M09 Context Engineering(上下文工程)
M03 3.4已经建立了一个基本认识:上下文是有限的注意力预算,不能因为窗口足够大,就把所有可用信息都放进去。完成 M04 Agent 循环、M06 工具系统、M07 知识检索和 M08 多智能体协作后,系统也会出现新的工程问题:历史持续增长、工具返回大段文本、检索片段占用窗口、工具定义不断增加。
本章讨论如何系统治理这些信息。我们会把 Token 预算、历史压缩、工具结果外置、动态工具暴露、结构化笔记和 Prompt Caching 等手段落到一个可复用的 ctxeng 包中,使 Agent 在长会话和长任务中保持可控的质量、延迟与成本。
学习目标与模块定位
学完本章,你能够:
- 说清上下文膨胀的四大来源,并用一条总纲统领治理手段;
- 实现 Token 预算控制,在组装上下文前核对各部分占用并触发治理;
- 实现历史压缩(Compaction),让长会话保持有界;
- 实现工具结果压缩与文件外置,避免大块内容长期占用上下文;
- 实现动态工具暴露,治理工具定义膨胀;
- 用结构化笔记 + 子 Agent 隔离保留结论级信息;
- 用 Prompt Caching 与 Citations 降低成本和延迟,并把这些手段串成可持续运行的治理流程。
前置内容包括 M03 的注意力预算、M04 的 Agent 循环与状态、M06 的工具系统、M07 的 RAG以及 M08 的多智能体隔离。本章是这些能力之上的治理层。
配套练习是给一个会累积历史、且带有大文本工具结果的简易 Agent 加入上下文治理,对比治理前后的 token 占用。
9.1 上下文工程
在介绍治理手段之前,需要先建立起一个基础概念。这一节先不写代码,重点说明 Context Engineering 为什么成为一项独立的工程工作、上下文窗口有哪些边界、长上下文会出现什么问题,以及它与 Prompt Engineering、Memory 和 RAG 的关系。
为什么需要上下文工程
2023 年,常见模型的上下文窗口多在 4K~16K。到 2026 年,主流供应商已经提供数十万乃至 1M token 量级的窗口。窗口扩大确实能容纳更多信息,但它不能自动解决信息选择、位置安排、调用成本和长任务状态维护等问题。
实际使用中至少要面对四类问题。
信息过多可能降低效果
对于同一个问题,把相关资料放在 prompt 开头、中间或结尾,模型利用信息的效果可能不同。Lost in the Middle 论文展示了明显的首尾优势:关键信息位于长上下文中部时,模型的检索与问答表现往往下降。接近上限的 100K 上下文中,关键信息放中间时模型常常无法稳定利用;这个长度不是通用阈值。后文会展开这一现象。
信息过多会增加成本
LLM 通常按 token 计费。输入从 4K 增长到 128K,token 数增加 32 倍;与此同时,服务端还要承担更大的预填充计算、KV Cache 和网络传输开销。单次对话的成本可能出现显著增长,真实费用取决于模型和缓存命中率;在百万级日活场景中,即使很小的单次增量也会显著放大。大模型厂商还可能对超长输入采用分档计价,因此生产系统不能只看窗口上限,还要看实际账单。
信息过多会增加延迟
原生 Transformer 的全注意力计算复杂度是 O(n²)。在推理阶段,prefill(预填充)需要处理全部输入并建立 KV Cache,因此首 token 延迟(time to first token,TTFT)通常会随上下文增长;KV Cache 的内存占用通常也随长度增长;decode(逐 token 生成)则会受到 KV Cache 大小与内存带宽的影响。具体增幅取决于模型架构、Flash Attention、Paged Attention 等实现、缓存方式和硬件,但整体趋势是确定的:上下文越长,首字延迟越长、单次调用越贵。流式输出能改善生成阶段的感知延迟,却不能消除 prefill 开销。
超过窗口上限会直接失败
Agent 运行长会话或执行多轮工具调用时,历史消息会持续累积。比如:10 轮约 50K、第 30 轮约 150K,实际数值取决于每轮消息和工具结果大小。若不做压缩、截断或外置,输入最终会超过模型限制,并触发类似 context length exceeded 的错误。
这四类现象说明:上下文不能只以“是否装得下”为判断标准。它是有限的资源,要像 CPU / 内存 / 带宽一样被主动治理——这就是 Context Engineering 这个学科。
2024 年以后,Context Engineering 逐渐成为 Agent 工程讨论中的独立主题。Anthropic 将它描述为:在模型推理期间,策划并维护一组最合适的 token 的策略集合。与主要关注单次提示写法的 Prompt Engineering 相比,它处理的是 Agent 多轮运行中的信息选择、压缩、路由与复用。
模型决定能力边界,Context Engineering 决定这些能力能否被稳定利用。
模型能力由所选模型决定;放入什么信息、放入多少、放在什么位置、何时放入、是否提前压缩,则属于工程决策。M04 4.1的 harness 概念在这里再次出现:模型提供基础能力,Context Engineering 负责让这些能力稳定、可控地发挥出来。
上下文的组成
要治理上下文,先理解它包含什么。一次模型调用的上下文(context),是本次请求中放进 prompt 中的所有输入 token 的总和。
常见上下文由以下几部分组成:
一次模型调用的上下文 =
System 提示词 ← 指令、人格、规则、行为约束
+ 工具定义 ← M06:每个工具的名/描述/参数 Schema
+ 对话历史 ← M04 的 Messages:user/assistant/tool 多轮交错
+ 检索片段 ← M07 的 RAG:从 KB 召回的若干 chunk
+ 工具结果 ← M06:工具调用的返回(可能很大)
+ 当前用户输入 ← 这一轮用户问的话
+ 中间笔记 / 子 Agent 摘要 ← M08:协作产物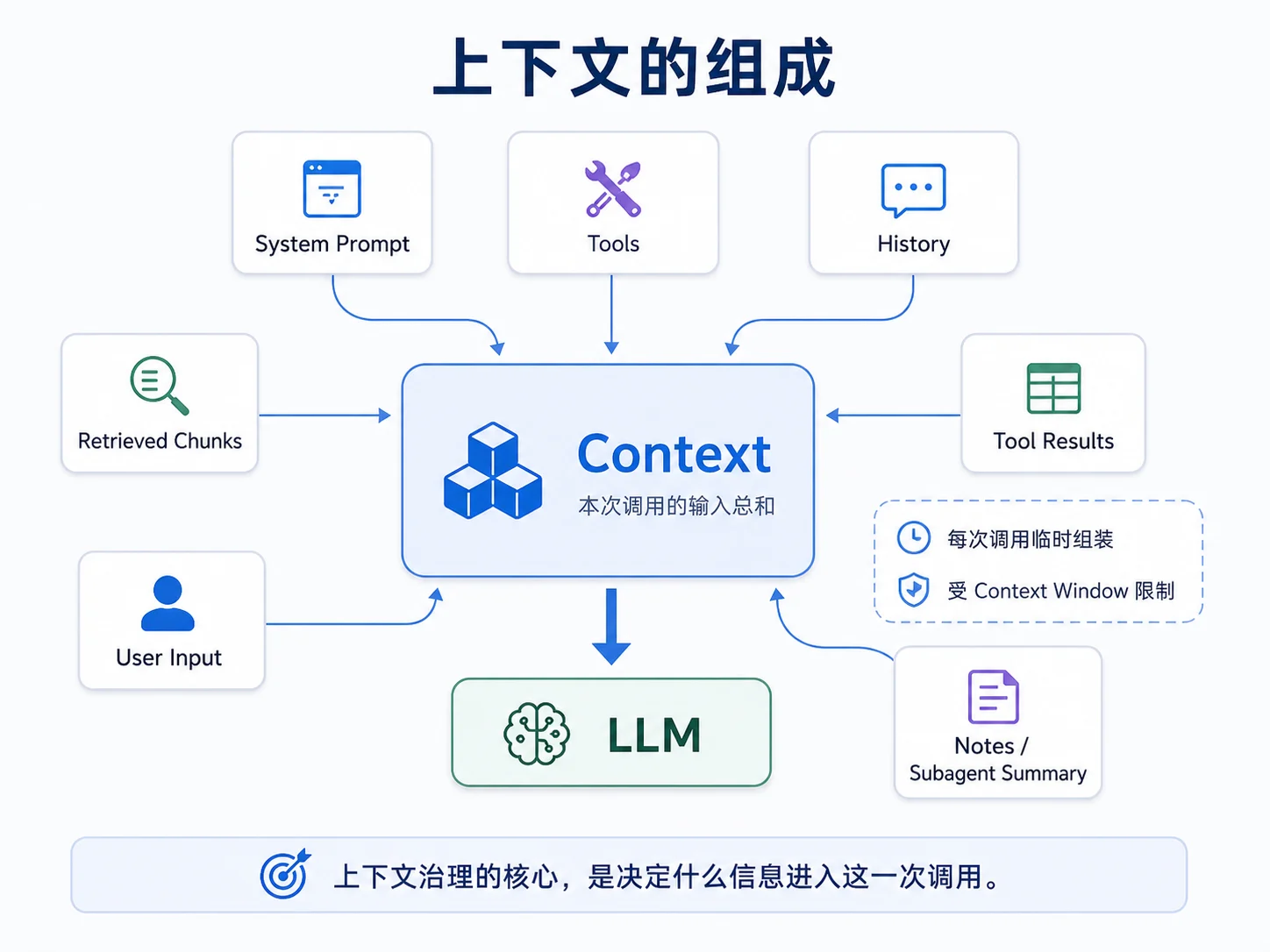
这七部分必须共同装入 context window。工程上需要同时考虑三层边界:
- 物理边界:模型允许的最大上下文长度;
- 经济边界:一次调用可以接受的费用与延迟;
- 有效边界:在特定模型、任务和信息布局下,仍能保持目标质量的上下文范围。
物理边界是 API 的硬性限制;成本边界和效果边界则需要团队根据业务目标、评估集与成本预算确定。后面的 Token 预算门控器,应当在触及物理上限之前触发治理。
上下文窗口的物理限制
先看物理边界。下表是截至 2026 年 6 月 14 日的主流厂商大模型的模型规格和计费规则。(此信息变化较快,建议查询最新供应商文档获取最新规则)
| 模型 | 上下文与输出上限快照 | 官方文档 |
|---|---|---|
| Claude Opus 4.8 | Anthropic API、Amazon Bedrock 和 Google Vertex AI 上最高 1M context,最大输出 128K;其他平台可能不同 | Claude 4.8 文档 |
| GPT-5.5 | 1,050,000 context,最大输出 128,000;超长输入采用分档计价 | GPT-5.5 模型页 |
| Gemini 3 / 3.5 系列 | 输入窗口可达 1M,最大输出长度随具体模型而异 | Gemini 长上下文文档 |
| DeepSeek V4 Flash / Pro | 官方定价页列出 1M context | DeepSeek 定价文档 |
| Kimi / 智谱 GLM / 阿里 Qwen | 各模型与部署平台差异较大,不在课件中固化单一数值 | 各家开放平台的当前模型页 |
为什么窗口不是无限大?核心在于 Transformer 注意力机制的复杂度。下面的数字只用于说明全注意力的数量级,不代表某个具体模型的真实计算量:
Attention 复杂度 = O(n²)
n = 输入 token 数
n= 4K: 16M 次注意力计算
n= 32K: 1024M 次
n=128K: 16384M 次
n= 1M: 1000000M 次 (相当于 4K 的 62500 倍)原生全注意力下每一层 Transformer 都要每个 token 与所有其他 token 互相计算,n 翻倍意味着注意力的乘加操作粗略翻 4 倍(实际放大倍数受具体实现、缓存与 IO 优化影响)。这是为什么模型厂商不直接给"无限窗口"——既算不动,也存不下(KV cache 内存随长度线性增长)。
业界用各种技巧软化这个 O(n²):
- Flash Attention(I/O 优化,常数项变小)
- Ring Attention(分布式)
- Sparse Attention(稀疏化)
- Sliding Window(局部窗口)
- Linear Attention(线性近似)
- Grouped-Query Attention(GQA / MQA,共享 KV)
但核心瓶颈一直都在,目前尚无法彻底解决。这就是为什么实际使用 1M 上下文窗口时,模型的延迟显著上升、成本明显增长。
对实际的工程侧的使用来说,即使供应商提供 1M token 窗口,也不能据此假设 1M token 内的所有位置和所有信息都能被同等利用。通常前 200K 内质量最稳定,200K-500K 质量开始波动,500K 以上波动很大。团队应使用自己的任务集测量质量、TTFT、吞吐和成本,并据此确定预算。
长上下文的三种典型现象
前面提到信息过多可能降低效果。理解下面三种现象,有助于把“长上下文”从规格参数转化为可测试的工程问题。
Lost in the Middle(中间遗忘)
Liu 等人在 2023 年发表了 Lost in the Middle: How Language Models Use Long Contexts。该研究来自 Stanford 与 UC Berkeley 的研究者,通过多文档问答和键值检索等任务,考察相关信息处于不同位置时的模型表现。
把 20 篇文档放进 prompt,正确答案藏在其中一篇里。然后改变正确答案文档的位置(开头 / 中间 / 结尾),看模型准确率。( 使用下面的近似数据展示典型的 U 形趋势,帮助理解位置效应)
位置: 准确率
─────────────────────────────
开头(第 1 篇) ~75%
第 3 篇 ~70%
第 5 篇 ~63%
中间(第 10 篇) ★ ~50% ← 显著低谷
第 15 篇 ~58%
结尾(第 20 篇) ~70%
─────────────────────────────论文的核心结论是:部分长上下文模型在相关信息位于开头或结尾时表现较好,位于中间时表现下降。GPT-4、Claude、Gemini 都验证过这个现象。
工程侧得到的经验是组织 RAG 返回的 top-K chunk 时,不应只关注召回结果,还要评估排序和位置。别按相关度顺序直接往上下文里堆,要把最相关的放最前面或最后面,别让它们扎堆在中间。
Context Rot(上下文腐烂)
Context Rot 是 2024 年以后逐渐流行的工程术语,用来描述这样一种现象:随着上下文变长、噪声增多或多轮状态不断叠加,模型正确利用已有信息的能力可能下降。
在实际测试中,在多轮对话里(Agent 运行 20 轮以上)对话开头的 system 指令、用户最初的需求,在 10 轮后被模型"忘掉"的概率显著上升。模型开始按最近几轮的语言风格、语气倾向回答,无视开头的约束。
得到的工程经验是:重要约束(安全规则、输出格式、人物设定)不能只放在开头发一次。系统应把稳定规则保留在受控的 system 区域,必要时在每轮重新注入关键约束,把任务状态沉淀为结构化笔记,并通过评估确认压缩和重组没有破坏约束。
Attention Dilution(注意力稀释)
注意力是有限资源。如果上下文里相关信息占比 80%,模型大概率能"看得清";如果占比降到 5%(被一大堆不相关信息淹没),大模型即便能"看见"也容易"看错"——它分到每条信息的注意力变少。
可以把它类比为会议沟通:你在一个十人会议上找人讨论一件事很顺利;在一个一千人会议上,即便对方就站在你旁边沟通效率也会显著下降。空间没有变,但有效信号被噪声稀释。
工程上能得到的经验就是放进上下文的信息密度要高。应该优先保留少量高相关信息,避免堆积低相关内容。RAG top-K 调到 30 不如调到 5 + reranker;工具定义放 50 个不如动态暴露 10 个。
三个现象的共同结论
这三个现象都指向同一个结论:注意力 ≠ token。
- Token 是空间(上下文窗口里的位置)
- 注意力是有效空间(模型实际能聚焦的部分)
大模型上下文的有效空间远小于物理空间,这是 Context Engineering 与"上下文窗口扩大"是两件事的根本原因。上下文窗口可以扩,但注意力不会自动跟着扩。Context Engineering 的任务,是通过选择、压缩、排序和外置,让有限输入空间承载更高价值的信息。
上下文膨胀的原因
理解了为什么必须筛选信息,再看 Agent 的上下文如何膨胀。前面的七个组成部分中,主要有四类会持续增长:
一次调用的上下文 =
System 提示词 ← 相对稳定,一般不膨胀
+ 工具定义 ← ★ 膨胀源 1:工具一多就膨胀(M06;一个大 MCP Server 可占上万 token)
+ 对话历史 ← ★ 膨胀源 2:随轮次【线性增长】,最持续的膨胀源(M04)
+ 检索片段 ← ★ 膨胀源 3:一篇长文档就吃几千 token(M07)
+ 工具结果 ← ★ 膨胀源 4:一次返回大段文本(读文件/查表)瞬间撑爆
+ 当前输入 ← 一般几十到几百 token,可忽略
+ 中间笔记 / 摘要 ← 受结构化笔记治理,理论上有界四类膨胀源具有不同的增长方式,也需要不同的治理手段:
| 膨胀源 | 何时严重 | 主要治理手段 | 课程对应 |
|---|---|---|---|
| 对话历史 | 长会话(如 10 轮以上) | 压缩 / 总结 / 滚动窗口 | 历史压缩 |
| 工具结果 | 读文件 / 查表 / 大列表 | 截断 / 摘要 / 文件外置 | 工具结果压缩与文件外置 |
| 工具定义 | 工具集较大(如 20 个以上) | 动态暴露 / 分组 / 路由 | 动态工具暴露 |
| 检索片段 | RAG top-K 调大 | 调小 + Rerank + 摘要和重排 | RAG 与历史压缩 |
上述四类膨胀问题如果放任不管,很快就会带来延迟增加、成本上升、效果下降的问题,严重时还会直接超出窗口。
上下文工程的定义
可以用下面的公式概括 Context Engineering 的主要工作:
Context Engineering = Selection + Compression + Routing + Caching
Selection: 选什么放进 prompt(从大量可用信息里挑)
Compression: 压缩准备放入的信息(总结、截断、提取关键)
Routing: 什么时候放入、放到哪里(动态决策)
Caching: 复用可以缓存的稳定前缀(Prompt Cache 复用)这四类工作分别回答“选什么”“如何缩短”“何时放入、放在哪里”和“哪些计算可以复用”。它治理的不是一段静态 prompt,而是 Agent 跨多次调用流动的上下文。
上下文治理应该遵循一个原则:
让常驻上下文只保留此刻必需的、结论性的信息;把过程性信息和可按需取回的信息放到上下文之外。
后面的压缩、外置、动态暴露、笔记和隔离,都是这条原则在不同膨胀源上的实现。
与 Prompt Engineering 区别
Context Engineering 与 Prompt Engineering 的区别:
- Prompt Engineering:关注单次调用的 prompt 设计,包括结构、变量、模板、few-shot 和推理要求等;
- Context Engineering:关注跨多次调用的上下文流,包括选择、压缩、外置、动态暴露和缓存。
两者不冲突。Prompt Engineering 负责把选中的信息表达清楚,Context Engineering 还要决定哪些信息能够进入这次调用。
关键概念辨析
下面四个术语经常被混用,需要分别理解。
Token 预算与注意力预算
| Token 预算 | 注意力预算 | |
|---|---|---|
| 是什么 | Context Window 的物理空间 | 模型有效消化能力 |
| 边界 | 模型规格(如 128K / 1M) | 由模型、任务与信息布局共同决定 |
| 超出时 | API 报错 | 准确率下降、Lost in the Middle |
| 监控 | tiktoken 计数 | 评估集 + benchmark |
Token 预算只是硬性上限,注意力预算才是有效上限。M03 3.4所说的"上下文是注意力预算"就是这个意思。Token 预算控制器要控制的实际上是注意力预算,通常设在物理边界的 60-80%。
KV Cache 与 Prompt Cache
两个名称相似,但所在层次不同。
KV Cache(Key-Value Cache)是推理服务内部使用的缓存:
- 通常位于加速器内存或分层缓存中,由推理系统维护;
- 保存各层已经计算的 Key 和 Value;
- 避免自回归生成时重复计算此前 token 的部分结果;
- 应用开发者通常不能直接控制其内部实现;
- 超长上下文的 KV Cache 可能达到数十 GB,但具体数值取决于模型规模、层数、KV 头数、精度和服务端优化。
Prompt Cache(Prefix Cache)是供应商在 API 层提供的前缀复用能力:
- Anthropic、OpenAI 和 Google 都提供了相应能力;
- 服务端识别相同或可复用的稳定前缀,减少重复处理;
- 不同供应商的控制方式不同:Anthropic 支持自动缓存和显式
cache_control,OpenAI 对满足条件的请求自动启用,Google 同时提供隐式与显式缓存; - 命中后通常可以降低输入成本和 TTFT,具体折扣、生命周期与最小 token 要求以当前文档为准。
概念上,Prompt Cache 复用了稳定前缀的计算结果;供应商是否直接保存 KV、如何分层存储,属于服务端实现细节,不能仅凭 API 名称作统一假设。
工程含义如下:
- KV Cache 由模型服务内部管理,应用侧主要关注它对延迟和容量的影响;
- Prompt Cache 可以通过请求结构进行规划,应将 system、工具定义、L1 Skill 注入等稳定内容组织在前缀位置。
上下文治理

接下来的每一节都针对前面总结的膨胀源,落实一种治理手段:
| 节 | 主题 | 解决哪个膨胀源 | 治理手法 |
|---|---|---|---|
| Token 预算门控 | Token 预算门控 | 跨四源 | 入口拦截:Token 预算门控器 |
| 历史压缩 | 历史压缩 Compaction | 对话历史 | Compression |
| 工具结果压缩与文件外置 | 工具结果压缩与文件外置 | 工具结果 | Compression + Externalize |
| 动态工具暴露 | 工具定义膨胀治理 | 工具定义 | Selection(动态暴露)+ Routing |
| 结构化笔记与子 Agent 隔离 | 结构化笔记与子 Agent 隔离 | 跨四源 | Compression + Isolation |
| Prompt Caching 与 Citations | Prompt Caching 与 Citations | 跨四源 | Caching |
| 上下文治理流程 | 用 harness 串联 | 跨四源 | 整合 |
这些手段并非孤立技巧。它们共同服务于同一原则:常驻上下文只保留当前必需的结论性信息,其余内容压缩、外置或按需取回。
下面进入工程主线,从 Token 预算控制开始,把这些能力逐步落到 internal/ctxeng 包中。
9.2 Token 预算控制
M03 3.4建立了“给上下文各部分划预算”的思路。本节把它变成可以执行约束的工程控制器:每次组装上下文之前,估算各部分占用;一旦超标,就触发对应治理。
先实现一个低成本估算器。它适合做早期控制,但不能替代供应商 tokenizer 或 API 返回的真实 usage:
package ctxeng
// EstimateTokens 粗略估算 token:英文约 4 字符/token,中文约 1.5 字符/token。
func EstimateTokens(s string) int {
ascii, cjk := 0, 0
for _, r := range s {
if r < 128 {
ascii++
} else {
cjk++
}
}
return ascii/4 + cjk*2/3 + 1
}再实现预算表和超标检测。Over 返回各部分超出多少,上层据此决定触发哪种治理:历史超标时执行 Compaction,检索片段超标时减少召回或先 rerank,工具定义超标时执行动态暴露。
package ctxeng
// Budget 描述一次模型调用里各部分的 token 上限(0 表示不限)。
type Budget struct {
Total int
SystemPrompt int
Tools int
History int
Retrieved int
}
// Over 返回各部分超出预算的量(map 里出现即超标),是触发治理的信号。
func (b Budget) Over(systemPrompt, tools, history, retrieved string) map[string]int {
over := map[string]int{}
chk := func(name, text string, limit int) {
if limit > 0 {
if n := EstimateTokens(text); n > limit {
over[name] = n - limit
}
}
}
chk("system", systemPrompt, b.SystemPrompt)
chk("tools", tools, b.Tools)
chk("history", history, b.History)
chk("retrieved", retrieved, b.Retrieved)
return over
}预算的价值不在于一次估算完全精确,而在于强制每部分都有边界、超标后有动作。当前示例还保留了 Budget.Total 字段,但 Over 只检查分项预算;落到生产代码时,还应补充总量检查,并为模型最大输出预留空间。最后一节会把门控器与其他手段串成完整的组装流程。
9.3 历史压缩
最持续的膨胀源是对话历史 Messages:每轮都会追加模型输出、工具调用和工具结果,长对话最终会逼近上下文窗口上限。
Compaction 是长会话治理的核心手段:当历史逼近预算时,把较早内容高保真地总结为摘要,再用“摘要 + 最近几轮原文”构造精简上下文,使任务继续运行。
package ctxeng
import (
"context"
"github.com/yourname/llmagent/internal/llm"
)
// Compact 把较早消息高保真总结为一条摘要,保留 system + 最近 keepRecent 条原文。
// summarize 是一次模型调用,做成依赖便于测试注入假实现。
func Compact(
ctx context.Context,
messages []llm.Message,
keepRecent int,
summarize func(ctx context.Context, older []llm.Message) (string, error),
) ([]llm.Message, error) {
if len(messages) <= keepRecent+1 {
return messages, nil // 还不长,无需压缩
}
system := messages[0] // 约定 [0] 是 system,必须保留
older := messages[1 : len(messages)-keepRecent] // 较早部分 → 压缩
recent := messages[len(messages)-keepRecent:] // 最近 keepRecent 条 → 保留原文
summary, err := summarize(ctx, older)
if err != nil {
return nil, err
}
out := make([]llm.Message, 0, 2+keepRecent)
out = append(out, system)
out = append(out, llm.Message{Role: llm.RoleUser, Content: "【早前对话摘要,据此延续】\n" + summary})
out = append(out, recent...)
return out, nil
}实现时要注意三点:
- 保留 system,避免丢失角色与规则;
- 保留最近几轮原文,维持近期细节;
- 把较早历史蒸馏为摘要。摘要应保留后续可能使用的主体、标识、决策、约束和待办,压缩的主要对象是重复表达与过程性噪声。
9.4 工具结果压缩与文件外置
第二类膨胀源是工具结果与检索片段。工具读取长文档或查询返回大量记录时,若把结果原样写入历史,会迅速占用预算;其中不少内容只在当前步骤使用一次,没有必要长期常驻。
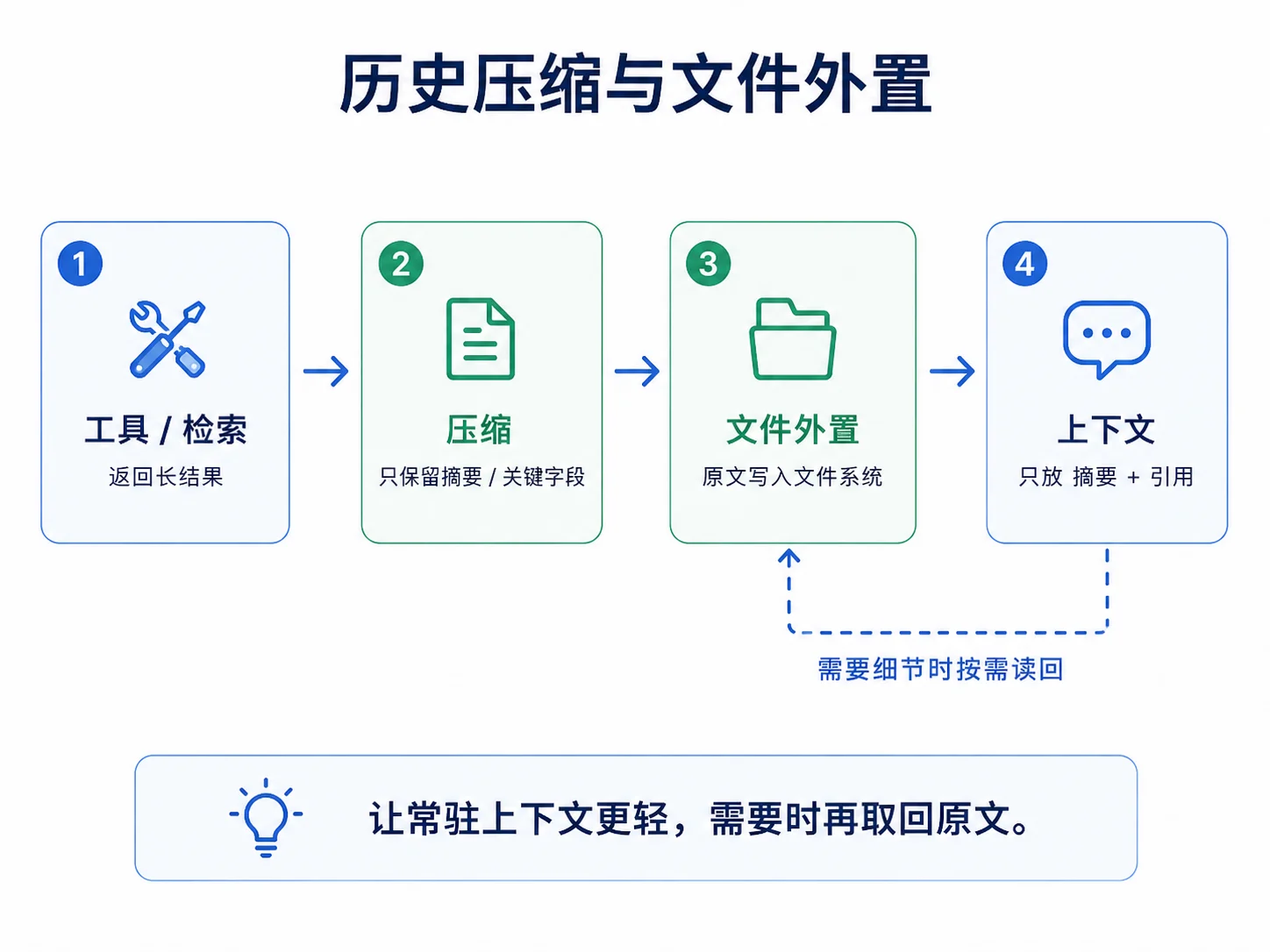
可以采用两个递进手段:
压缩:长结果不一定全文进入上下文,可以先摘要,或者只保留当前步骤需要的字段。
外置(文件系统作为外部记忆):把大块内容写入文件,上下文只保留“引用 + 摘要”;模型需要细节时,再通过工具按需读回。这样可以缩短常驻上下文,同时保留原始内容的可追溯性。
package ctxeng
import (
"fmt"
"os"
"path/filepath"
"time"
)
// FileMemory 把大块内容外置到磁盘,上下文里只留引用。
type FileMemory struct{ Dir string }
// Offload:内容超过阈值则写盘、返回"引用+摘要"占位;否则原样返回。
func (m *FileMemory) Offload(content string, threshold int) (string, error) {
if EstimateTokens(content) <= threshold {
return content, nil // 不大,直接进上下文
}
id := fmt.Sprintf("mem-%d", time.Now().UnixNano())
if err := os.WriteFile(filepath.Join(m.Dir, id+".txt"), []byte(content), 0o600); err != nil {
return "", err
}
head := []rune(content)
if len(head) > 200 {
head = head[:200]
}
// 上下文里只留:引用 + 摘要。模型要全文时调 read_memory 按 id 读回。
return fmt.Sprintf("[内容已外置 id=%s,摘要:%s…(需全文用 read_memory 读取)]", id, string(head)), nil
}
func (m *FileMemory) Read(id string) (string, error) {
data, err := os.ReadFile(filepath.Join(m.Dir, filepath.Base(id)+".txt"))
return string(data), err
}再给模型配置一个 read_memory 工具(用 M06 6.2的 TypedTool 包装 FileMemory.Read),模型就能按需读取外置内容。这与操作系统用磁盘扩展内存同理:上下文空间有限且成本较高,文件存储更适合保存低频大对象。
FileMemory.Dir。生产实现应在写入前创建并校验目录,同时考虑容量上限、生命周期、并发、加密、访问控制和清理策略。Compaction 处理历史,外置处理单条大结果,两者解决的问题不同。9.5 动态工具暴露
第三类膨胀源容易被忽略,那就是工具定义本身。每个工具的名称、描述和参数 Schema 都会占用上下文。一个大型 MCP Server(如 GitHub)的全部工具定义可达上万 token。接入三到五个同量级 Server 后,模型还没看到用户问题,光工具定义可能就已经"超载"了;工具越多,选择错误和参数混淆的风险也可能上升。M05 5.10 模式选型已经说明:当人都说不清楚该用哪个工具时,大模型就更不行了。所以治理工具定义,既省 token 又提准确率。
可以采用两个手段来优化:
- 精选,即设计期只保留满足需求的最小工具集;
- 动态暴露,即运行期只把与当前问题相关的工具提供给模型。
package ctxeng
import (
"sort"
"strings"
"github.com/yourname/llmagent/internal/tool"
)
// SelectTools 按与 query 的相关度,从全部工具里筛出最相关的 maxN 个,避免一次性全塞给模型。
// 这里用最朴素的描述词匹配示意;生产建议用工具描述的 embedding 做语义筛选。
func SelectTools(query string, all []tool.Tool, maxN int) []tool.Tool {
q := strings.ToLower(query)
type scored struct {
t tool.Tool
s int
}
ranked := make([]scored, 0, len(all))
for _, t := range all {
s := 0
for _, w := range strings.Fields(strings.ToLower(t.Description())) {
if w != "" && strings.Contains(q, w) {
s++
}
}
ranked = append(ranked, scored{t, s})
}
sort.SliceStable(ranked, func(i, j int) bool { return ranked[i].s > ranked[j].s })
out := make([]tool.Tool, 0, maxN)
for i := 0; i < len(ranked) && i < maxN; i++ {
out = append(out, ranked[i].t)
}
return out
}简单的关键词匹配只用于说明接口。生产环境可以为工具描述建立 embedding,并用用户问题检索最相关的 k 个工具。此时,“工具太多”和“知识太多”都可以转化为 M07 7.6 混合检索与 rerank问题。还要为路由召回率建立评估,避免必要工具被筛掉。
9.6 结构化笔记与子 Agent 隔离
前两类手段把内容移出常驻上下文,本节进一步让常驻内容更精炼。
结构化笔记(structured note-taking)不要求把所有状态都保留在对话历史中。Agent 可以把当前目标、已确认事实和待办事项写入外部结构化记录。新一轮对话或 Compaction 完成后,通过读取笔记恢复工作状态,通常比重新分析完整历史更短、更稳定:
package ctxeng
// Note 是 Agent 的外部"工作笔记":把关键状态结构化记下,
// 新轮次/压缩后据它快速恢复,而不必从长篇历史里重新理解。
type Note struct {
Goal string `json:"goal"` // 当前目标
Facts map[string]string `json:"facts"` // 已确认的关键事实
Todo []string `json:"todo"` // 待办
Updated string `json:"updated"` // 最近更新时间
}对于长时运行的 Agent,结构化笔记、文件状态和 Git 历史都是从精简上下文恢复工作的依据。这是 M04 4.10 状态持久化思想的延伸:需要保存的不只是消息,还包括经过提炼的工作状态。
子 Agent 上下文隔离是 M08 8.5 隔离式 Orchestrator的另一种解释。把复杂子任务交给隔离的子 Agent,本质上也是上下文管理:每个子 Agent 在独立上下文中处理一项任务,内部过程不进入主 Agent,只把浓缩结论返回。主 Agent 因此主要承载结论级信息,而不是所有过程记录。
把这些手段串起来看:Compaction 压缩历史,文件外置处理大结果,动态暴露治理工具定义,笔记与隔离精炼常驻信息。它们都是本章治理原则的不同实现。
9.7 Prompt Caching 与 Citations
前面的手段主要提高信息密度。本节讨论两个与成本、延迟和可追溯性有关的供应商能力。
Prompt Caching
M03 3.5 Prompt Caching已经介绍过缓存思路,这里关注工程落地时的请求结构。不同供应商的缓存读写价格并不相同;例如 Anthropic 当前的缓存读取价格是基础输入价格的 0.1 倍,而 OpenAI 和 Google 采用各自的计价与控制方式,因此不能把“约 1/10”推广为统一规则。
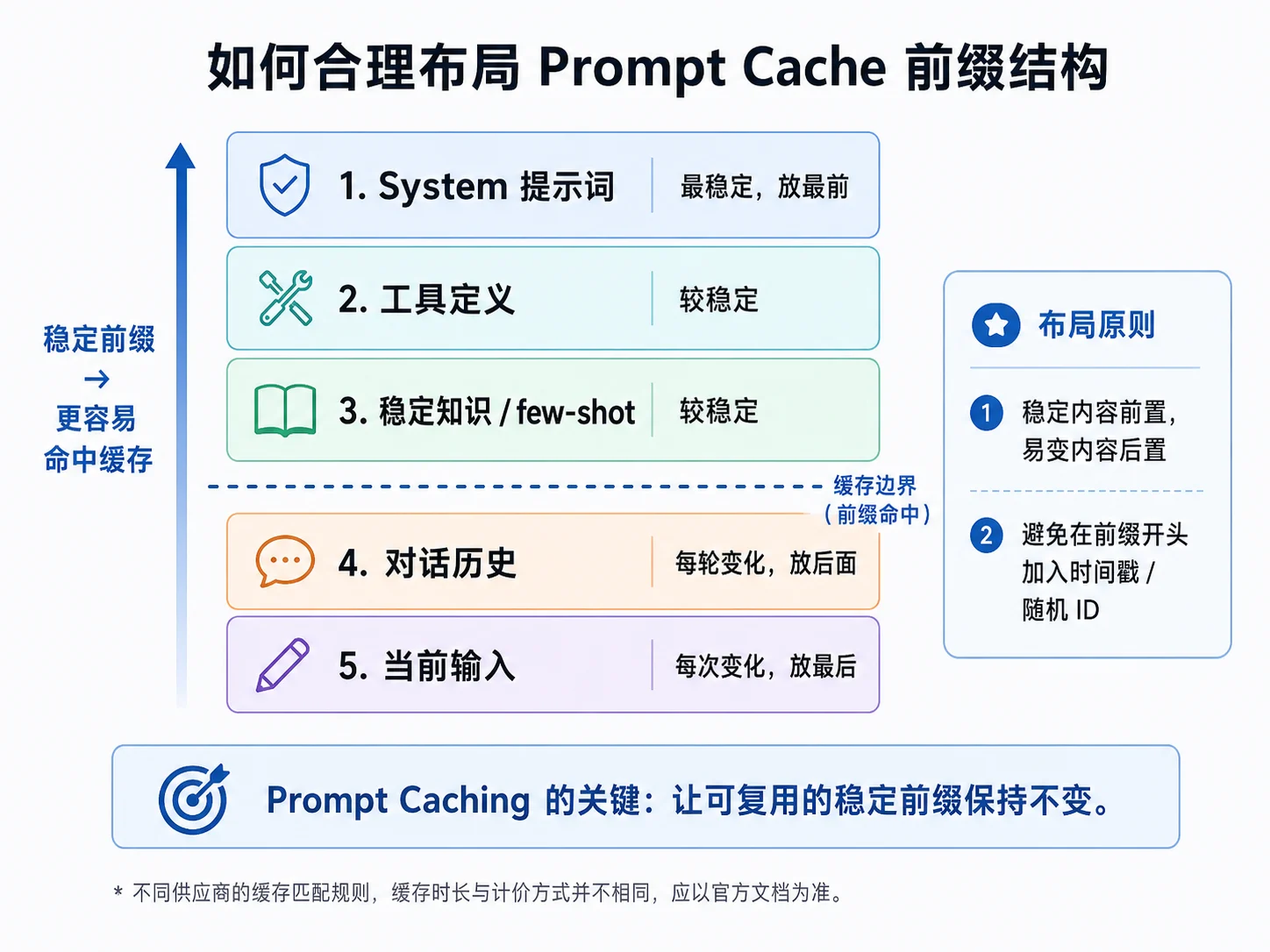
Prompt Caching 依赖稳定前缀或显式缓存内容。一般应把稳定内容放在前面,把频繁变化的历史和当前输入放在后面。若在前缀开头加入时间戳或随机 ID,后续内容即使不变,也可能无法形成有效命中。具体匹配规则、断点数量和缓存时长要以供应商文档为准。
Citations(引用)
很多回答需要说明结论来自哪一段检索材料。若要求模型在正文中完整重写原文,会增加输出 token,也可能引入改写误差。供应商的 Citations 能力可以返回结构化来源标注,帮助应用把回答与源文档对应起来。若产品设计允许用短引文和定位信息代替大段复述,它也可能减少输出 token;实际节省量取决于回答格式,不能只靠启用 Citations 自动获得。
上下文工程不只关乎质量也直接关乎成本与延迟。大流量下能用好缓存和引用的系统可能比不用的系统成本低数倍。
9.8 上下文治理流程
掌握单个手段后,还要把它们组织成组装流程:每次调用模型之前先估算并通过预算控制器,哪一部分超标,就触发对应治理。下面是一个聚焦历史压缩的示意性组装器:
package ctxeng
import (
"context"
"github.com/yourname/llmagent/internal/llm"
)
// AssembleConfig 注入各治理手段所需的依赖。
type AssembleConfig struct {
Budget Budget
KeepRecent int
Summarize func(ctx context.Context, older []llm.Message) (string, error) // 给 Compact 用
}
// Assemble 组装一次调用的消息:超预算就压缩历史,直到落进预算或压无可压。
// (检索片段、工具定义的治理同理:超标就少取 / 动态暴露,这里聚焦历史。)
func Assemble(ctx context.Context, messages []llm.Message, cfg AssembleConfig) ([]llm.Message, error) {
history := joinContent(messages)
for cfg.Budget.History > 0 && EstimateTokens(history) > cfg.Budget.History {
compacted, err := Compact(ctx, messages, cfg.KeepRecent, cfg.Summarize)
if err != nil {
return nil, err
}
if len(compacted) >= len(messages) {
break // 压不动了(已到 system + 最近 keepRecent),避免死循环
}
messages = compacted
history = joinContent(messages)
}
return messages, nil
}
func joinContent(msgs []llm.Message) string {
var b []byte
for _, m := range msgs {
b = append(b, m.Content...)
b = append(b, '\n')
}
return string(b)
}这可以算是长时间运行 Agent harness 的上下文治理雏形:预算控制、自动压缩、工具结果外置、动态工具暴露和笔记恢复共同组成治理链路,使 Agent 能够在长会话和长任务中控制质量、延迟与成本。
从全局来看上下文是有限的注意力预算。当 Agent 的上下文开始膨胀时,应让常驻上下文只保留当前必需的结论性信息,其余内容经过压缩、外置,并在需要时取回。
M04 4.1将 harness 定义为包裹模型并驱动其运行的运行时。本章补充了其中影响长期稳定性的关键环节:上下文治理。一个完整的 harness 至少包括驱动循环、工具调度、停止与预算门控、上下文治理(本章),以及可观测与评估。故障不一定来自模型,也可能来自上下文漂移、Schema 错位和状态退化。
配套练习:给 Agent 加上下文治理
需求:编写一个会累积历史、且带有“返回大段文本”工具的简易 Agent。例如,read_doc 返回一篇长文;运行一段多轮对话,对比治理前后的 token 占用。
验收点(覆盖本章):
- 用
ctxeng.Budget+EstimateTokens做预算门控,打印每轮上下文的估算 token; - 历史超预算时用
ctxeng.Compact压缩,summarize可以调用真实模型,也可以在测试中注入“取前 N 字”的假实现; -
read_doc的大段返回通过ctxeng.FileMemory.Offload外置,并提供read_memory工具按需读回; - 绘制“轮次—token”曲线,观察治理前后增长趋势;
- 为
EstimateTokens、Compact(注入假 summarize)和SelectTools编写表驱动测试。
这个练习完全自包含,不依赖其他项目。未经治理的单次输入会随历史持续增长;经过治理后,输入 token 曲线应趋于有界或明显放缓。需要同时比较任务质量,避免以事实丢失换取较低 token。
本章小结
| 手段 | 治的膨胀源 | 沉淀 |
|---|---|---|
| Token 预算门控 | 全部(总闸) | ctxeng.Budget / EstimateTokens |
| Compaction | 对话历史 | ctxeng.Compact |
| 压缩 + 文件外置 | 工具结果/检索片段 | ctxeng.FileMemory |
| 动态工具暴露 | 工具定义 | ctxeng.SelectTools |
| 结构化笔记 + 子 Agent 隔离 | 常驻信息精炼 | ctxeng.Note / 呼应 M08 8.5 |
| Prompt Caching + Citations | 成本与延迟 | 策略 + Provider 能力 |
一条总纲统领全章:让常驻上下文只保留此刻必需的、结论性的信息,其余内容放到上下文之外并按需取回。
思考题
- 如何证明上下文治理确实有效?例如,Compaction 之后的回答质量是否下降,动态工具暴露是否遗漏了必要工具?这些问题需要通过 M10 10.4 Agent 评估方法回答。
Assemble依赖EstimateTokens的估算结果决定是否压缩。估算值与真实 token 数存在偏差时,应如何校准估算方法,或者在关键路径中引入精确计数?- Compaction 摘要由模型生成。如果压缩过程遗漏关键事实,例如关键标识,应如何降低风险?可以考虑结构化保留关键字段、增加校验,必要时不压缩。