ["可执行文件", "参数1", "参数2"],这更像是函数调用中的格式。
既然 RUN 就像 Shell 脚本一样可以执行命令,那么我们是否就可以像 Shell 脚本一样把每个命令对应一个 RUN 呢?比如像下面这样写 Dockerfile 准备一个Redis镜像:
FROM debian:stretch
RUN apt-get update
RUN apt-get install -y gcc libc6-dev make wget
RUN wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz"
RUN mkdir -p /usr/src/redis
RUN tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1
RUN make -C /usr/src/redis
RUN make -C /usr/src/redis install这样的 Dockerfile 虽然能用,但是一般不这样写。
之前说过,Dockerfile 中每一个指令都会建立一层,RUN 也不例外。每一个 RUN 的行为,就和刚才我们手工建立镜像的过程一样:新建立一层,在其上执行这些命令,执行结束后,commit 这一层的修改,构成新的镜像。
而上面的这种写法,创建了 7 层镜像。这是完全没有意义的,而且很多运行时不需要的东西,都被装进了镜像里,比如编译环境、更新的软件包等等。结果就是产生非常臃肿、非常多层的镜像,不仅仅增加了构建部署的时间,也很容易出错。 这是很多初学 Docker 的人常犯的一个错误。
Union FS 是有最大层数限制的,比如 AUFS最大不得超过 127 层。
上面那个 Dockerfile 最正确的写法应该是如下:
FROM debian:stretch
RUN set -x; buildDeps='gcc libc6-dev make wget' \
&& apt-get update \
&& apt-get install -y $buildDeps \
&& wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" \
&& mkdir -p /usr/src/redis \
&& tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1 \
&& make -C /usr/src/redis \
&& make -C /usr/src/redis install \
&& rm -rf /var/lib/apt/lists/* \
&& rm redis.tar.gz \
&& rm -r /usr/src/redis \
&& apt-get purge -y --auto-remove $buildDeps首先,之前所有的命令只有一个目的,就是编译、安装 redis 可执行文件。因此没有必要建立很多层,这只是一层的事情。因此,这里没有使用很多个 RUN 一一对应不同的命令,而是仅仅使用一个 RUN 指令,并使用 && 将各个所需命令串联起来。将之前的 7 层,简化为了 1 层。在撰写 Dockerfile 的时候,要经常提醒自己,这并不是在写 Shell 脚本,而是在定义每一层该如何构建。
并且,这里为了格式化还进行了换行。Dockerfile 支持 Shell 类的行尾添加 \ 的命令换行方式,以及行首 # 进行注释的格式。良好的格式,比如换行、缩进、注释等,会让维护、排障更为容易,这是一个比较好的习惯。
此外,还可以看到这一组命令的最后添加了清理工作的命令,删除了为了编译构建所需要的软件,清理了所有下载、展开的文件,并且还清理了 apt 缓存文件。这是很重要的一步,我们之前说过,镜像是多层存储,每一层的东西并不会在下一层被删除,会一直跟随着镜像。因此镜像构建时,一定要确保每一层只添加真正需要添加的东西,任何无关的东西都应该清理掉。
很多人初学 Docker 制作出了很臃肿的镜像的原因之一,就是忘记了每一层构建的最后一定要清理掉无关文件。
构建镜像
在介绍完了常用的 FROM 和 RUN 指令后,我们现在将使用之前编写的 mynginx的 Dockerfile文件进行构建。
在 Dockerfile 文件所在的目录执行 docker build -t nginx:v0.2 .命令。
❯ docker build -t nginx:v0.2 .
[+] Building 0.1s (6/6) FINISHED docker:desktop-linux
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 126B 0.0s
=> [internal] load metadata for docker.io/library/nginx:latest 0.0s
=> [1/2] FROM docker.io/library/nginx 0.0s
=> [2/2] RUN echo '<h1>Hello from Q1mi again!</h1>' > /usr/share/nginx/html/index.html 0.1s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:b67e1bc2ab3db3363d9924bd25860f12b737f4aa5a37d89a71d0ffd78b06943a 0.0s
=> => naming to docker.io/library/nginx:v0.2 0.0s
What's Next?
View a summary of image vulnerabilities and recommendations → docker scout quickview从命令的输出结果中,我们可以清晰的看到镜像的构建过程分为了[1/2]和[2/2]两个步骤。
这里我们使用了 docker build 命令进行镜像构建。其格式为:
docker build [选项] <上下文路径/URL/->在这里我们指定了最终镜像的名称 -t nginx:v0.2,构建成功后,我们可以像之前运行 nginx:v0.1 那样来运行这个镜像,其结果会出现一个新的欢迎页面。
❯ docker run --name webserver3 -d -p 82:80 nginx:v0.2
26b5f2a97724df056f3ac90acb1aa0e05a36774eb515deb6815d33b5d2801b77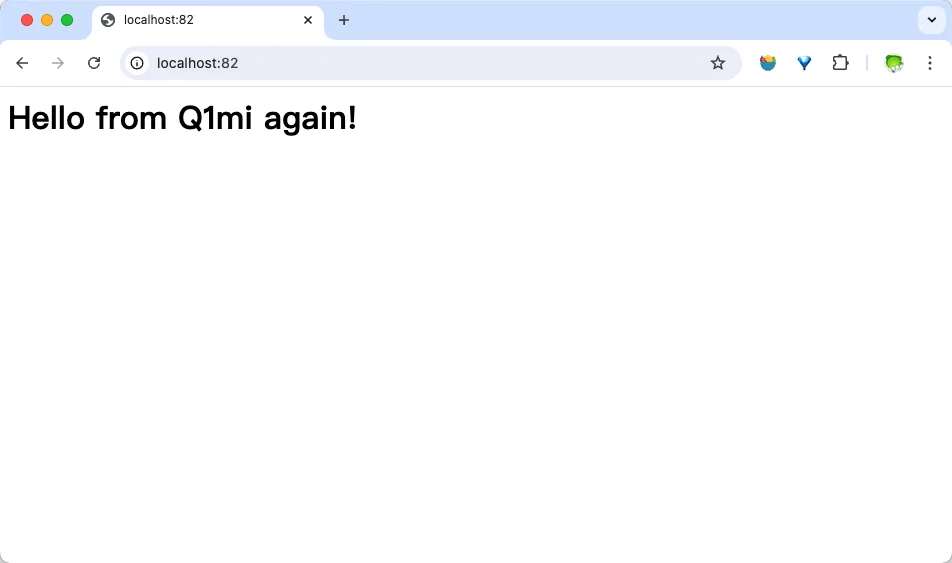
镜像构建上下文
在上面的 docker build 命令最后有一个 .。这个. 表示执行 docker build 时的当前目录,而 Dockerfile 就在这个目录下,因此不少初学者以为这个路径是在指定 Dockerfile 所在路径,这么理解其实是不准确的。
docker build 命令这里的格式是指定 上下文路径。那么什么是上下文呢?
首先我们要理解 docker build 的工作原理。Docker 在运行时分为 Docker 引擎(也就是服务端守护进程)和客户端工具。Docker 的引擎提供了一组 REST API,被称为 Docker Remote API,而 docker 客户端工具则是通过这组 API 与 Docker 引擎交互,从而完成各种功能。因此,虽然表面上我们好像是在本机执行各种 docker 功能,但实际上,一切都是使用的远程调用形式在服务端(Docker 引擎)完成。也因为这种 C/S 设计,让我们操作远程服务器的 Docker 引擎变得轻而易举。
当我们进行镜像构建的时候,并非所有定制都会通过 RUN 指令完成,经常会需要将一些本地文件复制进镜像,比如通过 COPY 指令、ADD 指令等。而 docker build 命令构建镜像,其实并非在本地构建,而是在服务端,也就是 Docker 引擎中构建的。那么在这种客户端/服务端的架构中,如何才能让服务端获得本地文件呢?
这就引入了上下文的概念。当构建的时候,用户会指定构建镜像上下文的路径,docker build 命令得知这个路径后,会将路径下的所有内容打包,然后上传给 Docker 引擎。这样 Docker 引擎收到这个上下文包后,展开就会获得构建镜像所需的一切文件。
如果在 Dockerfile 中这么写:
COPY ./package.json /app/这并不是要复制执行 docker build 命令所在的目录下的 package.json,也不是复制 Dockerfile 所在目录下的 package.json,而是复制 上下文(context) 目录下的 package.json。
因此,COPY 这类指令中的源文件的路径都是相对路径。这也是初学者经常会问的为什么 COPY ../package.json /app 或者 COPY /opt/xxxx /app 无法工作的原因,因为这些路径已经超出了上下文的范围,Docker 引擎无法获得这些位置的文件。如果真的需要那些文件,应该将它们复制到上下文目录中去。
现在就可以理解刚才的命令 docker build -t nginx:v0.2 . 中的这个 .,实际上是在指定上下文的目录,docker build 命令会将该目录下的内容打包交给 Docker 引擎以帮助构建镜像。
如果观察 docker build 输出,我们其实已经看到了这个发送上下文的过程:
❯ docker build -t nginx:v0.2 .
[+] Building 0.1s (6/6) FINISHED docker:desktop-linux
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load build definition from Dockerfile 0.0s
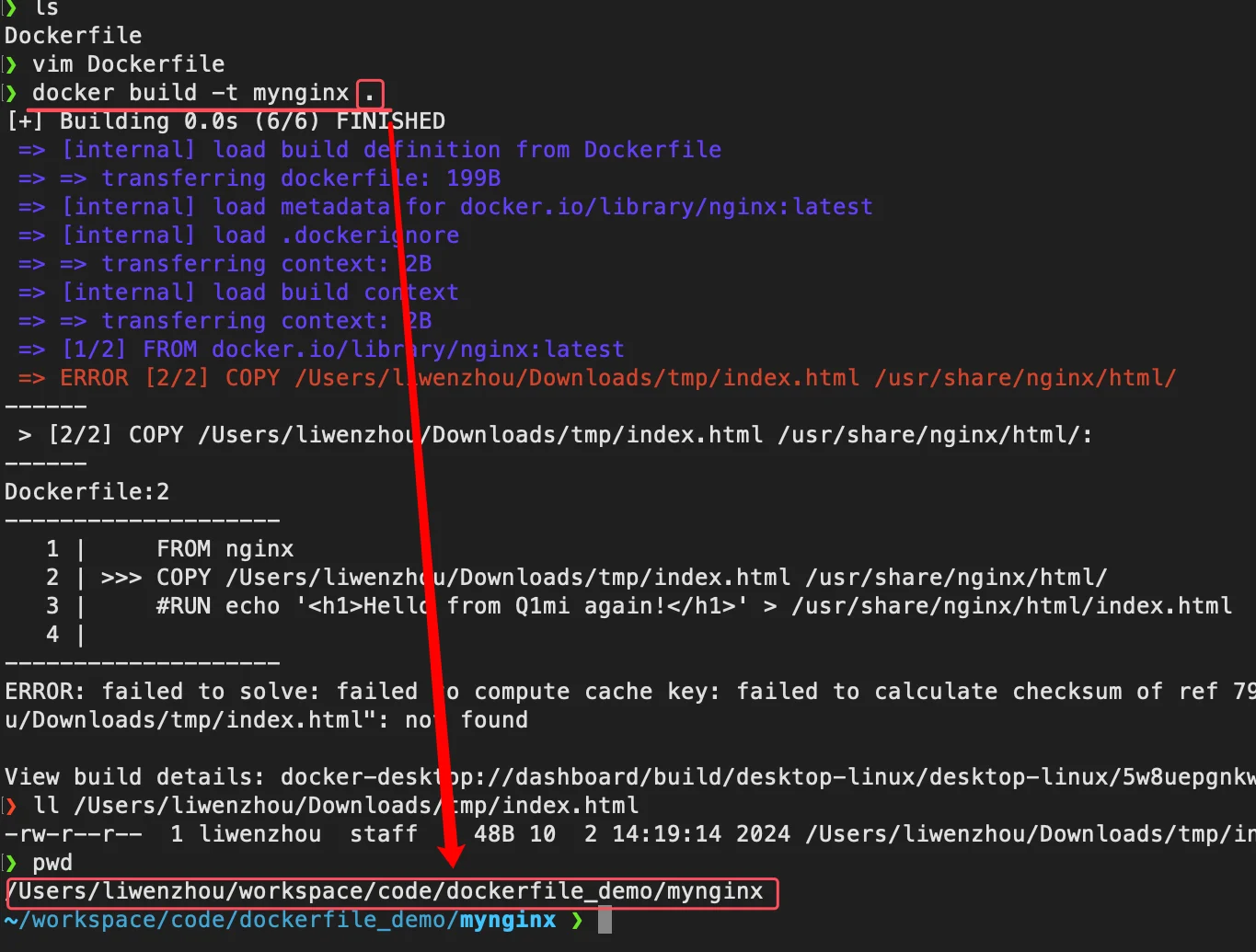
...理解构建上下文对于镜像构建是很重要的,避免犯一些不应该的错误。比如我们电脑上 /Users/liwenzhou/Downloads/tmp/ 目录有个 index.html ,现在我们能不能在 /workspace/code/dockerfile_demo/目录下直接构建下面这样的 Dockerfile 呢?
FROM nginx
COPY /Users/liwenzhou/Downloads/tmp/index.html /usr/share/nginx/html/当然是不能,构建上面的 Dockerfile 会报如下错误,提示找不到 /Users/liwenzhou/Downloads/tmp/index.html。
不指定绝对路径,在Dockerfile 中使用相对路径的写法。
FROM nginx
COPY ../index.html /usr/share/nginx/html/执行 docker build -t mynginx . 时同样报错提示找不到文件。
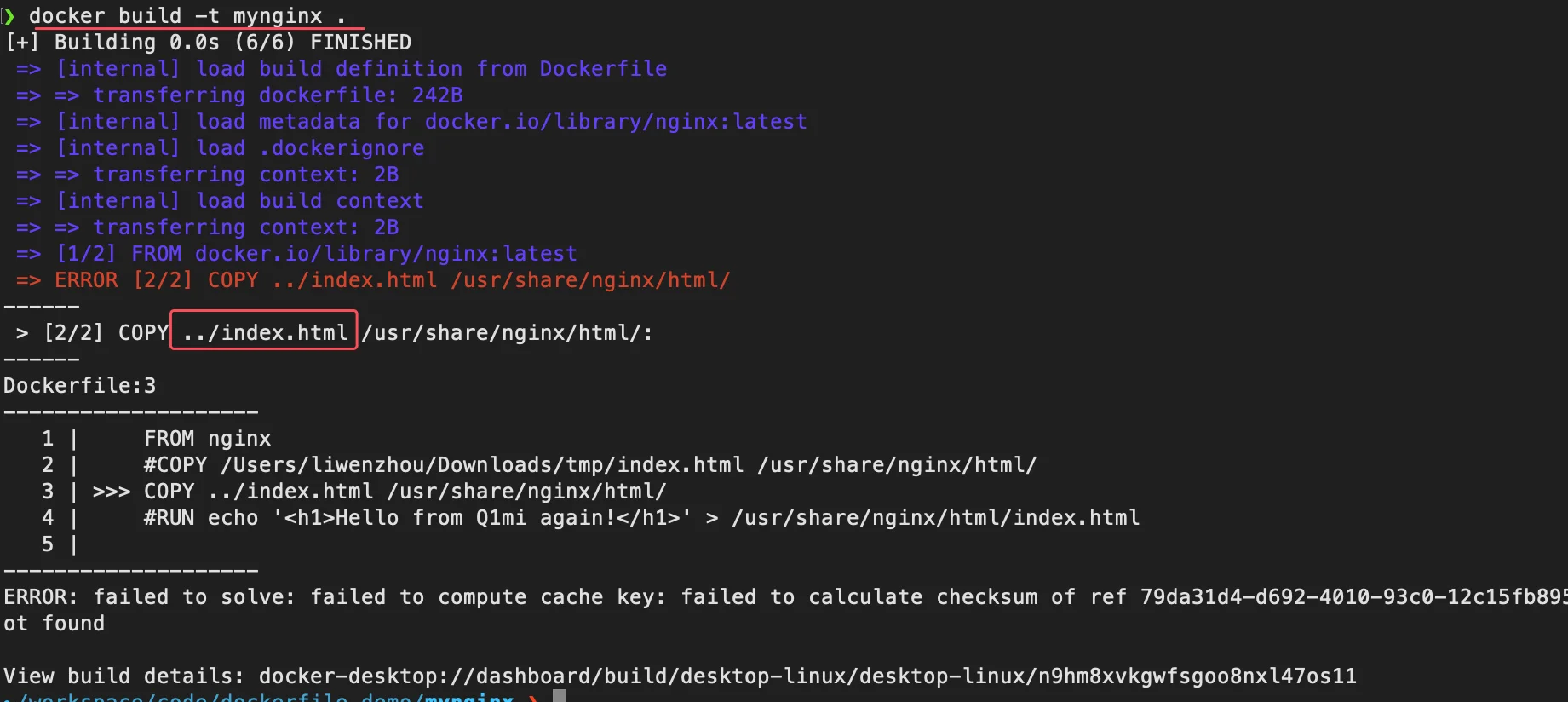
也就是说,我们 Dockerfile 中执行的指令都是基于执行docker build 命令时指定的上下文目录的。
很多没有正确理解构建上下文概念的同学,遇到上面的问题会干脆将 Dockerfile 放到了硬盘根目录去构建,结果发现 docker build 执行后,在发送一个几十 GB 的东西,极为缓慢而且很容易构建失败。那是因为这种做法是在让 docker build 打包整个硬盘,这显然是错误的使用方法。
一般来说,应该会将 Dockerfile 置于一个空目录或项目根目录下。同时将构建所需的文件与Dockerfile 保存在一起。
如果目录下有些东西确实不希望构建时传给 Docker 引擎,那么可以用 .gitignore 一样的语法写一个 .dockerignore,该文件是用于剔除不需要作为上下文传递给 Docker 引擎的。
那么为什么会有人误以为 . 是指定 Dockerfile 所在目录呢?这是因为在默认情况下,如果不额外指定 Dockerfile 的话,会将上下文目录下的名为 Dockerfile 的文件作为 Dockerfile。
这只是默认行为,实际上 Dockerfile 的文件名并不要求必须为 Dockerfile,而且并不要求必须位于上下文目录中,比如可以用 -f ../xxx.txt 参数指定某个文件作为 Dockerfile。
当然,一般大家习惯性的会使用默认的文件名 Dockerfile,以及会将其置于镜像构建上下文目录中。
直接用 Git repo 进行构建
❯ docker build -t hello-world https://github.com/docker-library/hello-world.git#master:amd64/hello-world这行命令指定了构建所需的 Git repo,并且指定分支为 master,构建目录为 /amd64/hello-world/,然后 Docker 就会自己去 git clone 这个项目、切换到指定分支、并进入到指定目录后开始构建。
用给定的 tar 压缩包构建
❯ docker build http://server/context.tar.gz如果所给出的 URL 不是个 Git repo,而是个 tar 压缩包,那么 Docker 引擎会下载这个包,并自动解压缩,以其作为上下文,开始构建。
迁移镜像
Docker 还提供了docker load和docker save命令,用以将镜像保存为一个 tar 文件,然后传输到另一个位置上,再加载进来。这是在没有 Docker Registry 时的做法,现在已经不推荐,镜像迁移应该直接使用 Docker Registry,无论是直接使用 Docker Hub 还是使用内网私有 Registry 都可以。
Dockerfile指令详解
Dockerfile官方指南:https://docs.docker.com/reference/dockerfile/
我们已经介绍了 FROM,RUN,还提及了 COPY, ADD,其实 Dockerfile 功能很强大,它提供了十多个指令。下面我们继续讲解其他的指令。
COPY 复制文件
格式:
COPY [--chown=<user>:<group>] <源路径>... <目标路径>COPY [--chown=<user>:<group>] ["<源路径1>",... "<目标路径>"]
和 RUN 指令一样,也有两种格式,一种类似于命令行,一种类似于函数调用。
COPY 指令将从构建上下文目录中 <源路径> 的文件/目录复制到新的一层的镜像内的 <目标路径> 位置。比如:
COPY package.json /usr/src/app/<源路径> 可以是多个,甚至可以是通配符,其通配符规则要满足 Go 的 filepath.Match 规则,如:
COPY hom* /mydir/
COPY hom?.txt /mydir/<目标路径> 可以是容器内的绝对路径,也可以是相对于工作目录的相对路径(工作目录可以用 WORKDIR 指令来指定)。目标路径不需要事先创建,如果目录不存在会在复制文件前先行创建缺失目录。
此外,还需要注意一点,使用 COPY 指令,源文件的各种元数据都会保留。比如读、写、执行权限、文件变更时间等。这个特性对于镜像定制很有用。特别是构建相关文件都在使用 Git 进行管理的时候。
在使用该指令的时候还可以加上 --chown=<user>:<group> 选项来改变文件的所属用户及所属组。
COPY --chown=55:mygroup files* /mydir/
COPY --chown=bin files* /mydir/
COPY --chown=1 files* /mydir/
COPY --chown=10:11 files* /mydir/如果源路径为文件夹,复制的时候不是直接复制该文件夹,而是将文件夹中的内容复制到目标路径。
ADD 更高级的复制文件
ADD 指令和 COPY 的格式和性质基本一致。但是在 COPY 基础上增加了一些功能。
比如 <源路径> 可以是一个 URL,这种情况下,Docker 引擎会试图去下载这个链接的文件放到 <目标路径> 去。下载后的文件权限自动设置为 600,如果这并不是想要的权限,那么还需要增加额外的一层 RUN 进行权限调整,另外,如果下载的是个压缩包,需要解压缩,也一样还需要额外的一层 RUN 指令进行解压缩。所以不如直接使用 RUN 指令,然后使用 wget 或者 curl 工具下载,处理权限、解压缩、然后清理无用文件更合理。因此,这个功能其实并不实用,而且不推荐使用。
如果 <源路径> 为一个 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,ADD 指令将会自动解压缩这个压缩文件到 <目标路径> 去。
在某些情况下,这个自动解压缩的功能非常有用,比如官方镜像 ubuntu 中:
FROM scratch
ADD ubuntu-xenial-core-cloudimg-amd64-root.tar.gz /
...但在某些情况下,如果我们真的是希望复制个压缩文件进去,而不解压缩,这时就不可以使用 ADD 命令了。
在 Docker 官方的 Dockerfile 最佳实践文档 中要求,尽可能的使用 COPY,因为 COPY 的语义很明确,就是复制文件而已,而 ADD 则包含了更复杂的功能,其行为也不一定很清晰。最适合使用 ADD 的场合,就是所提及的需要自动解压缩的场合。
另外需要注意的是,ADD 指令会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。
因此在 COPY 和 ADD 指令中选择的时候,可以遵循这样的原则,所有的文件复制均使用 COPY 指令,仅在需要自动解压缩的场合使用 ADD。
在使用该指令的时候还可以加上 --chown=<user>:<group> 选项来改变文件的所属用户及所属组。
ADD --chown=55:mygroup files* /mydir/
ADD --chown=bin files* /mydir/
ADD --chown=1 files* /mydir/
ADD --chown=10:11 files* /mydir/CMD 容器启动命令
CMD 指令的格式和 RUN 相似,也是两种格式:
shell格式:CMD <命令>exec格式:CMD ["可执行文件", "参数1", "参数2"...]- 参数列表格式:
CMD ["参数1", "参数2"...]。在指定了ENTRYPOINT指令后,用CMD指定具体的参数。
之前介绍容器的时候曾经说过,Docker 不是虚拟机,容器就是进程。既然是进程,那么在启动容器的时候,需要指定所运行的程序及参数。CMD 指令就是用于指定默认的容器主进程的启动命令的。
在运行时可以指定新的命令来替代镜像设置中的这个默认命令,比如,ubuntu 镜像默认的 CMD 是 /bin/bash,如果我们直接 docker run -it ubuntu 的话,会直接进入 bash。我们也可以在运行时指定运行别的命令,如 docker run -it ubuntu cat /etc/os-release。这就是用 cat /etc/os-release 命令替换了默认的 /bin/bash 命令了,输出了系统版本信息。
在指令格式上,一般推荐使用 exec 格式,这类格式在解析时会被解析为 JSON 数组,因此一定要使用双引号 ",而不要使用单引号。
如果使用 shell 格式的话,实际的命令会被包装为 sh -c 的参数的形式进行执行。比如:
CMD echo $HOME在实际执行中,会将其变更为:
CMD [ "sh", "-c", "echo $HOME" ]这就是为什么我们可以使用环境变量的原因,因为这些环境变量会被 shell 进行解析处理。
提到 CMD 就不得不提容器中应用在前台执行和后台执行的问题。这是初学者常出现的一个混淆。
Docker 不是虚拟机,容器中的应用都应该以前台执行,而不是像虚拟机、物理机里面那样,用 systemd 去启动后台服务,容器内没有后台服务的概念。
一些初学者将 CMD 写为:
CMD service nginx start然后发现容器执行后就立即退出了。甚至在容器内去使用 systemctl 命令结果却发现根本执行不了。这就是因为没有搞明白前台、后台的概念,没有区分容器和虚拟机的差异,依旧在以传统虚拟机的角度去理解容器。
对于容器而言,其启动程序就是容器应用进程,容器就是为了主进程而存在的,主进程退出,容器就失去了存在的意义,从而退出,其它辅助进程不是它需要关心的东西。
而使用 service nginx start 命令,则是希望 init 系统以后台守护进程的形式启动 nginx 服务。而刚才说了 CMD service nginx start 会被理解为 CMD [ "sh", "-c", "service nginx start"],因此主进程实际上是 sh。那么当 service nginx start 命令结束后,sh 也就结束了,sh 作为主进程退出了,自然就会令容器退出。
正确的做法是直接执行 nginx 可执行文件,并且要求以前台形式运行。比如:
CMD ["nginx", "-g", "daemon off;"]ENTRYPOINT 入口点
ENTRYPOINT 的格式和 RUN 指令格式一样,分为 exec 格式和 shell 格式。
- exec格式:
ENTRYPOINT ["executable", "param1", "param2"] - shell 格式:
ENTRYPOINT command param1 param2
ENTRYPOINT 的目的和 CMD 一样,都是在指定容器启动程序及参数。ENTRYPOINT 在运行时也可以替代,不过比 CMD 要略显繁琐,需要通过 docker run 的参数 --entrypoint 来指定。
当指定了 ENTRYPOINT 后,CMD 的含义就发生了改变,不再是直接的运行其命令,而是将 CMD 的内容作为参数传给 ENTRYPOINT 指令,换句话说实际执行时,将变为:
<ENTRYPOINT> "<CMD>"CMD 和ENTRYPOINT 的主要区别在于它们的行为和用途:
- CMD 用于指定容器启动时的默认执行命令,如果在运行容器时提供了命令行参数,CMD 中的命令将被覆盖。
- ENTRYPOINT 用于指定容器启动时的固定执行命令,该命令不会被覆盖,运行时提供的参数将作为ENTRYPOINT 指定命令的参数。
那么有了 CMD 后,为什么还要有 ENTRYPOINT 呢?这种 <ENTRYPOINT> "<CMD>" 有什么好处么?让我们来看几个场景。
场景一:让镜像变成像命令一样使用
假设我们需要一个得知自己当前公网 IP 的镜像,那么可以先用 CMD 来实现:
FROM ubuntu:18.04
RUN apt-get update \
&& apt-get install -y curl \
&& rm -rf /var/lib/apt/lists/*
CMD [ "curl", "-s", "http://myip.ipip.net" ]假如我们使用 docker build -t myip . 来构建镜像的话,如果我们需要查询当前公网 IP,只需要执行:
❯ docker run myip
当前 IP:xx.xxx.xxx.xx 来自:北京市 联通嗯,这么看起来好像可以直接把镜像当做命令使用了,不过命令总有参数,如果我们希望加参数呢?比如从上面的 CMD 中可以看到实质的命令是 curl,那么如果我们希望显示 HTTP 头信息,就需要加上 -i 参数。那么我们可以直接加 -i 参数给 docker run myip 么?
❯ docker run myip -i
docker: Error response from daemon: invalid header field value "oci runtime error: container_linux.go:247: starting container process caused \"exec: \\\"-i\\\": executable file not found in $PATH\"\n".我们可以看到可执行文件找不到的报错,executable file not found。之前我们说过,跟在镜像名后面的是 command,运行时会替换 CMD 的默认值。因此这里的 -i 替换了原来的 CMD,而不是添加在原来的 curl -s http://myip.ipip.net 后面。而 -i 根本不是命令,所以自然找不到。
那么如果我们希望加入 -i 这参数,我们就必须重新完整的输入这个命令:
❯ docker run myip curl -s http://myip.ipip.net -i这显然不是很好的解决方案,而使用 ENTRYPOINT 就可以解决这个问题。现在我们重新用 ENTRYPOINT 来实现这个镜像:
FROM ubuntu:18.04
RUN apt-get update \
&& apt-get install -y curl \
&& rm -rf /var/lib/apt/lists/*
ENTRYPOINT [ "curl", "-s", "http://myip.ipip.net" ]这次我们再来尝试直接使用 docker run myip -i:
❯ docker run myip
当前 IP:xx.xxx.xxx.xx 来自:北京市 联通
❯ docker run myip -i
HTTP/1.1 200 OK
Server: nginx/1.8.0
Date: Tue, 10 Nov 2024 18:34:10 GMT
Content-Type: text/html; charset=UTF-8
Vary: Accept-Encoding
X-Powered-By: PHP/5.6.24-1~dotdeb+7.1
X-Cache: MISS from cache-2
X-Cache-Lookup: MISS from cache-2:80
X-Cache: MISS from proxy-2_6
Transfer-Encoding: chunked
Via: 1.1 cache-2:80, 1.1 proxy-2_6:8006
Connection: keep-alive
当前 IP:xx.xxx.xxx.xx 来自:北京市 联通可以看到,这次成功了。这是因为当存在 ENTRYPOINT 时,CMD 的内容将会作为参数传给 ENTRYPOINT,而这里 -i 就是新的 CMD,因此会作为参数传给 curl,从而达到了我们预期的效果。
场景二:应用运行前的准备工作
启动容器就是启动主进程,但有些时候,启动主进程前,需要一些准备工作。
比如 mysql 类的数据库,可能需要一些数据库配置、初始化的工作,这些工作要在最终的 mysql 服务器运行之前解决。
此外,可能希望避免使用 root 用户去启动服务,从而提高安全性,而在启动服务前还需要以 root 身份执行一些必要的准备工作,最后切换到服务用户身份启动服务。或者除了服务外,其它命令依旧可以使用 root 身份执行,方便调试等。
这些准备工作是和容器 CMD 无关的,无论 CMD 为什么,都需要事先进行一个预处理的工作。这种情况下,可以写一个脚本,然后放入 ENTRYPOINT 中去执行,而这个脚本会将接到的参数(也就是 <CMD>)作为命令,在脚本最后执行。比如官方镜像 redis 中就是这么做的:
FROM alpine:3.4
...
RUN addgroup -S redis && adduser -S -G redis redis
...
ENTRYPOINT ["docker-entrypoint.sh"]
EXPOSE 6379
CMD [ "redis-server" ]可以看到其中为了 redis 服务创建了 redis 用户,并在最后指定了 ENTRYPOINT 为 docker-entrypoint.sh 脚本。
#!/bin/sh
...
# allow the container to be started with `--user`
if [ "$1" = 'redis-server' -a "$(id -u)" = '0' ]; then
find . \! -user redis -exec chown redis '{}' +
exec gosu redis "$0" "$@"
fi
exec "$@"该脚本的内容就是根据 CMD 的内容来判断,如果是 redis-server 的话,则切换到 redis 用户身份启动服务器,否则依旧使用 root 身份执行。比如:
❯ docker run -it redis id
uid=0(root) gid=0(root) groups=0(root)ENV 设置环境变量
语法格式:ENV <key>=<value> ...
这个指令很简单,就是设置环境变量而已,无论是后面的其它指令,如 RUN,还是运行时的应用,都可以直接使用这里定义的环境变量。
ENV MY_NAME="John Doe"
ENV MY_DOG=Rex\ The\ Dog
ENV MY_CAT=fluffy这个例子中演示了如何换行,以及对含有空格的值用双引号括起来的办法,这和 Shell 下的行为是一致的。
定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。比如在官方 node 镜像 Dockerfile 中,就有类似这样的代码:
ENV NODE_VERSION 7.2.0
RUN curl -SLO "https://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION-linux-x64.tar.xz" \
&& curl -SLO "https://nodejs.org/dist/v$NODE_VERSION/SHASUMS256.txt.asc" \
&& gpg --batch --decrypt --output SHASUMS256.txt SHASUMS256.txt.asc \
&& grep " node-v$NODE_VERSION-linux-x64.tar.xz\$" SHASUMS256.txt | sha256sum -c - \
&& tar -xJf "node-v$NODE_VERSION-linux-x64.tar.xz" -C /usr/local --strip-components=1 \
&& rm "node-v$NODE_VERSION-linux-x64.tar.xz" SHASUMS256.txt.asc SHASUMS256.txt \
&& ln -s /usr/local/bin/node /usr/local/bin/nodejs在这里先定义了环境变量 NODE_VERSION,其后的 RUN 这层里,多次使用 $NODE_VERSION 来进行操作定制。可以看到,将来升级镜像构建版本的时候,只需要更新 7.2.0 即可,Dockerfile 构建维护变得更轻松了。
下列指令可以支持环境变量展开: ADD、COPY、ENV、EXPOSE、FROM、LABEL、USER、WORKDIR、VOLUME、STOPSIGNAL、ONBUILD、RUN。
当从生成的映像运行容器时,使用ENV设置的环境变量将保持不变。您可以使用docker inspect查看这些值,并使用docker run --env <key>=<value>更改它们。
环境变量持久化可能会带来意想不到的副作用。例如,设置 ENV DEBIAN_FRONTEND=noninteractive 会改变 apt-get 的行为,可能会让镜像的用户感到困惑。 如果一个环境变量只在构建过程中需要,而不在最终镜像中使用,可以考虑为单个命令设置一个值:
RUN DEBIAN_FRONTEND=noninteractive apt-get update && apt-get install -y ...或者使用ARG,它不会持久存在于最终镜像中:
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt-get install -y ...ARG 构建参数
格式:
ARG <name>[=<default value>]构建参数和 ENV 的效果一样,都是设置环境变量。所不同的是,ARG 所设置的构建环境的环境变量,在将来容器运行时是不会存在这些环境变量的。但是不要因此就使用 ARG 保存密码之类的信息,因为 docker history 还是可以看到所有值的。
ARG指令定义了一个变量,用户可以在构建时使用docker build命令使用--build-ARG <varname>=<value>标志将该变量传递给构建器。
一个Dockerfile可能包含一个或多个ARG指令。例如,以下是一个有效的Dockerfile:
FROM busybox
ARG user1
ARG buildno
# ...ARG 指令可以选择包含默认值:
FROM busybox
ARG user1=someuser
ARG buildno=1
# ...ARG变量定义从Dockerfile中定义它的行开始生效,而不是从命令行或其他地方的参数使用开始生效。例如,考虑以下Dockerfile:
FROM busybox
USER ${username:-some_user}
ARG username
USER $username
# ...通过以下命令构建上面的Dockerfile 时:
❯ docker build --build-arg username=what_user .第 2 行的 USER 值为 some_user,因为随后的第 3 行定义了username变量。第 4 行的 USER 值为 what_user,因为username参数已通过命令行中传值。在 ARG 指令定义变量之前,任何变量的使用都会导致空字符串。
ARG 指令在定义它的编译阶段结束时会退出作用域。要在多个阶段中使用参数,每个阶段都必须包含 ARG 指令。
FROM busybox
ARG SETTINGS
RUN ./run/setup $SETTINGS
FROM busybox
ARG SETTINGS
RUN ./run/other $SETTINGS可以使用 ARG 或 ENV 指令指定 RUN 指令可用的变量。使用 ENV 指令定义的环境变量总是优先于同名的 ARG 指令。请看这个带有 ENV 和 ARG 指令的 Dockerfile。
FROM ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER=v1.0.0
RUN echo $CONT_IMG_VER然后,使用以下命令构建镜像:
❯ docker build --build-arg CONT_IMG_VER=v2.0.1 .在这种情况下,RUN 指令使用的是 v1.0.0,而不是用户传入的 ARG 设置:v2.0.1 。这种行为类似于 shell 脚本,在 shell 脚本中,本地作用域变量从定义开始就会覆盖作为参数传递的变量或从环境继承的变量。
使用上述示例但使用不同的 ENV 声明方式,可以在 ARG 和 ENV 指令之间创建更有用的交互:
FROM ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER=${CONT_IMG_VER:-v1.0.0}
RUN echo $CONT_IMG_VER与 ARG 指令不同的是,ENV 值会一直保留在构建的镜像中。考虑一下不带 --build-arg 标志的 docker 构建:
❯ docker build .在这个 Dockerfile 示例中,CONT_IMG_VER 仍会保留在镜像中,但其值将是 v1.0.0,因为这是 ENV 指令在第 3 行中设置的默认值。
VOLUME 定义匿名卷
之前我们说过,容器运行时应该尽量保持容器存储层不发生写操作,对于数据库类需要保存动态数据的应用,其数据库文件应该保存于数据卷(volume)中,后面的章节我们会进一步介绍 Docker 数据卷的概念。为了防止运行时用户忘记将动态文件所保存目录挂载为数据卷,在 Dockerfile 中,我们可以事先指定某些目录挂载为匿名卷,这样在运行时如果用户不指定挂载,其应用也可以正常运行,不会向容器存储层写入大量数据。
格式:
VOLUME ["/data"]VOLUME 指令使用指定名称创建挂载点,并将其标记为本地主机或其他容器的外部挂载卷。值可以是 JSON 数组 VOLUME ["/var/log/"] 或包含多个参数的纯字符串,如 VOLUME /var/log 或 VOLUME /var/log /var/db。
docker run 命令会使用基本镜像中指定位置存在的任何数据来初始化新创建的卷。例如,请看下面的 Dockerfile 代码段:
FROM ubuntu
RUN mkdir /myvol
RUN echo "hello world" > /myvol/greeting
VOLUME /myvol此Dockerfile生成一个镜像,使docker run在/myvol处创建一个新的挂载点,并将greeting文件复制到新创建的卷中。
EXPOSE 暴露端口
格式:
EXPOSE <port> [<port>/<protocol>...]EXPOSE 指令通知 Docker,容器在运行时监听指定的网络端口。可以指定该端口是以 TCP 还是 UDP 方式监听,如果没有指定协议,则默认为 TCP。
EXPOSE 指令实际上并不开启端口(只是一个声明)。它的作用是在构建映像的人和运行容器的人之间提供一种文档,说明哪些端口需要发布。要在运行容器时发布端口,可以使用 docker run 的 -p 标志来发布并映射一个或多个端口,或者使用 -P 标志来发布所有暴露的端口并将它们映射到高阶端口。
默认情况下,EXPOSE 假设端口为 TCP。也可以指定 UDP:
EXPOSE 80/udp要同时在 TCP 和 UDP 上公开端口,请使用两行:
EXPOSE 80/tcp
EXPOSE 80/udp在这种情况下,如果在 docker run 中使用 -P,端口就会暴露给 TCP 和 UDP 各一次。请记住,-P 使用的是主机上短暂的高顺序主机端口,因此 TCP 和 UDP 使用的不是同一个端口。
无论 EXPOSE 设置如何,您都可以在运行时使用 -p 标志覆盖这些设置。例如:
❯ docker run -p 80:80/tcp -p 80:80/udp ...WORKDIR 指定工作目录
格式:
WORKDIR /path/to/workdirWORKDIR 指令为 Dockerfile 中的任何 RUN、CMD、ENTRYPOINT、COPY 和 ADD 指令设置工作目录。如果 WORKDIR 不存在,即使在随后的 Dockerfile 指令中没有使用,它也会被创建。
WORKDIR 指令可以在 Dockerfile 中多次使用。如果提供了一个相对路径,它将是相对于前一个 WORKDIR 指令的路径。例如:
WORKDIR /a
WORKDIR b
WORKDIR c
RUN pwd在这个 Dockerfile 中,最后的 pwd 命令的输出将是 /a/b/c 。
WORKDIR指令可以解析之前使用ENV设置的环境变量。只能使用在Dockerfile中显式设置的环境变量。例如:
ENV DIRPATH=/path
WORKDIR $DIRPATH/$DIRNAME
RUN pwd此Dockerfile中最后一个pwd命令的输出将是/path/$DIRNAME
如果未指定,默认工作目录为/。在实践中,如果你不是从头开始构建一个Dockerfile(FROM scratch),那么WORKDIR可能会由你使用的基础映像设置。
因此,为了避免未知目录中的意外操作,最佳做法是显式设置 WORKDIR。
一些初学者常犯的错误是把 Dockerfile 等同于 Shell 脚本来书写,这种错误的理解还可能会导致出现下面这样的错误:
RUN cd /app
RUN echo "hello" > world.txt如果将这个 Dockerfile 进行构建镜像运行后,会发现找不到 /app/world.txt 文件,或者其内容不是 hello。原因其实很简单,在 Shell 中,连续两行是同一个进程执行环境,因此前一个命令修改的内存状态,会直接影响后一个命令;而在 Dockerfile 中,这两行 RUN 命令的执行环境根本不同,是两个完全不同的容器。这就是对 Dockerfile 构建分层存储的概念不了解所导致的错误。
之前说过每一个 RUN 都是启动一个容器、执行命令、然后提交存储层文件变更。第一层 RUN cd /app 的执行仅仅是当前进程的工作目录变更,一个内存上的变化而已,其结果不会造成任何文件变更。而到第二层的时候,启动的是一个全新的容器,跟第一层的容器更完全没关系,自然不可能继承前一层构建过程中的内存变化。
因此如果需要改变以后各层的工作目录的位置,那么应该使用 WORKDIR 指令。
# RUN cd /app
WORKDIR /app
RUN echo "hello" > world.txtUSER 指定当前用户
格式:
USER <user>[:<group>]或者
USER <UID>[:<GID>]USER 指令设置用户名(或 UID)和用户组(或 GID),作为当前阶段剩余时间的默认用户和组。指定的用户将用于 RUN 指令,并在运行时运行相关的 ENTRYPOINT 和 CMD 命令。
注意,
USER只是帮助你切换到指定用户而已,这个用户必须是事先建立好的,否则无法切换。
如果以 root 执行的脚本,在执行期间希望改变身份,比如希望以某个已经建立好的用户来运行某个服务进程,不要使用 su 或者 sudo,这些都需要比较麻烦的配置,而且在 TTY 缺失的环境下经常出错。建议使用 gosu。
# 建立 redis 用户,并使用 gosu 换另一个用户执行命令
RUN groupadd -r redis && useradd -r -g redis redis
# 下载 gosu
RUN wget -O /usr/local/bin/gosu "https://github.com/tianon/gosu/releases/download/1.12/gosu-amd64" \
&& chmod +x /usr/local/bin/gosu \
&& gosu nobody true
# 设置 CMD,并以另外的用户执行
CMD [ "exec", "gosu", "redis", "redis-server" ]HEALTHCHECK 健康检查
HEALTHCHECK 指令有两种形式:
HEALTHCHECK [OPTIONS] CMD command:设置检查容器健康状况的命令HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
HEALTHCHECK 指令是告诉 Docker 应该如何进行判断容器的状态是否正常,这是 Docker 1.12 引入的新指令。
在没有 HEALTHCHECK 指令前,Docker 引擎只可以通过容器内主进程是否退出来判断容器是否状态异常。很多情况下这没问题,但是如果程序进入死锁状态,或者死循环状态,应用进程并不退出,但是该容器已经无法提供服务了。在 1.12 以前,Docker 不会检测到容器的这种状态,从而不会重新调度,导致可能会有部分容器已经无法提供服务了却还在接受用户请求。
而自 1.12 之后,Docker 提供了 HEALTHCHECK 指令,通过该指令指定一行命令,用这行命令来判断容器主进程的服务状态是否还正常,从而比较真实的反应容器实际状态。
当在一个镜像指定了 HEALTHCHECK 指令后,用其启动容器,初始状态会为 starting,在 HEALTHCHECK 指令检查成功后变为 healthy,如果连续一定次数失败,则会变为 unhealthy。
HEALTHCHECK 支持下列选项:
--interval=DURATION(default:30s) :两次健康检查的间隔,默认为 30 秒;--timeout=DURATION(default:30s):健康检查命令运行超时时间,如果超过这个时间,本次健康检查就被视为失败,默认 30 秒;--start-period=DURATION(default:0s):启动期为需要时间启动的容器提供初始化时间。在此期间发生的探针故障将不计入最大重试次数,默认0s--start-interval=DURATION(default:5s):开始间隔是开始期间健康检查之间的时间,默认5秒(此选项需要Docker Engine 25.0或更高版本。)--retries=N(default:3):当连续失败指定次数后,则将容器状态视为unhealthy,默认 3 次。
和 CMD, ENTRYPOINT 一样,HEALTHCHECK 只可以出现一次,如果写了多个,只有最后一个生效。
在 HEALTHCHECK [选项] CMD 后面的命令,格式和 ENTRYPOINT 一样,分为 shell 格式,和 exec 格式。命令的返回值决定了该次健康检查的成功与否:
0:成功;1:失败;2:保留值,不要使用这个返回值。
假设我们有个镜像是个最简单的 Web 服务,我们希望增加健康检查来判断其 Web 服务是否在正常工作,我们可以用 curl 来帮助判断,其 Dockerfile 的 HEALTHCHECK 可以这么写:
FROM nginx
RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/*
HEALTHCHECK --interval=5s --timeout=3s --start-period=1s \
CMD curl -fs http://localhost/ || exit 1这里我们设置了每 5 秒检查一次(这里为了试验所以间隔非常短,实际应该相对较长),如果健康检查命令超过 3 秒没响应就视为失败,并且使用 curl -fs http://localhost/ || exit 1 作为健康检查命令。
ONBUILD
格式
ONBUILD <INSTRUCTION>ONBUILD 是一个特殊的指令,它后面跟的是其它指令,比如 RUN, COPY 等,而这些指令,在当前镜像构建时并不会被执行。只有当以当前镜像为基础镜像,去构建下一级镜像的时候才会被执行。
任何构建指令都可以注册为触发器。
如果你要构建的镜像将被用作构建其他镜像的基础,例如应用程序构建环境或可通过用户特定配置进行自定义的守护进程,那么ONBUILD就非常有用。
例如,如果你的镜像是一个可重用的 Python 应用程序生成器,它将需要在特定目录中添加应用程序源代码,之后可能还需要调用一个构建脚本。你现在不能直接在镜像中调用 ADD 和 RUN,因为你还没办法拿到应用程序源代码,而且每个应用程序的构建都会有所不同(你写镜像的时候还不知道会被用来生成什么代码)。你可以简单地为应用程序开发人员提供一个 Dockerfile 模板,让他们复制粘贴到自己的应用程序中,但这样做效率低、容易出错,而且很难更新,因为其中混入了特定于应用程序的代码。
解决方法是使用 ONBUILD 来注册提前指令,以便后续在下一个构建阶段运行。
ONBUILD工作原理如下:
- 当遇到 ONBUILD 指令时,构建器会将触发器添加到正在构建的镜像的元数据中。该指令不会影响当前的构建。
- 在编译结束时,所有触发器的列表都会存储在镜像清单中的
OnBuild关键字下。你可以使用docker inspect命令检查它们。 - 之后,可以使用 FROM 指令将该镜像作为新构建的基础。在处理
FROM指令时,下游构建器会查找ONBUILD触发器,并按照注册时的顺序执行。如果任何触发器失败,FROM指令就会中止,进而导致构建失败。如果所有触发器都成功执行,则FROM指令完成,编译过程照常进行。 - 触发器在执行后会从最终镜像中清除。换句话说,它们不会被 “子代 ”编译继承
例如,我们可以添加以下内容:
ONBUILD ADD . /app/src
ONBUILD RUN /usr/local/bin/python-build --dir /app/srcONBUILD限制
- 不支持
ONBUILD ONBUILD这样连续调用ONBUILD ONBUILD指令不能触发FROM或MAINTAINER指令。- 不支持
ONBUILD COPY --from
LABEL 为镜像添加元数据
格式:
LABEL <key>=<value> <key>=<value> <key>=<value> ...LABEL 是键-值对。若要在 LABEL 值中包含空格,请像在命令行解析中那样使用引号和反斜杠。一些使用例子:
LABEL "com.example.vendor"="ACME Incorporated"
LABEL com.example.label-with-value="foo"
LABEL version="1.0"
LABEL description="This text illustrates \
that label-values can span multiple lines."一个镜像可以有多个标签。您可以在一行中指定多个标签。在 Docker 1.10之前,这会减小最终镜像的大小,但现在不再是这样了。您仍然可以选择通过以下两种方式之一在一条指令中指定多个标签:
LABEL multi.label1="value1" multi.label2="value2" other="value3"LABEL multi.label1="value1" \
multi.label2="value2" \
other="value3"注意:一定要使用双引号,而不是单引号。特别是当你使用字符串插值时(例如
LABEL example=“foo-$ENV_VAR”),单引号将按原样获取字符串,而无需解包变量的值。
基本镜像或父镜像(FROM 行中的镜像)中的标签会被镜像继承。如果某个标签已经存在,但其值不同,则最近应用的值会优先于之前设置的值。
要查看镜像的标签,可以使用 docker 镜像检查(docker image inspect)命令。你可以使用 --format 选项来只显示标签;
❯ docker image inspect --format='{{json .Config.Labels}}' myimage输出:
{
"com.example.vendor": "ACME Incorporated",
"com.example.label-with-value": "foo",
"version": "1.0",
"description": "This text illustrates that label-values can span multiple lines.",
"multi.label1": "value1",
"multi.label2": "value2",
"other": "value3"
}SHELL 指令
格式:
SHELL ["executable", "parameters"]SHELL指令允许覆盖用于命令SHELL形式的默认SHELL。Linux上的默认shell是["/bin/sh", "-c"],Windows上的默认shell是["cmd", "/S", "/C"]。SHELL指令必须以JSON格式编写在Dockerfile中。
SHELL ["/bin/sh", "-cex"]
RUN ls当 ENTRYPOINT、 CMD 以 shell 指定格式时,SHELL 指令所指定的 shell 也会成为这两个指令的 shell。
SHELL ["/bin/sh", "-cex"]
# /bin/sh -cex "nginx"
ENTRYPOINT nginxSHELL ["/bin/sh", "-cex"]
# /bin/sh -cex "nginx"
CMD nginxSTOPSIGNAL
格式:
STOPSIGNAL signalSTOPSIGNAL 指令设置将发送给容器以退出的系统调用信号。该信号可以是格式为 SIG<NAME> 的信号名,例如 SIGKILL,也可以是与内核系统调用表中某个位置相匹配的无符号数字,例如 9。如果没有定义,默认为 SIGTERM。
每个容器都可以使用 docker run 和 docker create 的 --stop-signal 标志来重写镜像的默认停止信号。
数据管理
官方相关文档:
默认情况下,容器内创建的所有文件都存储在可写容器层上。这意味着:
当容器不再存在时,数据不会持久化,而且如果其他进程需要数据,则很难将数据从容器中取出。
容器的可写层与运行容器的主机紧密耦合。不能轻易地将数据移动到其他地方。
写入容器的可写层需要一个存储驱动程序来管理文件系统。存储驱动程序使用 Linux 内核提供一个联合文件系统。与使用直接写入主机文件系统的数据卷相比,这种额外的抽象降低了性能。
Docker为容器在主机上存储文件提供了两种选择,这样即使在容器停止后,文件也会被持久化:
- 数据卷(Volumes)
- 绑定挂载 (Bind mounts)
Docker还支持在主机上的内存中存储文件的容器。此类文件不会持久化。如果你在Linux上运行Docker,tmpfs mount 用于将文件存储在主机的系统内存中。如果你在 Windows 上运行 Docker,命名管道用于将文件存储在主机的系统内存中。
无论选择使用哪种类型的挂载,数据在容器内看起来都是一样的。它在容器的文件系统中公开为一个目录或一个单独的文件。
到底该使用数据卷、绑定挂载还是 tmpfs 挂载,最简单的方法是根据你想把数据存放在 Docker 主机上的什么位置来选择。
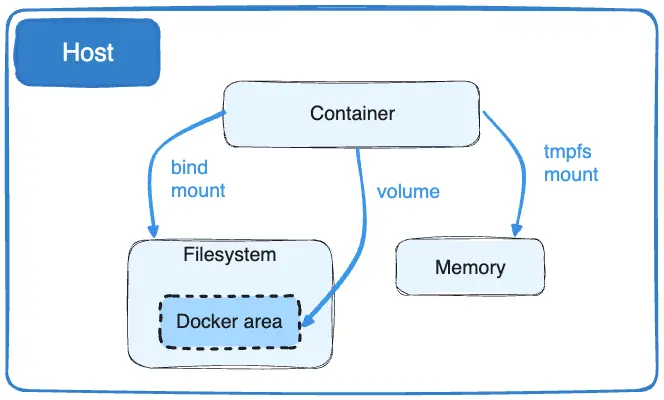
数据卷存储在由 Docker 管理的主机文件系统的一部分中(Linux上的
/var/lib/Docker/Volumes/)。非 Docker 进程不应修改文件系统的这一部分。卷是在Docker中持久化数据的最佳方式。绑定挂载可以存储在主机系统上的任何位置。它们甚至可能是重要的系统文件或目录。Docker 主机或 Docker 容器上的非 Docker 进程可以随时修改它们。
tmpfs挂载只存储在主机系统的内存中,永远不会写入主机系统的文件系统。
绑定挂载和数据卷都可以使用 -v 或 --volume 标志挂载到容器中,但每种语法略有不同。对于 tmpfs 挂载,可以使用 --tmpfs 标志。我们建议对容器和服务、绑定挂载、卷或 tmpfs 挂载都使用 --mount 标志,因为语法更清晰。
一些使用建议
如果将空卷挂载到容器中存在文件或目录的目录中,这些文件或目录就会复制到卷中。同样,如果你启动一个容器并指定一个尚未存在的卷,就会创建一个空卷。这是预先填充另一个容器所需的数据的好方法。
如果将绑定挂载或非空卷挂载到容器中存在某些文件或目录的目录中,这些文件或目录就会被挂载遮挡,就像在 Linux 主机上将文件保存到 /mnt 中,然后将 USB 驱动器挂载到 /mnt 中一样。在 USB 驱动器被卸载之前,/mnt 的内容会被 USB 驱动器的内容遮挡。被遮挡的文件不会被删除或更改,但在绑定挂载或卷标挂载时无法访问。
Volumes
数据卷是保存由 Docker 容器生成和使用的数据的首选机制。虽然绑定挂载依赖于主机的目录结构和操作系统,但数据卷完全由 Docker 管理。与绑定挂载相比,卷有几个优点:
- 卷比绑定挂载更容易备份或迁移。
- 你可以使用 Docker CLI 命令或 Docker API 管理卷。
- 卷可在 Linux 和 Windows 容器上运行。
- 卷可以更安全地在多个容器之间共享。
- 卷驱动程序可让你在远程主机或云提供商上存储卷,加密卷的内容,或添加其他功能。
- 新卷的内容可由容器预先填充。
- 与 Mac 和 Windows 主机上的绑定挂载相比,Docker Desktop 上的卷具有更高的性能。
此外,卷通常比在容器的可写层中持久化数据更好,因为卷不会增加使用它的容器的大小,而且卷的内容存在于给定容器的生命周期之外。
如果容器生成非持久性状态数据,请考虑使用 tmpfs 挂载,以避免将数据永久存储在任何地方,并通过避免将数据写入容器的可写层来提高容器的性能。
注意:
数据卷的使用,类似于 Linux 下对目录或文件进行 mount,镜像中的被指定为挂载点的目录中的文件会复制到数据卷中(仅数据卷为空时会复制)。
创建一个数据卷
格式:docker volume create [OPTIONS] [VOLUME]
❯ docker volume create my-vol查看所有的 volume
格式:docker volume ls [OPTIONS]
❯ docker volume ls
DRIVER VOLUME NAME
local my-vol查看数据卷的详细信息
格式:docker volume inspect [OPTIONS] VOLUME [VOLUME...]
在主机里使用以下命令可以查看指定 volume 的详细信息
❯ docker volume inspect my-vol
[
{
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/my-vol/_data",
"Name": "my-vol",
"Options": {},
"Scope": "local"
}
]启动一个挂载数据卷的容器
在用 docker run 命令的时候,使用 --mount 标记来将 数据卷 挂载到容器里。在一次 docker run 中可以挂载多个 数据卷。
下面创建一个名为 web 的容器,并加载一个 数据卷 到容器的 /usr/share/nginx/html 目录。
❯ docker run -d -P \
--name web \
# -v my-vol:/usr/share/nginx/html \
--mount source=my-vol,target=/usr/share/nginx/html \
nginx:alpine在主机里使用以下命令可以查看 web 容器的信息
❯ docker inspect webvolume信息在 “Mounts” Key 下面
"Mounts": [
{
"Type": "volume",
"Name": "my-vol",
"Source": "/var/lib/docker/volumes/my-vol/_data",
"Destination": "/usr/share/nginx/html",
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
],删除数据卷
格式:docker volume rm [OPTIONS] VOLUME [VOLUME...]
❯ docker volume rm my-volvolume 是被设计用来持久化数据的,它的生命周期独立于容器,Docker 不会在容器被删除后自动删除 数据卷,并且也不存在垃圾回收这样的机制来处理没有任何容器引用的 volume。如果需要在删除容器的同时移除数据卷。可以在删除容器的时候使用 docker rm -v 这个命令。
清理无用数据卷
格式:docker volume prune [OPTIONS]
删除所有未使用的本地卷。未使用的本地卷是没有被任何容器引用的卷。默认情况下,它只删除匿名卷。
❯ docker volume prune
WARNING! This will remove anonymous local volumes not used by at least one container.
Are you sure you want to continue? [y/N] y
Deleted Volumes:
07c7bdf3e34ab76d921894c2b834f073721fccfbbcba792aa7648e3a7a664c2e
my-named-vol
Total reclaimed space: 36 BBind mounts
绑定挂载在 Docker 早期就已存在。与卷相比,绑定挂载的功能有限。使用绑定挂载时,主机上的文件或目录会被挂载到容器中。文件或目录通过其在主机上的绝对路径进行引用。相比之下,使用卷时,会在主机上的 Docker 存储目录中创建一个新目录,并由 Docker 管理该目录的内容。
如果被挂载的 Docker 主机文件或目录不存在,则会按需创建。绑定挂载的性能很高,但它依赖于主机的文件系统是否有可用的特定目录结构。如果你正在开发新的 Docker 应用程序,请考虑使用命名卷。你不能使用 Docker CLI 命令直接管理绑定挂载。
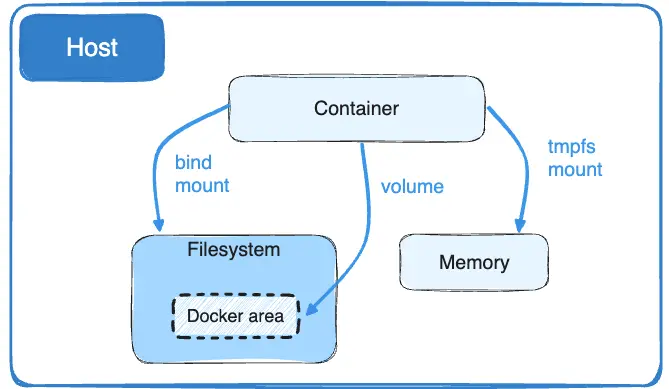
挂载一个主机目录作为数据卷
使用 --mount 标记可以指定挂载一个本地主机的目录到容器中去。
❯ docker run -d -P \
--name web \
# -v /src/webapp:/usr/share/nginx/html \
--mount type=bind,source=/src/webapp,target=/usr/share/nginx/html \
nginx:alpine上面的命令加载主机的 /src/webapp 目录到容器的 /usr/share/nginx/html目录。这个功能在进行测试的时候十分方便,比如用户可以放置一些程序到本地目录中,来查看容器是否正常工作。本地目录的路径必须是绝对路径,以前使用 -v 参数时如果本地目录不存在 Docker 会自动为你创建一个文件夹,现在使用 --mount 参数时如果本地目录不存在,Docker 会报错。
Docker 挂载主机目录的默认权限是 读写,用户也可以通过增加 readonly 指定为 只读。
❯ docker run -d -P \
--name web \
# -v /src/webapp:/usr/share/nginx/html:ro \
--mount type=bind,source=/src/webapp,target=/usr/share/nginx/html,readonly \
nginx:alpine加了 readonly 之后,就挂载为 只读 了。如果你在容器内 /usr/share/nginx/html 目录新建文件,会显示如下错误
/usr/share/nginx/html # touch new.txt
touch: new.txt: Read-only file system查看数据卷的具体信息
在主机里使用以下命令可以查看 web 容器的信息
❯ docker inspect web挂载主机目录的配置信息在 “Mounts” Key 下面
"Mounts": [
{
"Type": "bind",
"Source": "/src/webapp",
"Destination": "/usr/share/nginx/html",
"Mode": "",
"RW": true,
"Propagation": "rprivate"
}
],挂载一个本地主机文件作为数据卷
--mount 标记也可以从主机挂载单个文件到容器中
❯ docker run --rm -it \
# -v $HOME/.bash_history:/root/.bash_history \
--mount type=bind,source=$HOME/.bash_history,target=/root/.bash_history \
ubuntu:18.04 \
bash
root@2affd44b4667:/# history
1 ls
2 diskutil list这样就可以记录在容器输入过的命令了。
tmpfs mounts
数据卷和绑定挂载允许在主机和容器之间共享文件,这样即使在容器停止后,也可以持久保存数据。
如果在 Linux 上运行 Docker,除了上述两种方式外还有第三个选择:tmpfs 挂载。当创建一个带有 tmpfs 挂载的容器时,该容器可以在容器的可写层之外创建文件。
与卷和绑定挂载不同,tmpfs 挂载是临时的,并且只持久存储在主机内存中。当容器停止时,tmpfs 挂载被删除,并且在那里写入的文件不会被持久化。
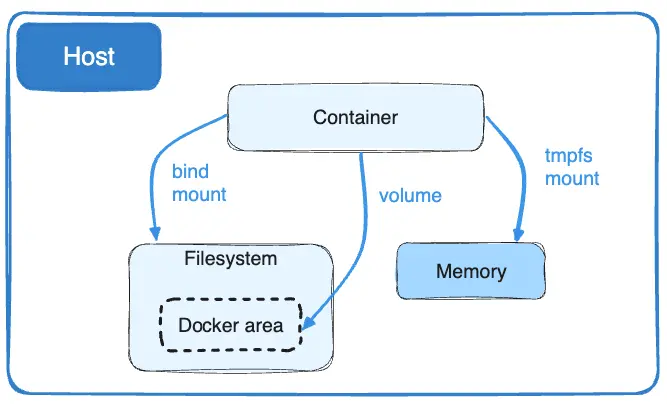
这非常适合临时存储那些不想在主机或容器可写层中持久化的敏感文件。
tmpfs 挂载的限制
与数据卷和绑定挂载不同,不能在容器之间共享
tmpfs挂载。此功能只有在 Linux 上运行 Docker 时才可用。
对
tmpfs设置权限可能导致它们在容器重新启动后重置。在某些情况下,设置 uid/gid 可以作为解决方案。
在容器中使用 tmpfs 挂载
要在容器中使用 tmpfs 挂载,请使用 --tmpfs 标志,或使用带有 type=tmpfs 和目标选项的 --mount 标志。tmpfs 挂载没有 source。
下面的示例在 Nginx 容器中的 /app 处创建了一个 tmpfs 挂载。
使用 --mount 示例:
docker run -d \
-it \
--name tmptest \
--mount type=tmpfs,destination=/app \
nginx:latest使用 --tmpfs 示例
docker run -d \
-it \
--name tmptest \
--tmpfs /app \
nginx:latest通过查看 docker inspect输出的 Mounts 部分,验证该挂载是否为 tmpfs 挂载:
docker inspect tmptest --format '{{ json .Mounts }}'
[{"Type":"tmpfs","Source":"","Destination":"/app","Mode":"","RW":true,"Propagation":""}]停止并移除容器:
docker stop tmptest
docker rm tmptest指定 tmpfs 选项
tmpfs 挂载允许两个配置选项,这两个选项都不是必需的。如果需要指定这些选项,则必须使用 --mount 标志,因为 --tmpfs标志不支持它们。
| 选项 | 说明 |
|---|---|
tmpfs-size | tmpfs 挂载的大小(以字节为单位)。如果未设置,tmpfs 卷的默认最大大小为主机总 RAM 的50% 。 |
tmpfs-mode | tmpfs 的文件模式为八进制。例如,700或0770。默认为1777或者叫 world-writable。 |
下面的示例将 tmpfs-mode 设置为 1770。
docker run -d \
-it \
--name tmptest \
--mount type=tmpfs,destination=/app,tmpfs-mode=1770 \
nginx:latestDocker网络模式
官方相关文档:
Docker 允许通过外部访问容器或容器互联的方式来提供网络服务。
用户定义网络
你可以创建自定义的用户定义网络,并将多个容器连接到同一网络。连接到用户定义的网络后,容器可以使用容器 IP 地址或容器名称相互通信。
下面的示例使用桥接网络驱动程序创建了一个网络,并在创建的网络中运行了一个容器:
❯ docker network create -d bridge my-net
❯ docker run --network=my-net -itd --name=container3 busybox驱动
默认情况下,下列网络驱动程序可用,可提供核心网络功能:
| 网络模式 | 说明 |
|---|---|
bridge | 默认模式。此模式会为每一个容器分配、设置IP等,并将容器连接到一个docker0虚拟网桥,通过docker0网桥以及Iptable nat表配置与宿主机通信 |
host | 容器和宿主机共享Network namespace。 容器直接使用宿主机的IP和端口。 |
none | 将容器与主机和其他容器完全隔离。容器有独立的Network namespace,并没有对其进行任何网络设置。 |
overlay | 利用VXLAN实现的bridge模式,将多个 Docker 守护进程连接在一起。 |
ipvlan | IPvlan 网络可全面控制 IPv4 和 IPv6 寻址。 |
macvlan | 为容器分配 MAC 地址。 |
容器网络
除了用户定义的网络外,还可以使用 --network container:<name|id> 标记格式,将容器直接附加到另一个容器的网络堆栈上。
下面的示例运行 Redis 容器,Redis 绑定到 localhost,然后运行 Redis-cli 命令并通过 localhost 接口连接到 Redis 服务器。
❯ docker run -d --name redis example/redis --bind 127.0.0.1
❯ docker run --rm -it --network container:redis example/redis-cli -h 127.0.0.1公开端口
默认情况下,当你使用 docker create 或 docker run 创建或运行容器时,桥接网络上的容器不会向外界暴露任何端口。使用 –publish 或 -p 标志,可以让桥接网络之外的服务访问某个端口。这会在主机中创建一条防火墙规则,将容器端口映射到 Docker 主机上对外的端口。下面是一些示例:
| Flag value | Description |
|---|---|
-p 8080:80 | 将 Docker 主机上的端口 8080 映射到容器中的 TCP 端口 80。 |
-p 192.168.1.100:8080:80 | 将 Docker 主机 IP 192.168.1.100上的端口 8080 映射到容器中的 TCP 端口 80。 |
-p 8080:80/udp | 将 Docker 主机上的端口 8080 映射到容器中的 UDP 端口 80。 |
-p 8080:80/tcp -p 8080:80/udp | 将 Docker 主机上的 TCP 端口 8080 映射到容器中的 TCP 端口 80,将 Docker 主机上的 UDP 端口 8080 映射到容器中的 UDP 端口 80。 |
Docker Compose
官方相关文档:
Docker Compose 历史
Fig 项目之所以受欢迎,在于它在开发者面前第一次提出了“容器编排”(Container Orchestration)的概念。
其实,“编排”(Orchestration)在云计算行业里不算是新词汇,它主要是指用户如何通过某些工具或者配置来完成一组虚拟机以及关联资源的定义、配置、创建、删除等工作,然后由云计算平台按照这些指定的逻辑来完成的过程。
而容器时代,“编排”显然就是对 Docker 容器的一系列定义、配置和创建动作的管理。而 Fig 的工作实际上非常简单:假如现在用户需要部署的是应用容器 A、数据库容器 B、负载均衡容器 C,那么 Fig 就允许用户把 A、B、C 三个容器定义在一个配置文件中,并且可以指定它们之间的关联关系,比如容器 A 需要访问数据库容器 B。
Fig 就会把这些容器的定义和配置交给 Docker API 按照访问逻辑依次创建,你的一系列容器就都启动了;而容器 A 与 B 之间的关联关系,也会交给 Docker 的 Link 功能通过写入 hosts 文件的方式进行配置。更重要的是,你还可以在 Fig 的配置文件里定义各种容器的副本个数等编排参数,再加上 Swarm 的集群管理能力,一个活脱脱的 PaaS 呼之欲出。
Fig 项目被收购后改名为 Compose,它成了 Docker 公司到目前为止第二大受欢迎的项目,一直到今天也依然被很多人使用。
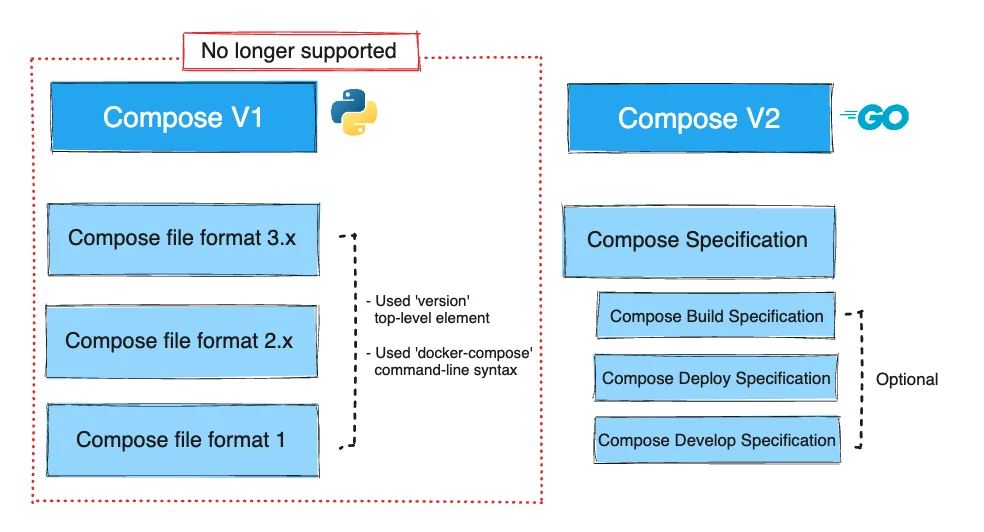
Docker Compose 命令行二进制文件的第一版于2014年首次发布。它是用 Python 编写的,并且使用 docker-compose 进行调用。通常,Compose V1项目在 compos.yml 文件中包含一个顶级版本元素,值范围从2.0到3.8,这些值引用特定的文件格式。
Docker Compose 命令行二进制文件的第二版是在2020年发布的,它是用 Go 编写的,并且使用 Docker Compose 调用。Compose V2忽略 compos.yml 文件中的版本顶级元素。
前面我们已经学习过使用一个Dockerfile模板文件,可以很方便的定义一个单独的应用容器。然而,在日常工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况。例如要实现一个 Web 项目,除了 Web 服务容器本身,往往还需要再加上后端的数据库服务容器或者缓存服务容器,甚至还包括负载均衡容器等。Compose 恰好满足了这样的需求。它允许用户通过一个单独的 docker-compose.yml模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。
Compose 中有两个重要的概念:
- 服务 (service):一个应用的容器,实际上可以包括若干运行相同镜像的容器实例。
- 项目 (project):由一组关联的应用容器组成的一个完整业务单元,在 compose.yaml 文件中定义。
安装
只要你前面安装了Docker Desktop ,默认就已经有 Docker Compose。
因为 Docker Desktop 包括 Docker Compose 以及作为 Compose 先决条件的 Docker Engine 和 Docker CLI。
可以执行以下命令查看你的 Docker Compose。
❯ docker compose version
Docker Compose version v2.21.0-desktop.1如果你用的是Linux环境,且已经安装了Docker Engine 和 Docker CLI ,现在就想单独安装 Docker Compose,那么你可以按这个链接 单独安装 Docker Compose 插件。
使用
使用 Docker Compose,你可以使用一个 YAML 配置文件(称为 Compose 文件)来配置应用程序的服务,然后使用 Compose CLI 从配置中创建并启动所有服务。
compose 文件
Compose文件的默认路径是工作目录中的 compose.yaml(首选)或 compose.yml。Compose 也支持早期版本的 docker-compose.yaml和docker-composite.yml,以实现向后兼容性。如果这两个文件都存在,Compose更喜欢规范的 compose.yaml。
CLI命令
通过 Docker Compose 命令及其子命令与 Docker Compose 应用程序交互。使用 CLI,你可以管理在 compose.yaml 文件中定义的多容器应用程序的生命周期。CLI 命令使你可以毫不费力地启动、停止和配置应用程序。
命令格式:
❯ docker compose [-f <arg>...] [options] [COMMAND] [ARGS...]-f, --file FILE指定使用的 Compose 模板文件,默认为compose.yml,可以指定多个文件。-p, --project-name NAME指定项目名称,默认将使用所在目录名称作为项目名。--verbose输出更多调试信息。-v, --version打印版本并退出。
使用-f 指定一个或多个 Compose 文件的名称和路径
使用 -f 标志指定 Compose 配置文件的位置。
指定多个Compose文件
可以提供多个-f配置文件。当提供多个文件时,Compose会将它们组合成一个配置。Compose按照提供文件的顺序构建配置。后续文件会覆盖并添加到其先前文件中。
例如:
❯ docker compose -f docker-compose.yml -f docker-compose.admin.yml run backup_db其中的docker-compose. yml 文件可能指定一个 webapp 服务。
services:
webapp:
image: examples/web
ports:
- "8000:8000"
volumes:
- "/data"如果docker-compose.admin.yml也指定了相同的服务名,则任何匹配的字段都会覆盖上一个文件。新值,添加到webapp服务配置中。
services:
webapp:
build: .
environment:
- DEBUG=1当使用多个 compose 文件时,文件中的所有路径都相对于用-f指定的第一个配置文件。可以使用--project directory 选项覆盖此基本路径。
-f 标志是可选的。如果不在命令行上提供此标志,Compose 会遍历工作目录及其父目录,查找 compose.yaml 或 docker-compose.yaml 文件。
指定单个Compose文件的路径
可以使用 -f 标志指定不在当前目录中的 Compose 文件的路径,可以从命令行或在 shell 或环境文件中设置 COMPOSE_FILE 环境变量。
对于在命令行中使用 -f 选项的示例,假设正在运行 Compose Rails示例,并且在名为 sandbox/rails 的目录中有一个 compose.yaml 文件。可以使用类似 docker compose pull 的命令,通过使用 -f 标志从任何地方获取db服务的postgres映像,如下所示:
❯ docker compose -f ~/sandbox/rails/compose.yaml pull db使用-p指定项目名称
每个配置都有一个项目名称。Compose 使用以下机制按优先级顺序设置项目名称:
-p命令行标志COMPOSE_PROJECT_NAME环境变量- 配置文件中最上面的
name:变量 (或者由-f指定的一系列文件中最后一个name:) - 包含配置文件(或包含使用
-f指定的第一个配置文件)的项目目录的basename - 如果未指定配置文件,则为当前目录的
bsaename项目名称必须只包含小写字母、十进制数字、破折号和下划线,并且必须以小写字母或十进制数字开头。如果项目目录或当前目录的basename违反了这一限制,则必须使用其他机制之一。
❯ docker compose -p my_project ps -a
NAME SERVICE STATUS PORTS
my_project_demo_1 demo running
docker compose -p my_project logs
demo_1 | PING localhost (127.0.0.1): 56 data bytes
demo_1 | 64 bytes from 127.0.0.1: seq=0 ttl=64 time=0.095 ms使用配置文件启用可选服务
使用 --profile 可以指定一个或多个活动配置文件 调用 docker compose --profile frontend up 可以启动配置文件前端的服务,也可以启动没有指定配置文件的服务。你也可以启用多个配置文件,例如,使用 docker compose --profile frontend --profile debug up 可以启用配置文件 frontend 和 debug。
配置文件也可以通过 COMPOSE_PROFILE 环境变量设置。
配置并行性
使用 --parallel 来指定并发引擎调用的最大并行程度。调用 docker compose --parallel 1 pull 会一次拉取一个在 Compose 文件中定义的可拉取镜像。这也可以用来控制构建的并发性。
并行性也可以通过 COMPOSE_APARALLE_LIMIT 环境变量设置。
设置环境变量
可以为各种docker compose选项设置环境变量,包括-f、-p和--profiles标志。
设置
COMPOSE_FILE环境变量相当于传递-f标志COMPOSE_PROJECT_NAME环境变量与-p标志相同COMPOSE_PROFILE环境变量与--PROFILES标志相同而
COMPOSE_APARALLE_LIMIT与--PARALLEL标志相同
如果在命令行上显式设置了标志,则忽略关联的环境变量。
将COMPOSE_INGORE_ORPHANS 环境变量设置为 true 会阻止 docker compose 检测项目的孤立容器。
使用“Dry Run”模式测试命令
使用 --dry-run 标志在不更改应用程序堆栈状态的情况下测试命令。Dry Run模式显示执行命令时Compose应用的所有步骤,例如:
❯ docker compose --dry-run up --build -d
[+] Running 1/1
✔ DRY-RUN MODE - db Pulled 2.4s
[+] Building 0.0s (0/0) docker:desktop-linux
[+] Running 11/9
✔ DRY-RUN MODE - build service backend 0.0s
✔ DRY-RUN MODE - ==> ==> writing image dryRun-754a08ddf8bcb1cf22f310f09206dd783d42f7dd 0.0s
✔ DRY-RUN MODE - ==> ==> naming to docker-compose-demo-backend 0.0s
✔ DRY-RUN MODE - Network docker-compose-demo_default Created 0.0s
✔ DRY-RUN MODE - Volume "docker-compose-demo_db-data" Created 0.0s
✔ DRY-RUN MODE - Container docker-compose-demo-db-1 Created 0.0s
✔ DRY-RUN MODE - Container docker-compose-demo-backend-1 Created 0.0s
✔ DRY-RUN MODE - Container docker-compose-demo-proxy-1 Created 0.0s
✔ DRY-RUN MODE - Container ocker-compose-demo-db-1 H... 0.0s
✔ DRY-RUN MODE - Container ocker-compose-demo-backend-1 Started 0.0s
✔ DRY-RUN MODE - Container ocker-compose-demo-proxy-1 Started 0.0s 从上面的示例中可以看出,第一步是提取db服务定义的映像,然后构建后端服务。接下来,创建容器。db服务已启动,后端和代理将等待db服务健康后再启动。
干运行模式几乎适用于所有命令。您不能将Dry Run模式与不改变Compose堆栈状态的命令一起使用,例如ps、ls、logs。
核心命令
要启动 compos.yaml 文件中定义的所有服务:
❯ docker compose up停止和删除正在运行的服务:
❯ docker compose down 如果要监视正在运行的容器的输出并调试问题,可以使用以下命令查看日志:
❯ docker compose logs列出所有服务及其当前状态:
❯ docker compose ps子命令
| 命令 | 说明 |
|---|---|
docker compose alpha | 实验命令 |
docker compose build | 构建或重建服务 |
docker compose config | 以规范格式解析、校验和渲染 compose 文件 |
docker compose cp | 在服务容器和本地文件系统之间复制文件/文件夹 |
docker compose create | 为服务创建容器 |
docker compose down | 停止并删除容器、网络 |
docker compose events | 从容器接收实时事件 |
docker compose exec | 在正在运行的容器中执行命令 |
docker compose images | 列出创建的容器使用的镜像 |
docker compose kill | 强制停止服务容器 |
docker compose logs | 查看容器的输出日志 |
docker compose ls | 列出正在运行的 compose 项目 |
docker compose pause | 暂停服务 |
docker compose port | 打印端口绑定的公共端口 |
docker compose ps | 列出容器 |
docker compose pull | 拉取服务镜像 |
docker compose push | 推送服务镜像 |
docker compose restart | 重新启动服务容器 |
docker compose rm | 删除已停止的服务容器 |
docker compose run | 在服务上运行一次性命令 |
docker compose start | 启动服务 |
docker compose stop | 停止服务 |
docker compose top | 展示正在运行的进程 |
docker compose unpause | 取消暂停服务 |
docker compose up | 创建并启动容器 |
docker compose version | 显示Docker Compose版本信息 |
docker compose wait | 阻塞,直到第一个服务容器停止 |
docker compose watch | 监视服务的构建上下文,并在文件更新时重建/刷新容器 |
完整 docker compose 命令请查看 官方文档
使用示例
官方的 https://github.com/docker/awesome-compose 提供了很多示例可供学习。
nginx-golang-mysql 是使用 Nginx 代理和 MariaDB/MySQL 数据库的 Go 服务器示例。
https://github.com/docker/awesome-compose/tree/master/nginx-golang-mysql
项目结构:
.
├── backend
│ ├── Dockerfile
│ ├── go.mod
│ ├── go.sum
│ └── main.go
├── db
│ └── password.txt
├── proxy
│ └── nginx.conf
├── compose.yaml
└── README.md第一步:创建一个简单项目
编写一个简单的 Go 项目,使用 gin 框架和 MySQL。
package main
import (
"database/sql"
"fmt"
"log"
"os"
"time"
"github.com/gin-gonic/gin"
_ "github.com/go-sql-driver/mysql"
)
func connect() (*sql.DB, error) {
bin, err := os.ReadFile("/run/secrets/db-password")
if err != nil {
return nil, err
}
return sql.Open("mysql", fmt.Sprintf("root:%s@tcp(db:3306)/example", string(bin)))
}
func blogHandler(c *gin.Context) {
db, err := connect()
if err != nil {
c.JSON(500, "connect db fail")
}
defer db.Close()
rows, err := db.Query("SELECT title FROM blog")
if err != nil {
c.JSON(500, "query db fail")
}
var titles []string
for rows.Next() {
var title string
err = rows.Scan(&title)
titles = append(titles, title)
}
c.JSON(200, titles)
}
func main() {
log.Print("Prepare db...")
if err := prepare(); err != nil {
log.Fatal(err)
}
log.Print("Listening 8080")
r := gin.Default()
r.GET("/", blogHandler)
r.Run() // 监听并在 0.0.0.0:8080 上启动服务
}
func prepare() error {
db, err := connect()
if err != nil {
return err
}
defer db.Close()
for i := 0; i < 60; i++ {
if err := db.Ping(); err == nil {
break
}
time.Sleep(time.Second)
}
if _, err := db.Exec("DROP TABLE IF EXISTS blog"); err != nil {
return err
}
if _, err := db.Exec("CREATE TABLE IF NOT EXISTS blog (id int NOT NULL AUTO_INCREMENT, title varchar(255), PRIMARY KEY (id))"); err != nil {
return err
}
for i := 0; i < 5; i++ {
if _, err := db.Exec("INSERT INTO blog (title) VALUES (?);", fmt.Sprintf("Blog post #%d", i)); err != nil {
return err
}
}
return nil
}编写 Dockerfile 文件
# syntax=docker/dockerfile:1.4
FROM --platform=$BUILDPLATFORM golang:1.22 AS builder
WORKDIR /code
ENV CGO_ENABLED 0
ENV GOPATH /go
ENV GOCACHE /go-build
COPY go.mod go.sum ./
RUN --mount=type=cache,target=/go/pkg/mod/cache \
GOPROXY=https://goproxy.cn,direct \
go mod download
COPY . .
RUN --mount=type=cache,target=/go/pkg/mod/cache \
--mount=type=cache,target=/go-build \
go build -o bin/backend main.go
CMD ["/code/bin/backend"]
FROM builder AS dev-envs
RUN <<EOF
apk update
apk add git
EOF
RUN <<EOF
addgroup -S docker
adduser -S --shell /bin/bash --ingroup docker vscode
EOF
# install Docker tools (cli, buildx, compose)
COPY --from=gloursdocker/docker / /
CMD ["go", "run", "main.go"]
FROM scratch
COPY --from=builder /code/bin/backend /usr/local/bin/backend
CMD ["/usr/local/bin/backend"]第二步:在 compose 文件中定义服务
Compose 使我们能够在一个易于理解的 YAML 配置文件中管理服务、网络和卷。
在项目目录中创建一个名为 compose.yaml 的文件,内容如下。
services:
backend:
build:
context: backend
target: builder
secrets:
- db-password
depends_on:
db:
condition: service_healthy
db:
# We use a mariadb image which supports both amd64 & arm64 architecture
image: mariadb:10-focal
# If you really want to use MySQL, uncomment the following line
#image: mysql:8
command: '--default-authentication-plugin=mysql_native_password'
restart: always
healthcheck:
test: ['CMD-SHELL', 'mysqladmin ping -h 127.0.0.1 --password="$$(cat /run/secrets/db-password)" --silent']
interval: 3s
retries: 5
start_period: 30s
secrets:
- db-password
volumes:
- db-data:/var/lib/mysql
environment:
- MYSQL_DATABASE=example
- MYSQL_ROOT_PASSWORD_FILE=/run/secrets/db-password
expose:
- 3306
proxy:
image: nginx
volumes:
- type: bind
source: ./proxy/nginx.conf
target: /etc/nginx/conf.d/default.conf
read_only: true
ports:
- 80:80
depends_on:
- backend
volumes:
db-data:
secrets:
db-password:
file: db/password.txtcompose 文件定义了三个服务(service):backend、db和proxy。
部署应用程序时,docker compose将代理服务容器的端口80映射到文件中指定的主机的端口80。确保主机上的端口80尚未被使用。
第三步:使用Compose构建和运行您的应用程序
只需一个命令,你就可以从配置文件中创建并启动所有服务。
从项目目录中,通过运行 docker compose up 启动应用程序
❯ docker compose up
[+] Building 4.2s (13/13) FINISHED docker:desktop-linux
=> [backend internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 900B 0.0s
=> [backend internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [backend] resolve image config for docker.io/docker/dockerfile:1.4 1.4s
=> CACHED [backend] docker-image://docker.io/docker/dockerfile:1.4@sha256:9ba7531bd80fb0a858632727cf7a112fbfd19b17e9 0.0s
=> [backend internal] load metadata for docker.io/library/golang:1.22 1.2s
=> [backend builder 1/6] FROM docker.io/library/golang:1.22@sha256:367bb5295d3103981a86a572651d8297d6973f2ec8b62f716 0.0s
=> [backend internal] load build context 0.0s
=> => transferring context: 2.67kB 0.0s
=> CACHED [backend builder 2/6] WORKDIR /code 0.0s
=> CACHED [backend builder 3/6] COPY go.mod go.sum ./ 0.0s
=> [backend builder 4/6] RUN --mount=type=cache,target=/go/pkg/mod/cache GOPROXY=https://goproxy.cn,direct g 0.6s
=> [backend builder 5/6] COPY . . 0.0s
=> [backend builder 6/6] RUN --mount=type=cache,target=/go/pkg/mod/cache --mount=type=cache,target=/go-build 0.4s
=> [backend] exporting to image 0.5s
=> => exporting layers 0.5s
=> => writing image sha256:0be40110019bd5cfc415c90791a66123c5828288ab1b9876e7dd990661b58ff9 0.0s
=> => naming to docker.io/library/docker-compose-demo-backend 0.0s
[+] Running 5/3
✔ Network docker-compose-demo_default Created 0.0s
✔ Volume "docker-compose-demo_db-data" Created 0.0s
✔ Container docker-compose-demo-db-1 Created 0.1s
✔ Container docker-compose-demo-backend-1 Created 0.0s
✔ Container docker-compose-demo-proxy-1 Created 0.0s或者使用 docker compose up -d
❯ docker compose up -d
[+] Running 3/3
✔ Container docker-compose-demo-db-1 Healthy 0.0s
✔ Container docker-compose-demo-backend-1 Started 0.0s
✔ Container docker-compose-demo-proxy-1 Started 0.0s列出的容器必须显示三个正在运行的容器和端口映射,如下所示
❯ docker compose ps
NAME COMMAND SERVICE STATUS PORTS
nginx-golang-mysql-backend-1 "/code/bin/backend" backend running
nginx-golang-mysql-db-1 "docker-entrypoint.s…" db running (healthy) 3306/tcp
nginx-golang-mysql-proxy-1 "/docker-entrypoint.…" proxy running 0.0.0.0:80->80/tcp
l_db_1停止并移除容器
❯ docker compose down
[+] Running 4/4
✔ Container docker-compose-demo-proxy-1 Removed 0.1s
✔ Container docker-compose-demo-backend-1 Removed 0.1s
✔ Container docker-compose-demo-db-1 Removed 0.3s
✔ Network docker-compose-demo_default Removed 0.1s 命令说明
https://github.com/compose-spec/compose-spec/blob/main/spec.md
默认的模板文件名称为 compose.yaml,格式为 YAML 格式。
services:
webapp:
image: examples/web
ports:
- "80:80"
volumes:
- "/data"注意每个服务都必须通过 image 指令指定镜像或 build 指令(需要 Dockerfile)等来自动构建生成镜像。
如果使用 build 指令,在 Dockerfile 中设置的选项(例如:CMD, EXPOSE, VOLUME, ENV 等) 将会自动被获取,无需在 compose.yml 中重复设置。
下面分别介绍常用指令的用法。
build
指定 Dockerfile 所在文件夹的路径(可以是绝对路径,或者相对 compose.yaml 文件的路径)。 Compose 将会利用它自动构建这个镜像,然后使用这个镜像。
可以使用 context 指令指定 Dockerfile 所在文件夹的路径。
使用 dockerfile 指令指定 Dockerfile 文件名。
使用 arg 指令指定构建镜像时的变量。
command
覆盖容器启动后默认执行的命令。
depends_on
解决容器的依赖、启动先后的问题。以下例子中会先启动 redis、 db 再启动 web
services:
web:
build: .
depends_on:
- db
- redis
redis:
image: redis
db:
image: postgres注意:
web服务不会等待redisdb「完全启动」之后才启动。通常需要搭配健康检查等策略等待依赖服务可用后再启动。
healthcheck
通过命令检查容器是否健康运行。
healthcheck:
test: ['CMD-SHELL', 'mysqladmin ping -h 127.0.0.1 --password="$$(cat /run/secrets/db-password)" --silent']
interval: 3s
retries: 5
start_period: 30simage
指定为镜像名称或镜像 ID。如果镜像在本地不存在,Compose 将会尝试拉取这个镜像。
environment
设置环境变量。你可以使用数组或字典两种格式。
只给定名称的变量会自动获取运行 Compose 主机上对应变量的值,可以用来防止泄露不必要的数据。
expose
暴露端口,但不映射到宿主机,只被连接的服务访问。
仅可以指定内部端口为参数
secrets
存储敏感数据,例如 mysql 服务密码。
secrets:
db-password:
file: db/password.txtvolumes
数据卷所挂载路径设置。可以设置为宿主机路径(HOST:CONTAINER)或者数据卷名称(VOLUME:CONTAINER),并且可以设置访问模式 (HOST:CONTAINER:ro)。
相关扩展概念
LXC:LXC(LinuX Containers)于 2008 年推出,是 Linux 上第一个上游内核的容器。Docker 的第一个版本使用了 LXC,但在后来的发展中,由于已经实现了 runc,所以 LXC 被移除了。
CRI:CRI(Container Runtime Interface)是 K8s 定义的一组与容器运行时进行交互的接口,用于将 K8s 平台与特定的容器实现解耦。在 K8s 早期的版本中,对于容器环境的支持是通过 hard code 方式直接调用 Docker API 的,后来为了支持更多的容器运行时和更精简的容器运行时,K8s 提出了CRI。
OCI:OCI(Oracle Call Interface)是个自下而上的标准,也就是从实现抽象出接口,它发布镜像和容器的规范。它于 2015 年由 Docker 发起,并被微软、Facebook、英特尔、VMWare、甲骨文和许多其他行业巨头接受。Docker 实现的核心 RunC,也就是 OCI 的典型实现、标准实现。
Containerd:Containerd 是由 Docker 团队开源的容器运行时,它专注于提供轻量级、高性能的容器运行环境。作为一个纯粹的容器运行时,Containerd 被设计为更加符合K8s的架构和需求。
runc:runc 是 OCI 规范的参考实现。它创建并运行容器以及其中的进程。它使用较低级别的 Linux 特性,比如 cgroup 和命名空间。
CRI-O:CRI-O 是一个纯粹为 Kubernetes 设计的容器堆栈,是 CRI 标准的第一个实现。它从任何容器镜像仓库中 提取镜像,可以作为使用 Docker 的轻量级替代方案。
podman:Pod Manager 是一个由RedHat公司推出的容器管理工具,它的定位就是 Docker 的替代品,在使用上与 Docker 的体验类似。podman 源于CRI-O项目,可以直接访问OCI的实现(如runC),流程比 Docker 要短。
rkt:由 CoreOS 主推的用来跟 Docker 抗衡的容器运行时。
—— 七米 Go 语言微服务课程课件 ——
正如你无法只通过观看视频学会游泳,你也无法只通过观看视频学会编程。
一定要 coding 起来,加油!更多 Go 语言学习内容👉 liwenzhou.com
参考资料
- https://github.com/opencontainers/runc/blob/main/libcontainer/network_linux.go
- https://medium.com/swlh/build-containers-from-scratch-in-go-part-1-namespaces-c07d2291038b
- https://github.com/MoimHossain/scratch-container/blob/master/demo.go
- https://www.youtube.com/watch?v=JOsWB50LmwQ
- https://medium.com/@m.elqrwash/creating-a-minimal-container-in-go-a-step-by-step-guide-755e09464fec
- https://www.freedium.cfd/https://medium.com/swlh/build-containers-from-scratch-in-go-part-1-namespaces-c07d2291038b
- https://readmedium.com/en/https:/medium.com/swlh/build-containers-from-scratch-in-go-part-1-namespaces-c07d2291038b
- https://blog.ewocker.com/blog/container-docker/02