M08 多智能体系统
M05 5.7已经介绍过 Orchestrator-Workers,但那仍然属于单进程内的函数编排:编排者生成子任务,再调用一批 worker 执行。本章继续向前一步,讨论完整的多智能体系统(Multi-Agent System):多个 Agent 作为独立参与者并发运行,并通过消息协作。
Go 很适合实现这类系统。goroutine、channel 和 context 分别承担并发执行、消息传递和生命周期管理,正好对应多 Agent 系统的三项工程基础。本章会先用 channel 实现 MessageBus,再展开 Supervisor、Orchestrator + 隔离 Subagent、Channel Pipeline、Multi-Agent Debate 和 Swarm 五种拓扑。
学习目标
学完本章,你应该能够:
- 区分 M05 的单进程编排与本章的多智能体系统,判断何时才有必要引入多个 Agent;
- 用 channel 实现一个
MessageBus,作为 Agent 间通信的基础设施; - 理解并实现 Supervisor、Orchestrator + 隔离 Subagent、Channel Pipeline、Multi-Agent Debate 和 Swarm;
- 说明上下文隔离与结果浓缩为什么是隔离 Subagent 模式的核心价值;
- 根据任务结构选择协作拓扑,并识别多 Agent 的 token 成本、延迟和特有失败模式;
- 完成
debate多智能体辩论 demo,并比较质量收益与资源成本。
本章依赖 M04 的 agent 包、M05 的设计模式,以及 M01 1.2中的 goroutine、channel、context 和 sync。配套练习是 debate:多个持不同立场的 Agent 围绕同一问题辩论数轮,再由评审综合出最终答案。
8.1 从模式到系统
首先要厘清边界,否则很容易把 M05 的 Orchestrator-Workers和本章的多智能体系统混为一谈。
M05 的模式,本质上是在一个进程内按照既定代码流程组织多次 LLM 调用。编排者向 worker 分配任务,实际仍是主流程调用函数;worker 之间通常不直接通信,也没有各自独立的决策循环。
多智能体系统增加了三个特征:
- 独立性:每个 Agent 都是自主参与者,拥有自己的角色、上下文和决策循环;
- 并发性:多个 Agent 可以通过 goroutine 同时运行,而不是只能由主流程串行调用;
- 通信:Agent 之间通过 channel 传递消息,而不是彼此直接调用函数。
M05 单进程编排: M08 多智能体系统:
[主流程] [Agent A] ⇄ [MessageBus] ⇄ [Agent B]
│ 调用 │ ↕ │
├─► worker1() (函数) └────► [Agent C] ◄───────┘
└─► worker2() (函数) (各自独立、并发运行、消息通信)
控制流在你手里 控制流分散在 Agent 与拓扑里多智能体系统需要并发执行体、消息通道以及超时和取消机制,正好对应 goroutine、channel 和 context。这些都是 Go 语言及标准库的原生能力,因此很适合用来表达本章的几类拓扑。
8.2 通信基石 MessageBus
多个 Agent 要协作,首先需要解决通信问题。最直接的做法是让 Agent A 持有 Agent B 的引用并直接调用,但这会让成员之间产生强耦合:A 必须知道 B 的接口和生命周期。
更通用的做法是引入消息总线(MessageBus)。每个 Agent 只负责发布消息并从自己的收件箱读取消息,路由由总线统一处理。
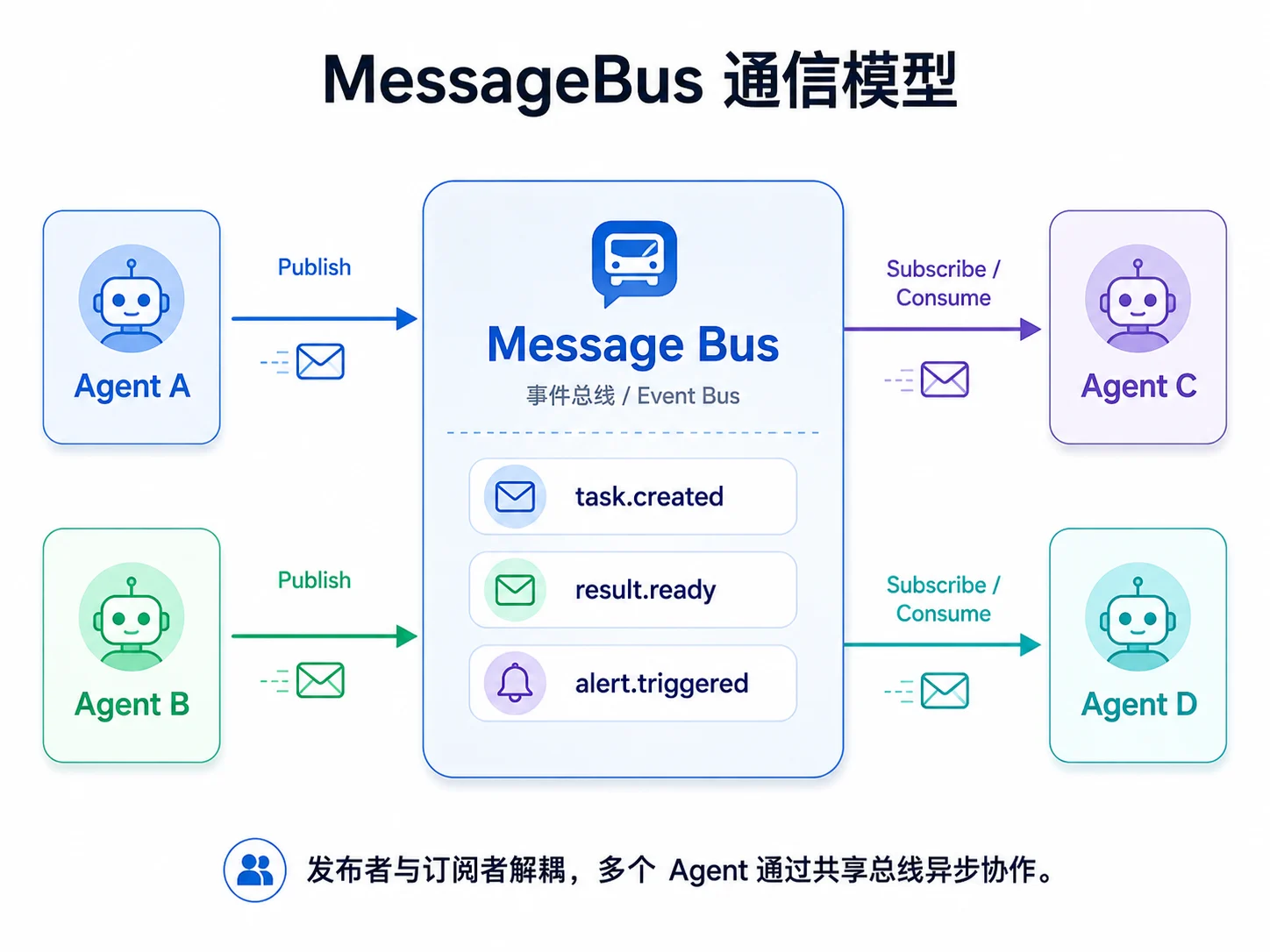
在 Go 中,可以为每个 Agent 分配一个收件箱 channel,再由总线维护 Agent 名称到收件箱的映射。先定义消息结构:
package mas // multi-agent system
type Message struct {
From string // 发送者 Agent 名
To string // 收件人;空或 "*" 表示广播
Content string // 文本内容
Meta map[string]any // 可选的结构化负载
}MessageBus 提供两个核心能力:Subscribe 为 Agent 注册收件箱,Publish 将消息发送给指定成员或广播给其他成员。内部 map 可能被多个 goroutine 并发访问,因此必须加锁;channel 发送可能阻塞,因此还要支持 context 取消。
package mas
import (
"context"
"fmt"
"sync"
)
type MessageBus struct {
mu sync.RWMutex
inboxes map[string]chan Message
buffer int
}
func NewMessageBus(buffer int) *MessageBus {
return &MessageBus{inboxes: make(map[string]chan Message), buffer: buffer}
}
// Subscribe 为某个 Agent 注册收件箱,返回只读 channel。
func (b *MessageBus) Subscribe(name string) <-chan Message {
b.mu.Lock()
defer b.mu.Unlock()
ch := make(chan Message, b.buffer)
b.inboxes[name] = ch
return ch
}
// Publish 把消息路由给收件人;广播则发给除自己外的所有人。
func (b *MessageBus) Publish(ctx context.Context, msg Message) error {
b.mu.RLock()
defer b.mu.RUnlock()
send := func(ch chan Message) error {
select {
case ch <- msg:
return nil
case <-ctx.Done():
return ctx.Err()
}
}
if msg.To != "" && msg.To != "*" {
ch, ok := b.inboxes[msg.To]
if !ok {
return fmt.Errorf("收件人不存在: %s", msg.To)
}
return send(ch)
}
for name, ch := range b.inboxes { // 广播
if name == msg.From {
continue
}
if err := send(ch); err != nil {
return err
}
}
return nil
}
func (b *MessageBus) Close() {
b.mu.Lock()
defer b.mu.Unlock()
for _, ch := range b.inboxes {
close(ch)
}
b.inboxes = make(map[string]chan Message)
}Agent 接入总线后,可以启动一个 goroutine 持续读取收件箱。每次收到消息后执行处理函数,并按需把回复重新发布到总线。
func RunBusAgent(ctx context.Context, bus *MessageBus, name string, handle func(context.Context, Message) (*Message, error)) {
inbox := bus.Subscribe(name)
go func() {
for {
select {
case <-ctx.Done():
return
case msg, ok := <-inbox:
if !ok {
return // 总线关闭
}
reply, err := handle(ctx, msg)
if err != nil || reply == nil {
continue
}
_ = bus.Publish(ctx, *reply)
}
}
}()
}Publish 为了突出主线,在持有 RLock 时执行 channel 发送。若某个收件箱已满,发送会阻塞,并影响 Subscribe 和 Close。生产实现通常会先复制目标 channel 列表,释放锁后再发送,同时为慢消费者设置超时、丢弃或隔离策略。这类问题属于消息背压(backpressure),是多智能体系统必须处理的工程约束。
8.3 多 Agent 协作方法
通信只是基础。把多个 Agent 组织成系统,还要决定状态如何共享、控制权由谁掌握、失败后如何恢复。本节先建立协作方法,再进入五种拓扑的具体实现。
为什么需要多 Agent
单 Agent 配合工具已经能处理大量任务。只有当以下限制开始影响效果时,拆分为多个 Agent 才可能带来收益。
- 上下文容量有限
单 Agent 的决策、工具结果和中间记录都进入同一个上下文窗口。任务步骤较多时,早期信息容易被后续内容稀释,并可能出现 Lost in the Middle 等长上下文问题。
- 工具集相互干扰
当一个 Agent 同时暴露大量工具时,工具描述和参数 schema 会增加选择难度。M09 9.5 动态工具暴露可以减少当前可见工具,但将工具按职责拆给不同 Agent,能够进一步缩小决策范围。
- 角色要求发生冲突
如果同一个 Agent 既要遵循严谨的法律审查标准,又要进行开放式创意写作,system prompt 中的目标可能相互冲突。拆分角色可以让每个 Agent 使用更明确的提示词和评价标准。
- 缺少外部复核
单 Agent 可以根据工具错误自行重试,但不一定能发现整体方向已经偏离。中心监督或多方互评可以增加外部检查环节。
- 无法充分并行
单 Agent 的 Think → Act → Observe 循环通常按步骤推进。若任务中存在多个彼此独立的研究方向或数据源,拆成多个 Agent 可以并行执行。
这些限制与多 Agent 的对应关系如下:
- 上下文有限 → 隔离不同 Agent 的上下文;
- 工具集冲突 → 为不同 Agent 配置不同工具集;
- 角色冲突 → 让每个 Agent 承担单一职责;
- 缺少复核 → 引入主管或多方互评;
- 无法并行 → 让多个 Agent 同时执行独立任务。
这些收益并不意味着复杂任务都应该使用多 Agent。应先确认“单 Agent + 工具 + 上下文工程”确实无法满足要求,再引入额外的通信、调度和观测成本。
多 Agent 协作的核心问题
设计多 Agent 系统时,有四个问题必须明确。
- 通信(Communication)
系统可能需要异步消息、一对多广播和中间路由。前面实现的 channel + MessageBus 为这些通信方式提供了基础。
- 状态(State)
每个 Agent 都有自己的上下文、消息历史和工具结果。状态共享策略会直接影响信息完整性、上下文长度与并发能力:
- 全共享:每个 Agent 都能看到完整历史,信息最充分,但上下文增长最快;
- 完全隔离:每个 Agent 只看到自己的输入输出,便于并行,但信息无法自然流通;
- 浓缩汇总:子 Agent 独立工作,只把结论交给上层,在信息共享与上下文控制之间取得平衡。
浓缩汇总也是 M09 9.6 结构化笔记与子 Agent 隔离的重要思路。
- 协调(Coordination)
| 协调形态 | 谁拿主动权 | 例子 |
|---|---|---|
| 中心化 | 固定主管决定下一步 | Supervisor |
| 分布式 | 每个 Agent 各自决定 | Debate / Swarm |
| 静态 | 流程由代码预先确定 | Pipeline |
- 容错(Fault Tolerance)
Agent 数量增加后,失败点也会增加。常见策略包括:
- 超时重试:子 Agent 未按时返回时重新执行或更换执行者;
- 降级:某个 Agent 失败后回退到单 Agent 或简化流程;
- 冗余:把同一任务交给多个 Agent,通过投票或评审收敛;
- 隔离:限制故障 Agent 对主流程和其他成员的影响。
分析任何多 Agent 系统时,都可以依次检查通信、状态、协调和容错。下面五种拓扑正是这四个方面的不同组合。
协作模式的多维分类
可以从控制流、状态共享、决策时机和消息形态四个维度理解协作拓扑。
控制流方向
中心化 混合 去中心化
[主管] [编排者] [A]⇄[B]
/ | \ [子 A][子 B] | |
[A][B][C] [C]⇄[D]
Supervisor Orchestrator Debate/Swarm状态共享策略
| 策略 | 例子 | 上下文压力 |
|---|---|---|
| 全共享 | Debate(每个 Agent 看全部历史) | 高 |
| 浓缩汇总 | Orchestrator(子 Agent 只返回结论) | 低 |
| 数据流 | Pipeline(只见上一阶段输出) | 中 |
| 点对点转交 | Swarm(handoff 时打包必要状态) | 中 |
决策时机
| 时机 | 含义 | 例子 |
|---|---|---|
| 静态 | 拓扑结构在代码里写死 | Pipeline |
| 动态 | 运行时由 LLM 决定下一步给谁 | Supervisor / Swarm |
| 混合 | 大框架静态,内部动态 | Orchestrator |
消息形态
| 形态 | 例子 |
|---|---|
| 任务分发(主管 → worker) | Supervisor |
| 数据流(上一阶段 → 下一阶段) | Pipeline |
| 辩论(每个 Agent 读取其他成员的结果) | Debate |
| 控制权转交(handoff) | Swarm |
| 子任务分解与收集 | Orchestrator |
每种拓扑都是这四个维度上不同选择的组合。
五种主流拓扑总览
本章讨论五种常见拓扑:
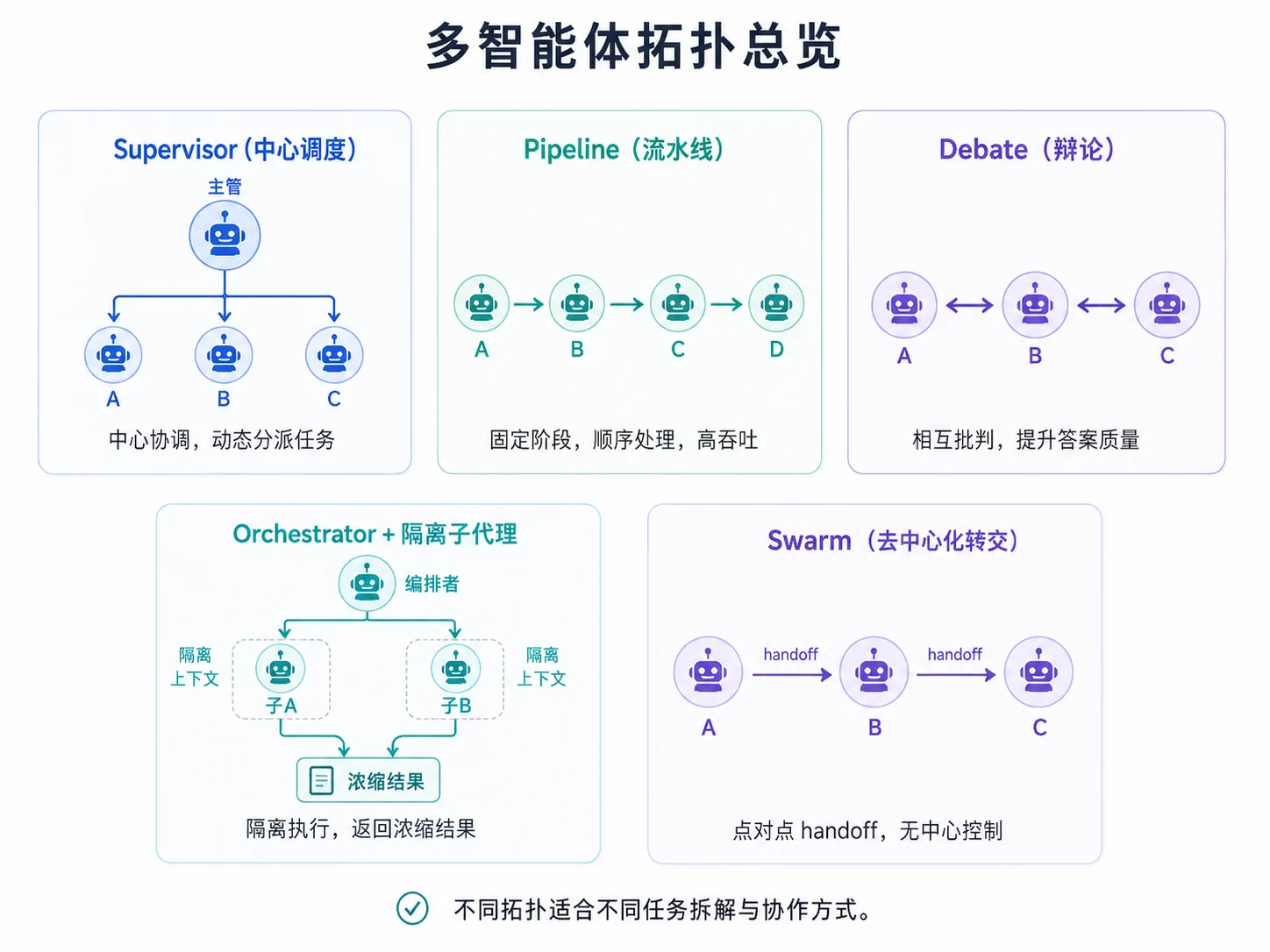
可以先用一句话概括每种拓扑。
| 拓扑 | 一句话 | 类比 |
|---|---|---|
| Supervisor | 一个主管动态决定下一步谁干 | 项目经理 + 工程师团队 |
| Orchestrator + 子代理 | 大任务分解 → 子任务隔离并行 → 浓缩汇总 | 总编辑 + 多个记者分头跑 |
| Pipeline | 固定阶段的流水线,每个 Agent 是一道工序 | 工厂装配线 |
| Multi-Agent Debate | 多方各自给方案,互相批判后收敛 | 评审委员会 |
| Swarm | 点对点转交控制权,职责清晰的接力 | 接力赛 |
下面将会逐个展开实现。
五种拓扑的详细对比与选型
下面的对比表汇总了五种拓扑的主要工程特征。
| 维度 | Supervisor | Orchestrator | Pipeline | Debate | Swarm |
|---|---|---|---|---|---|
| 控制流 | 中心化 | 混合 | 静态线性 | 去中心化 | 去中心化 |
| 状态共享 | 主管见全局 | 子 Agent 隔离 | 数据流 | 全共享 | 转交时打包 |
| 决策时机 | 每步动态 | 顶层动态 + 子任务静态 | 完全静态 | 多轮动态 | 每步动态 |
| 通信开销 | 中(每步经过主管) | 低(可并行) | 低(线性) | 高(上下文互相引用) | 中 |
| Token 成本 | 中(包含主管调用) | 取决于子任务数量 | 低 | 高(多轮重复调用) | 中 |
| 延迟 | 串行 + 主管开销 | 可并行,最快 | 串行 | 多轮辩论,慢 | 串行接力 |
| 收敛性 | 主管决定何时停 | 编排者明确 | 流水线尽头 | 投票或共识 | 终止状态 |
| 容错 | 主管是单点 | 子 Agent 可独立处理故障 | 任一阶段失败会影响全链路 | 可通过多数意见降低单点偏差 | 任一节点失败可能中断 |
| 可扩展 | worker 易加,主管难扩 | 子 Agent 易加 | 加阶段需重设计 | 加 Agent 通信压力翻倍 | 易加但路由难 |
| 复杂度 | 中 | 高 | 低 | 高 | 高 |
| 适合场景 | 灵活调度复杂任务 | 可并行的研究 / 工单 | 高吞吐批处理 | 高风险决策、质量优先 | 角色清晰的接力 |
| 典型例子 | 客户经理调度专家 | Deep Research 类应用 | 内容审核流水线 | 法律 / 合规评审 | 客户服务多角色转接 |
可以按下面的顺序选择拓扑。
有多 Agent 协作需求
│
├─ 任务结构能画清流程图?
│ │是 → Pipeline(简单、高吞吐)
│
├─ 大任务可分解为多个独立子任务并行?
│ │是 → Orchestrator + 隔离子代理(并行最快)
│
├─ 路径动态、需要灵活调度?
│ │是 → Supervisor(适合大多数复杂任务)
│
├─ 高风险决策、要多方论证?
│ │是 → Debate(成本高,适合多方复核)
│
└─ 多个清晰角色接力转交?
│是 → Swarm(职责边界清的接力场景)工程实践中可以遵循以下原则:
- 流程固定时优先 Pipeline,因为它最简单、最便宜,也最容易控制;
- 大任务能够拆成独立子任务时,优先考虑 Orchestrator,以利用并行能力;
- 执行路径需要根据中间结果动态调整时,使用 Supervisor;
- 决策错误代价较高且确实需要多方论证时,再使用 Debate;
- 只有角色边界和转交条件都足够清楚时,才使用 Swarm。
多 Agent 的工程代价
拓扑选择不能只比较能力,还要评估以下工程代价。
- Token 成本增加
每个 Agent 都有自己的 system prompt、上下文和 LLM 调用。Debate 的调用次数至少与“辩手数 × 轮数”成正比;如果每个辩手都读取其他成员的完整回答,上下文总量还会随参与者数量进一步增长。
- 延迟增加
Supervisor、Pipeline 和 Swarm 包含串行路径,总延迟会累积每一步调用时间。Orchestrator 可以并行执行子任务,但分解和汇总仍然位于关键路径上。
- 调试难度增加
多 Agent 系统需要同时观察多条执行轨迹和消息链路:
- 每个 Agent 都有独立轨迹,合并后形成更大的执行树;
- 消息传递成为新的失败面;
- 一个 Agent 的错误输出可能污染所有下游成员;
- 定位问题时往往需要同时检查多条轨迹。
- 状态一致性问题
多个 Agent 共享短期进度或长期记忆时,需要处理:
- 写冲突:两个 Agent 同时修改同一状态;
- 版本滞后:一个 Agent 读取到其他成员更新前的旧状态;
- 状态泄露:Agent 获得了超出自身职责范围的信息。
- 设计复杂度增加
每增加一个 Agent,都要设计 system prompt、工具集、通信接口和失败处理。成员之间的潜在交互关系随数量增加,因此设计成本通常不是简单的线性增长。
选型判据
在选择具体拓扑之前,先判断任务是否需要 Agent。
要解决一个复杂任务
│
├─ 路径完全已知 + 步数 < 5?
│ │是 → 固定工作流
│ 使用普通代码实现
│
├─ 路径不确定 + 单 Agent 能承担?
│ │是 → 单 Agent + 工具(M04)
│ 优先采用的方案
│
├─ 单 Agent 出现前述限制?
│ │是 → 多 Agent
│ 按前面的决策树挑拓扑
│
└─ 评估发现多 Agent 比单 Agent 反而差?
│是 → 退回单 Agent
多 Agent 不是默认更优的方案M05 的模式选型已经覆盖了部分多角色能力。例如,Plan-and-Execute 会在一个进程内分离规划与执行。只有这些模式仍不足以解决上下文隔离、并行探索或角色转交问题时,才需要升级到多智能体系统。
对话调用助手
下面逐个实现五种拓扑。它们都建立在 M04 的 agent.Agent和 M02 的 llm.Provider之上。
为减少重复代码,先在 mas 包中准备一个基础调用助手:
package mas
import (
"context"
"github.com/yourname/llmagent/internal/llm"
)
func chat(ctx context.Context, p llm.Provider, model, system, user string) (string, error) {
resp, err := p.Chat(ctx, llm.ChatRequest{
Model: model,
Messages: []llm.Message{
{Role: llm.RoleSystem, Content: system},
{Role: llm.RoleUser, Content: user},
},
})
if err != nil {
return "", err
}
return resp.Content, nil
}8.4 Supervisor
Supervisor 模式设置一个中心 Agent。主管不直接执行具体任务,而是读取任务目标和当前进展,通过一次 LLM 调用决定下一步由哪个成员执行,或者判断任务已经完成。成员返回结果后,主管继续决策,直到结束。
这种模式的优势是灵活:执行路径由运行时状态决定,而不是像 Pipeline 一样预先固定。代价是每一步都要增加一次主管决策调用,而且主管会成为中心节点。
实现时应让主管返回结构化决策。下面要求模型只输出 JSON,再使用 M02 2.8的 ParseInto 解析下一位执行者。
package mas
import (
"context"
"fmt"
"strings"
"github.com/yourname/llmagent/internal/agent"
"github.com/yourname/llmagent/internal/llm"
)
type SupervisorDecision struct {
Next string `json:"next"` // 下一个成员名;"FINISH" 表示结束
Reason string `json:"reason"`
}
type Supervisor struct {
Provider llm.Provider
Model string
Workers map[string]*agent.Agent // 成员名 -> Agent
MaxTurns int
}
func (s *Supervisor) decide(ctx context.Context, task, progress string) (SupervisorDecision, error) {
names := make([]string, 0, len(s.Workers))
for n := range s.Workers {
names = append(names, n)
}
system := fmt.Sprintf(
"你是团队主管。可调度的成员有:%s。根据任务和当前进展,决定下一步该谁来做;"+
"若任务已完成则输出 FINISH。严格只输出 JSON:{\"next\":\"成员名或FINISH\",\"reason\":\"理由\"}",
strings.Join(names, ", "))
out, err := chat(ctx, s.Provider, s.Model, system, "任务:"+task+"\n\n当前进展:\n"+progress)
if err != nil {
return SupervisorDecision{}, err
}
return llm.ParseInto[SupervisorDecision](out)
}
func (s *Supervisor) Run(ctx context.Context, task string) (string, error) {
var progress strings.Builder
for turn := 0; turn < s.MaxTurns; turn++ {
d, err := s.decide(ctx, task, progress.String())
if err != nil {
return "", err
}
if d.Next == "FINISH" {
return progress.String(), nil
}
w, ok := s.Workers[d.Next]
if !ok {
return "", fmt.Errorf("主管选了不存在的成员: %q", d.Next)
}
result, err := w.Run(ctx, task+"\n\n已有进展:\n"+progress.String())
if err != nil {
return "", err
}
fmt.Fprintf(&progress, "【%s】\n%s\n\n", d.Next, result)
}
return progress.String(), fmt.Errorf("达到最大轮次 %d 仍未 FINISH", s.MaxTurns)
}MaxTurns 是必要的停止条件。如果主管始终不输出 FINISH,系统可能在多个成员之间持续调度并不断消耗 token。所有由模型控制下一步的循环都必须设置硬上限。
8.5 Orchestrator 与隔离 Subagent
截至 2026 年 6 月,Anthropic、OpenAI 和 LangChain 的官方资料都在介绍编排者调用专门子 Agent 的协作方式。它与 M05 5.7 Orchestrator-Workers形式相近,但这里强调两个工程约束:子代理使用隔离的上下文,并且只把与任务相关的结果交回编排者。
M04 4.10已经说明,Agent 的 Messages 会随着工具调用不断增长。如果编排者接收所有子代理的完整消息、工具结果和中间输出,主上下文会迅速膨胀,增加成本并降低有效信息密度。
隔离 Subagent 的做法是让每个子代理在全新的上下文中独立完成子任务。子代理内部可以进行多轮工具调用,但返回给编排者的只是浓缩结论,而不是完整执行记录。这样,编排者主要处理“目标 + 子结论 + 综合”,不会被子代理内部细节占满上下文。
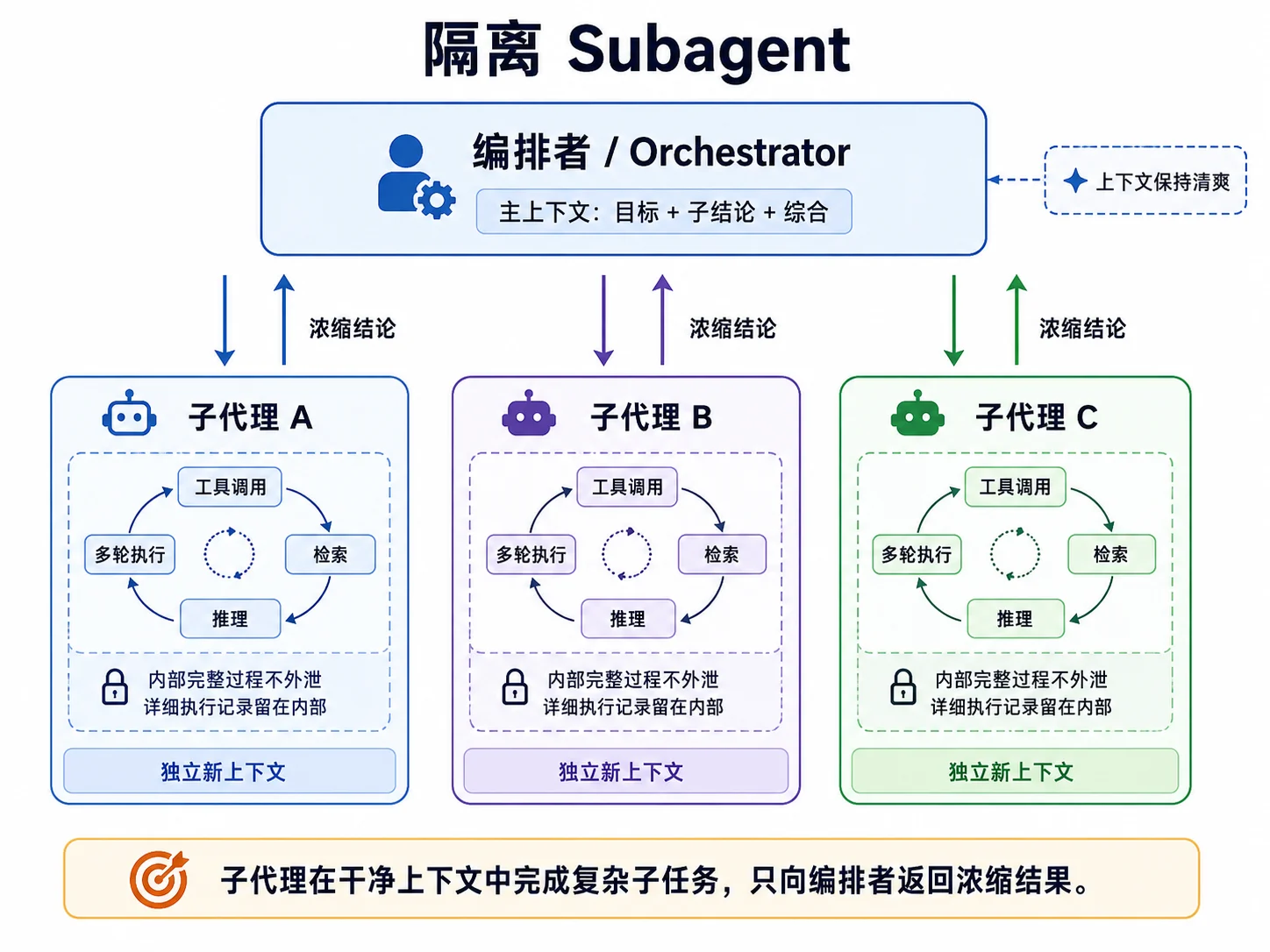
实现上可以复用 M05 5.5 Parallelization的 Sectioning 并行执行任务。关键点是通过工厂函数为每个子任务创建新的 Agent,并且只收集 Run 返回的最终结果,而不是内部 transcript。
package mas
import (
"context"
"fmt"
"strings"
"github.com/yourname/llmagent/internal/agent"
"github.com/yourname/llmagent/internal/llm"
"github.com/yourname/llmagent/internal/patterns" // 复用 M05 的 Sectioning
)
type IsolatedOrchestrator struct {
Provider llm.Provider
Model string
// NewSubagent 为某个角色现造一个全新 Agent —— 每次调用都是干净、隔离的上下文。
NewSubagent func(role string) *agent.Agent
}
type subtask struct {
Role string `json:"role"`
Task string `json:"task"`
}
type plan struct {
Subtasks []subtask `json:"subtasks"`
}
func (o *IsolatedOrchestrator) Run(ctx context.Context, goal string) (string, error) {
// 1) 编排者分解任务(结构化输出)
sys := "你是编排者。把任务拆成可独立完成的子任务,为每个子任务指定一个角色。" +
"严格只输出 JSON:{\"subtasks\":[{\"role\":\"...\",\"task\":\"...\"}]}"
raw, err := chat(ctx, o.Provider, o.Model, sys, goal)
if err != nil {
return "", err
}
p, err := llm.ParseInto[plan](raw)
if err != nil {
return "", fmt.Errorf("分解结果无法解析: %w", err)
}
// 2) 并行跑各子代理。每个子代理上下文隔离,只交回浓缩结论。
jobs := make([]func(context.Context) (string, error), len(p.Subtasks))
for i, st := range p.Subtasks {
st := st
jobs[i] = func(ctx context.Context) (string, error) {
sub := o.NewSubagent(st.Role) // 全新、隔离的上下文
result, err := sub.Run(ctx, st.Task)
if err != nil {
return "", fmt.Errorf("子代理[%s]失败: %w", st.Role, err)
}
return fmt.Sprintf("【%s 的结论】%s", st.Role, result), nil
}
}
results, err := patterns.Sectioning(ctx, jobs)
if err != nil {
return "", err
}
// 3) 编排者只基于“浓缩结论”综合 —— 它的上下文从未被子代理内部细节污染
return chat(ctx, o.Provider, o.Model,
"下面是各子代理的结论,请综合成对原始目标的完整回答。",
"目标:"+goal+"\n\n各子代理结论:\n"+strings.Join(results, "\n\n"))
}8.6 Channel Pipeline
当一批数据需要依次经过固定阶段时,Pipeline 是最直接的拓扑。例如批量处理文档,每条数据都要经过 分类 → 检索资料 → 起草内容 → 质检。每个阶段由一个或一组 Agent 负责,阶段之间通过 channel 串联。
这正是 Go 常见的 pipeline 并发模式。下面用泛型实现一个通用阶段,同时支持 fan-out 和 fan-in:一个阶段启动多个 worker 并行消费输入,再把结果汇入同一个输出 channel。
package mas
import (
"context"
"sync"
)
// Stage 是流水线的一个阶段:从 in 读取,用 workers 个 goroutine 并行处理,结果写入返回的 channel。
func Stage[I, O any](ctx context.Context, in <-chan I, workers int, fn func(context.Context, I) (O, error)) <-chan O {
out := make(chan O)
var wg sync.WaitGroup
for i := 0; i < workers; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for item := range in {
o, err := fn(ctx, item)
if err != nil {
continue // 教学简化:实际应把错误送往专门的错误 channel
}
select {
case out <- o:
case <-ctx.Done():
return
}
}
}()
}
go func() { wg.Wait(); close(out) }() // 所有 worker 退出后关闭输出
return out
}有了 Stage,工单处理流水线只需要把多个阶段依次连接起来。
// 把工单流依次经过:分类 → 检索 → 起草 → 质检
classified := Stage(ctx, tickets, 4, classifyAgent) // 4 个并行做分类
retrieved := Stage(ctx, classified, 2, retrieveAgent)
drafted := Stage(ctx, retrieved, 4, draftAgent)
reviewed := Stage(ctx, drafted, 2, reviewAgent)
for r := range reviewed { // 消费最终结果
save(r)
}每个阶段都可以独立设置并行度。例如分类和起草可以配置更多 worker,受外部知识库限制的检索阶段则降低并发。阶段之间通过 channel 形成数据流和背压,context 取消后整条流水线都能停止。
8.7 Multi-Agent Debate
有些高风险任务需要多视角复核,例如医疗建议初筛、风控判断或重要方案评审。Multi-Agent Debate 让多个 Agent 先独立作答,再读取其他成员的答案、提出批评并修订观点,最后由评审综合定稿。
它与 M05 5.5的 Voting 不同。Voting 中的 Agent 独立作答,最后只做汇总或计票;Debate 中的 Agent 会看到并回应其他观点。额外的修订过程可能发现遗漏,但也会增加调用次数和上下文长度。
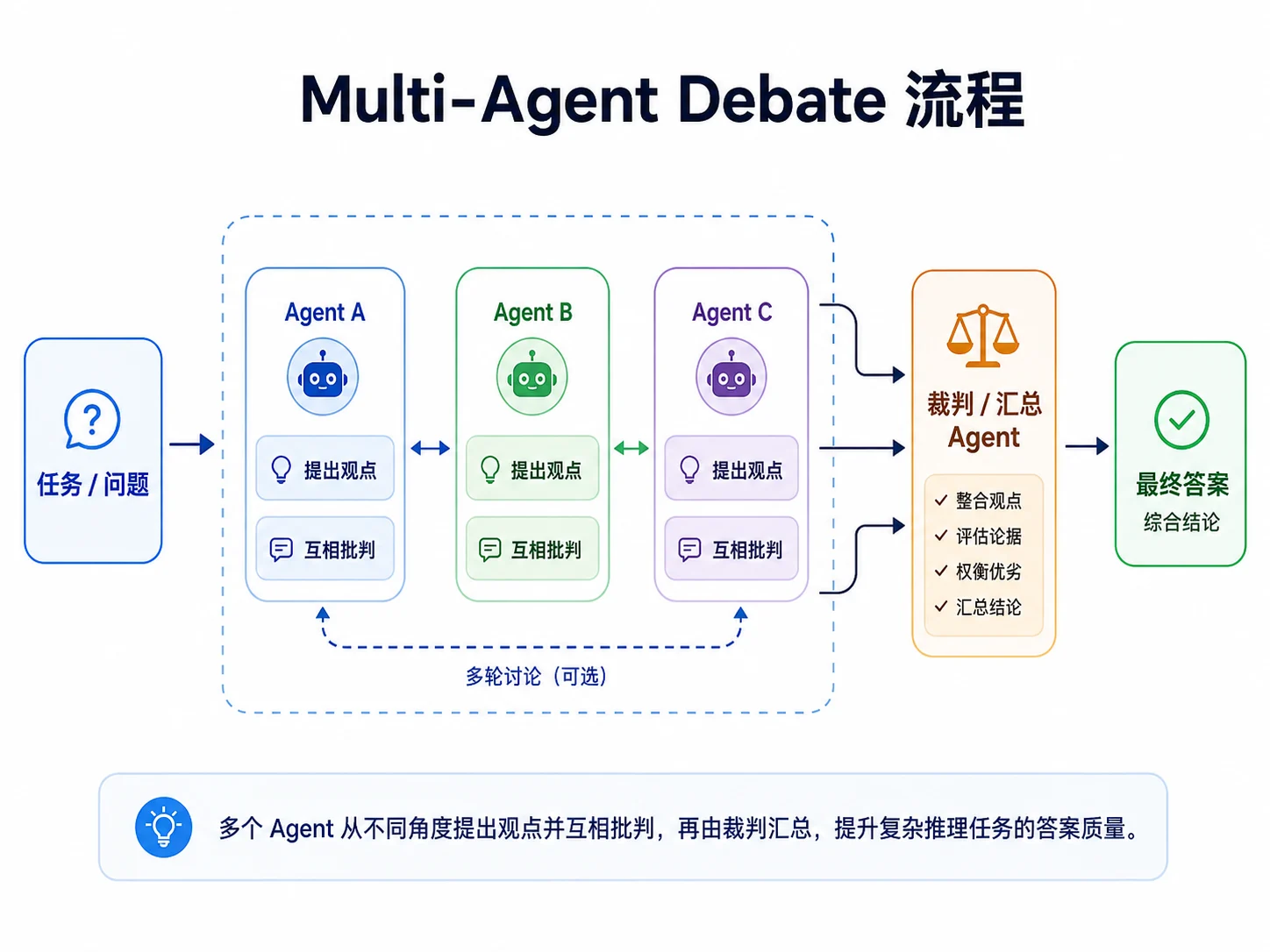
实现的核心是按轮次推进。每轮开始时先复制上一轮答案,所有辩手基于同一份快照并行作答;本轮全部完成后再进入下一轮。
package mas
import (
"context"
"fmt"
"strings"
"sync"
"github.com/yourname/llmagent/internal/llm"
)
type Debater struct {
Name string
Provider llm.Provider
Model string
Persona string // 该辩手的立场/视角,作为 system 提示词
}
// Debate 进行 rounds 轮辩论,返回每位辩手的最终答案。
func Debate(ctx context.Context, debaters []Debater, question string, rounds int) (map[string]string, error) {
answers := make(map[string]string)
var mu sync.Mutex
for round := 0; round < rounds; round++ {
// 快照本轮开始时的答案,供各辩手参考(避免并发读写同一 map)
mu.Lock()
prev := make(map[string]string, len(answers))
for k, v := range answers {
prev[k] = v
}
mu.Unlock()
var wg sync.WaitGroup
errCh := make(chan error, len(debaters))
for _, d := range debaters {
d := d
wg.Add(1)
go func() {
defer wg.Done()
ans, err := chat(ctx, d.Provider, d.Model, d.Persona, debatePrompt(question, d.Name, prev))
if err != nil {
errCh <- err
return
}
mu.Lock()
answers[d.Name] = ans
mu.Unlock()
}()
}
wg.Wait()
close(errCh)
if err := <-errCh; err != nil { // 取第一个错误(channel 空且关闭时返回 nil)
return nil, err
}
}
return answers, nil
}
func debatePrompt(question, self string, prev map[string]string) string {
if len(prev) == 0 {
return "问题:" + question + "\n请给出你的回答和理由。"
}
var sb strings.Builder
sb.WriteString("问题:" + question + "\n\n其他成员上一轮的观点:\n")
for name, ans := range prev {
if name == self {
continue
}
fmt.Fprintf(&sb, "- %s:%s\n", name, ans)
}
sb.WriteString("\n请批判性地参考他们的观点,修订并强化你的回答。")
return sb.String()
}
// Judge 综合各辩手的最终答案,给出定稿。
func Judge(ctx context.Context, p llm.Provider, model, question string, answers map[string]string) (string, error) {
var sb strings.Builder
for name, ans := range answers {
fmt.Fprintf(&sb, "【%s】%s\n\n", name, ans)
}
return chat(ctx, p, model,
"你是评审。综合下面各位专家的最终回答,给出最准确、全面、平衡的定稿。",
"问题:"+question+"\n\n各方回答:\n"+sb.String())
}8.8 Swarm
Swarm 是去中心化的控制权转交模式。系统没有固定主管,每个 Agent 处理当前请求后,自行决定给出最终答案,还是通过 handoff 把请求转交给另一个 Agent。
这种结构适合分诊和接力场景。例如接待 Agent 先识别问题领域,再转交给对应专家;专家若发现问题涉及其他职责,还可以继续转交。每个 Agent 只负责自己的专业范围和可转交对象。
实现时,每个 Agent 的结果要么包含最终答案,要么包含下一个 handoff 目标。Swarm 运行器沿转交链执行,直到得到答案或达到转交上限。
package mas
import (
"context"
"fmt"
)
// SwarmResult:Agent 要么给出答案,要么转交给下一个。
type SwarmResult struct {
Answer string // 非空表示给出最终答案
HandoffTo string // 非空表示转交给该 Agent
}
type SwarmAgent struct {
Name string
Run func(ctx context.Context, input string) (SwarmResult, error)
}
type Swarm struct {
Agents map[string]SwarmAgent
MaxHops int // 最大转交次数,防止无限转交
}
func (s *Swarm) Run(ctx context.Context, start, input string) (string, error) {
cur := start
for hop := 0; hop < s.MaxHops; hop++ {
a, ok := s.Agents[cur]
if !ok {
return "", fmt.Errorf("不存在的 Agent: %q", cur)
}
res, err := a.Run(ctx, input)
if err != nil {
return "", err
}
if res.HandoffTo == "" {
return res.Answer, nil // 有人给出了答案,结束
}
// 转交:把当前的处理结果作为上下文带给下一个 Agent
cur = res.HandoffTo
if res.Answer != "" {
input = input + "\n\n[" + a.Name + " 的处理]:" + res.Answer
}
}
return "", fmt.Errorf("转交超过 %d 次仍无最终答案", s.MaxHops)
}每个 SwarmAgent 内部仍然可以使用 M04 的 Agent,只需增加一个表达转交目标的 handoff 工具。Swarm 容易增加新角色,但也可能形成 A → B → A 的循环,因此 MaxHops 是必要边界。生产系统还应记录已访问节点,以便提前发现循环转交。
8.9 选型与代价
理解五种拓扑后,还要回答两个问题:当前任务是否需要多 Agent,以及需要哪一种拓扑。
先按任务特征选择候选拓扑。
| 任务特征 | 候选拓扑 |
|---|---|
| 阶段固定、批量、追吞吐 | Pipeline |
| 步骤不定、需灵活动态调度 | Supervisor |
| 可并行分解、子任务上下文需隔离 | Orchestrator + 隔离子代理 |
| 高风险决策、值得多方互相批判 | Debate |
| 职责清晰、接力式转交 | Swarm |
在选拓扑之前,应重新确认任务是否真的需要多个 Agent。除额外 token 成本外,多智能体系统还会引入以下特有失败模式:
- 死锁与背压:Agent 互相等待消息,或慢消费者阻塞消息总线;
- 协调风暴:广播式通信使消息数量快速增长;
- 跨 Agent 调试困难:错误轨迹分散在多个并发 Agent 和消息链路中;
- 错误跨体传播:一个 Agent 的错误结论被其他成员继续使用并放大;
- 停止条件缺失:主管、辩论或转交流程没有硬边界,导致成本失控。
配套练习:debate 多智能体辩论 demo
使用本章的 Debate 和 Judge 实现一个多智能体辩论工具,并通过对比实验评估质量收益和 token 成本。
需求如下:
- 给定一个有争议或需要权衡的问题,例如“这段架构方案有什么风险”;
- 创建 3 个持不同视角的辩手,例如务实派、谨慎派和数据派;
- 辩论 2~3 轮,并打印每轮每位辩手的观点变化;
- 由评审综合各方最终观点并生成定稿;
- 统计总 token 消耗;
- 对比单个 Agent 直接回答与“三辩手辩论三轮 + 评审”的质量和成本。
验收点:
- 使用不同
Persona运行多轮Debate,并可选用不同模型或 Provider; - 使用
Judge综合生成定稿; - 打印每一轮观点,观察辩手是否根据其他观点做出有效修订;
- 设置轮数上限并统计总 token 消耗;
- 对同一个问题执行单 Agent 与多 Agent 对比实验。
入口骨架如下:
func main() {
ctx := context.Background()
question := "我们准备用单体架构起步、后期再拆微服务,这个决策有哪些风险?"
debaters := []mas.Debater{
{Name: "务实派", Provider: p, Model: m, Persona: "你务实,关注落地速度与团队现状。"},
{Name: "谨慎派", Provider: p, Model: m, Persona: "你谨慎,关注长期可维护性与技术债。"},
{Name: "数据派", Provider: p, Model: m, Persona: "你重证据,倾向用事实和案例说话。"},
}
answers, err := mas.Debate(ctx, debaters, question, 3)
if err != nil { /* ... */ }
final, err := mas.Judge(ctx, p, m, question, answers)
if err != nil { /* ... */ }
fmt.Println("=== 定稿 ===\n", final)
}本章小结
| 内容 | 在系统中的作用 |
|---|---|
channel 式 MessageBus | Agent 间解耦通信的基础 |
| Supervisor(JSON 决策) | 步骤不固定任务的动态调度 |
| Orchestrator + 隔离子代理 | 复杂任务并行分解、上下文隔离与结果浓缩 |
| Channel Pipeline | 批处理场景的高吞吐流水线 |
| Multi-Agent Debate | 高风险决策的多视角复核 |
| Swarm 转交 | 职责清晰的接力式转接 |
| 选型与失败模式 | 判断是否值得引入多 Agent |
本章从 MessageBus 开始,依次讨论了多 Agent 协作的核心问题、五种拓扑及其 Go 实现,并给出了两层选型方法:先判断是否需要 Agent,再判断是否需要多个 Agent。
下一章进入 M09 上下文工程。多智能体系统运行后,多个 Agent 的消息、工具结果和中间结论会持续进入上下文。如何压缩、隔离和组织这些信息,是系统长期稳定运行的关键。
思考题
- 本章手写了主管循环、流水线串联和辩论轮次。如果使用声明式图结构描述节点连接与数据流,哪些重复代码可以被框架接管?这正是 M11 11.7 Eino Compose要解决的问题。
- 本章的 Agent 通过进程内 channel 通信。如果 Agent 分属不同团队、使用不同语言并部署在不同机器上,应该如何定义通信协议?M12 12.3将进入 A2A 协议。
- 多智能体系统出现问题时,应该记录哪些输入输出、消息流转、token 消耗和耗时信息,才能还原完整执行过程?这会在 M10 10.2 OpenTelemetry 埋点中展开。