M07 记忆系统与 Agentic RAG
到目前为止,我们的 Agent 仍然缺少一个关键能力:它只能依赖模型训练阶段已经包含的知识。你问它"我们公司的某条内部规范是什么",它要么说不知道,要么随便编个没有依据的答案,因为这些私有知识并不在模型参数里。本章要解决的问题就是如何让 Agent 使用它原本不知道的、属于你的私有知识。
让 Agent 使用私有知识是绝大多数企业级 Agent 的基础需求,RAG 是当前最常见的工程方案。我们会先建立"记忆"的整体框架,再逐步提升检索质量,最后把检索包装成一个工具,让 M04 的 Agent自己决定何时检索、检索什么、检索结果是否充分,从基础 RAG 进展到 Agentic RAG。
学习目标与模块定位
学完本模块你将能够:
- 用"四种记忆"的框架理清 Agent 的记忆需求,知道哪种用对话历史、哪种用外部存储;
- 实现 RAG 的完整管线:切分(RecursiveChunker)、向量化(Embedding)、存储检索(pgvector);
- 用混合检索(BM25+向量+RRF)+ rerank 提升检索质量,掌握当前常用的生产基线;
- 理解并实现 Agentic RAG:让 Agent 自主决定检索时机、查询内容与充分性,而不是每轮固定检索一次;
- 判断何时该混用 GraphRAG/LazyGraphRAG 以及长上下文 vs RAG 的经济学决策。
这是 Agent “记忆与知识"维度的核心技能。检索会作为一个工具接入 Agent,并用上 M05 5.6 Evaluator-Optimizer的反思机制判断"检索结果够不够好”。
前置需要完成 M02 的 llm、schema、M04 的 agent、tool和 M06 工具系统。需要一个 Postgres + pgvector(练习用 docker-compose 起)。
配套练习:mini-kb——索引一个文档目录,用混合检索 + rerank 回答问题、给出来源标注,并包装成 Agentic RAG 工具。
7.1 Agent 的记忆系统
讲检索 / RAG 之前,我们先要建立"记忆"这个抽象。Agent 与一次性问答的最根本区别就在于『记忆』——没有记忆 Agent 每次都从零开始,不可能成为"持续协作的助手"。
这一节将系统介绍为什么 Agent 需要记忆、记忆有几种、它们与"上下文"和"知识库"的区别是什么、工程上写什么读什么丢什么。
Agent 为什么需要记忆
LLM 本身完全无状态。每次 API 调用是孤立的,模型不"记得"前一次说过什么。你给它什么 prompt 它就基于这个 prompt 回答,没有"上次"这个概念。
但 Agent 的任务根本上是有状态的:
- 对话有历史:用户上一句说"我是上海的",下一句问"今天天气怎样",Agent 得知道"今天 + 上海"
- 用户有偏好:这个用户用 Python,那个用户用 Go;这个用户希望简短回答,那个用户希望详细
- 过去有交互:上周这个用户问过退货,你们处理过的方案应该能复用
- 业务有知识:你们公司的退货政策、产品手册、API 文档都是 Agent 应该知道的
模型无状态 + 任务有状态 → 必须在外面包一层"记忆"。这层记忆负责:
- 存:把跨调用 / 跨会话需要的信息保留下来
- 取:在每次模型调用前,从记忆里取相关的放进 prompt
- 管:控制总量(不让无限增长)、控制时效(过期清理)、控制隐私(敏感数据剥离)
如果没有记忆 Agent 就只是一个加了工具的问答机器人。有了记忆,Agent 才能成为能够持续协作的助手。M04 4.10已经实现了最简记忆——Messages 列表 + 状态持久化,但那只是其中一种。完整的记忆系统比那更宽泛。
四种记忆类型
“Agent 记忆"不是工程师拍脑袋分出来的——它直接借鉴了认知科学几十年的研究成果。
人类记忆研究的经典脉络是这样的:
- 1968 年 Atkinson 与 Shiffrin 提出三组分(多存储)模型——感觉记忆 → 短期记忆 → 长期记忆;
- 1972 年 Tulving 把长期记忆进一步区分为情节记忆 (episodic) 与语义记忆 (semantic);
- 1976 年 Anderson 在 ACT 理论中引入程序记忆 (procedural)。
这里的每一种记忆系统,都经过了数十年认知科学研究的反复验证,是相当稳固的结论。
需要说明的是,认知科学本身更倾向于把它们组织成一个层级结构(感觉记忆 → 短期 / 工作记忆 → 长期记忆,长期记忆再分为陈述性[情节 + 语义]与非陈述性[程序])。而把"工作 / 情节 / 语义 / 程序"拉平成四类、并逐一映射到 LLM Agent,则是近年 Agent 学界的综合——最具代表性的是 2023 年的 CoALA(Cognitive Architectures for Language Agents)论文,它明确提出语言 Agent 的记忆正对应这四种类型。
业界之所以敢直接把这套框架搬过来,是因为这并非简单类比,而是在功能层面真的同构:
| 人类记忆 | Agent 记忆 |
|---|---|
| 工作记忆(short-term,当下心里正想的事) | 当前对话的消息历史 |
| 情节记忆(过去发生过的具体事件) | 过去会话、过去交互的回顾 |
| 语义记忆(与时间无关的事实知识) | 企业知识库、文档、API 规范 |
| 程序记忆(怎么做某件事的流程性知识) | 系统提示词、Skills、工作流模板 |
这套框架为工程决策提供了依据。每类记忆有不同的容量、不同的时效、不同的访问模式;承载它们的技术也应该不同。
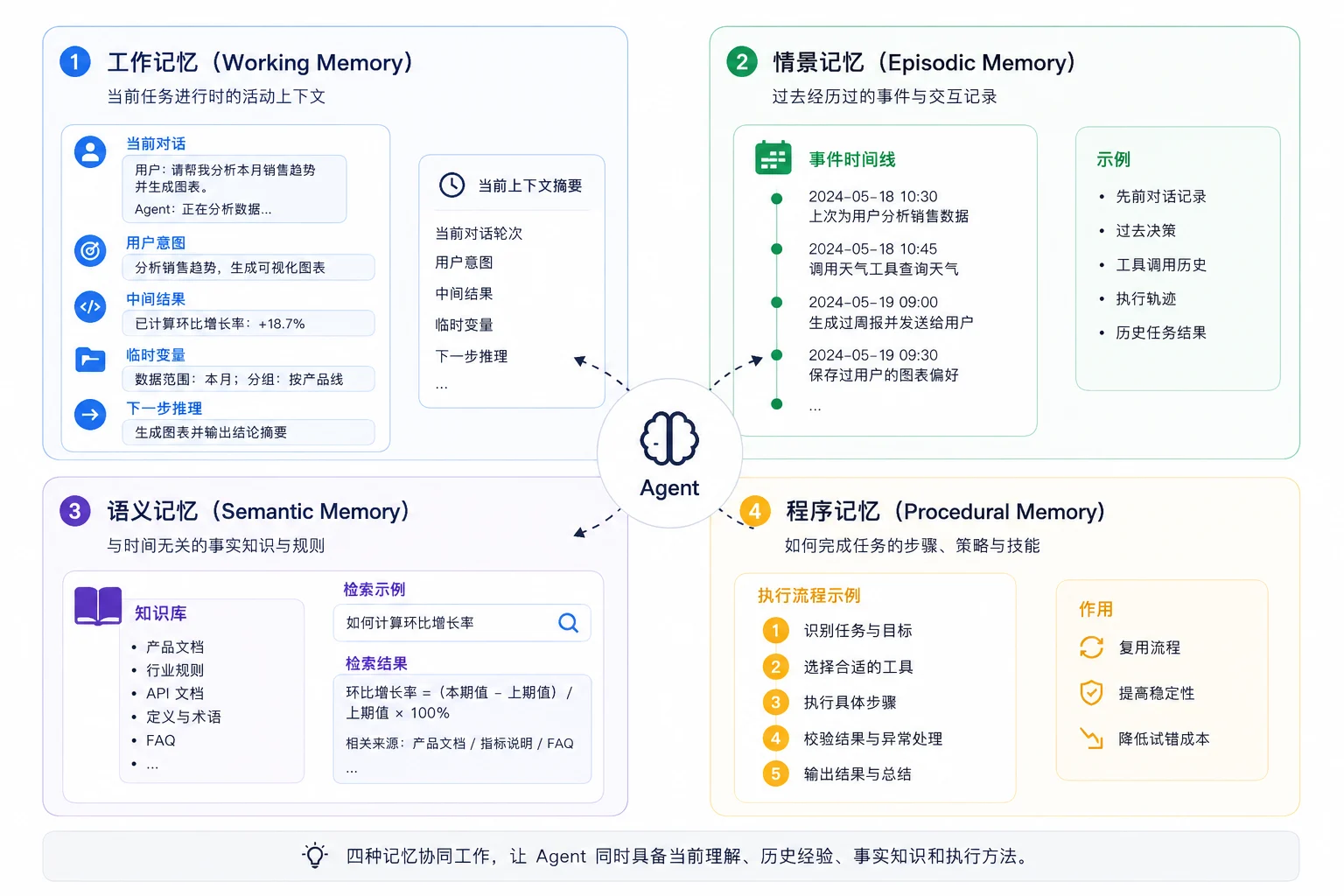
AI Agent 的记忆体系一般从两条主线来划分:按存续时间(生命周期) 和 按内容性质(认知类型)。两条线互相交叉,大多数框架的实际设计都是这两者的组合。
按生命周期划分
- 短期记忆 / 工作记忆(Short-term / Working Memory) 绑定单次会话或单个任务,本质上就是塞进上下文窗口的那部分内容——当前对话历史、ReAct 的中间推理轨迹、临时的 scratchpad、工具调用的中间结果。它随会话结束而消失,容量受 context window 限制。常见实现是 conversation buffer(完整历史)和 summary buffer(滚动摘要,防止 token 溢出)。
- 长期记忆(Long-term Memory) 跨会话持久化,存在外部存储里(向量库、KV、关系库、图数据库),通过检索按需召回到上下文。它解决的是"Agent 关掉再打开还记得你是谁"的问题。
按内容性质划分
- 情景记忆(Episodic Memory) 记录"发生过什么”——具体的历史交互、过往任务的执行片段、某次对话里用户说过的话。通常以事件/对话片段的形式存储,用相似度检索召回。Few-shot 中"过去成功解决类似问题的案例"也属于这一类。
- 语义记忆(Semantic Memory) 存"事实与知识"——关于用户的稳定信息(偏好、身份、关系)、关于世界的知识、领域知识库。RAG 接的外部知识、用户画像都落在这里。它不关心"什么时候知道的",只关心"是什么"。
- 程序性记忆(Procedural Memory) 存"怎么做"——技能、工作流、行为规则。一部分固化在模型权重里,另一部分体现在 system prompt、工具使用规范、可复用的任务模板上。一些支持自我改进的 Agent 会把"这次踩坑总结出的经验规则"写回程序性记忆。
工程上常见的几种补充类型
- 实体记忆(Entity Memory):专门追踪对话中出现的实体(人、项目、对象)及其属性变化,LangChain、CrewAI 里都有独立实现。
- 状态记忆(State Memory):Agent 当前的执行状态、变量、计划进度,在 LangGraph 这类基于状态机的框架里是一等公民。
四种记忆的职责对比
把四类记忆放到工程坐标里看,每一类的"存什么、存多久、怎么读、怎么写、典型容量"都不同:
| 维度 | 工作记忆 | 情节记忆 | 语义记忆 | 程序记忆 |
|---|---|---|---|---|
| 内容 | 当前对话上下文 | 过去交互 / 会话 | 客观知识 / 文档 / 数据 | 流程 / 模板 / 技能 |
| 时间性 | 当下,几分钟到几小时 | 过去,几天到几年 | 与时间无关 | 与时间无关 |
| 容量 | 受 token 窗口限制(K 级) | 中(M 级:几千场对话) | 大(G 级以上:几百万文档) | 小(K 级:几十几百个模板) |
| 读法 | 全量放进 prompt | 按需检索(最近 / 最相关) | 按需检索(语义匹配) | 全量放进 system prompt |
| 写法 | 自动追加(每轮对话) | 会话结束总结后写入 | 离线批量索引 | 人工编辑 |
| 淘汰 | 滚动覆盖 / 压缩 | 按时间衰减 / 按重要性 | 文档过期或失效后下架 | 版本管理 |
| 典型存储 | 内存数组 + checkpoint | PostgreSQL + 向量库 | 向量库 + 全文索引 | 文件系统 + 配置 |
| 课程对应 | M04 4.10 + M09 9.3 | 本章思路同样适用 | 本章主线 RAG | M06 6.8 Skills |
| 典型问题 | 上下文爆炸 | 不知道该忘什么 | 检索召回不够 | 版本与权限管理 |
值得重点说一下的几组最容易混淆的边界情况:
- 工作记忆 vs 情节记忆:工作记忆是"当下这场对话",情节记忆是"过去那些对话"。会话结束的瞬间工作记忆要么丢弃、要么蒸馏总结后写入情节记忆——这个"什么该被记住、怎么压缩"的决策则是 M09 9.3 历史压缩要解决的。
- 情节记忆 vs 语义记忆:情节带时间标签(“用户王某上周三问过 X”),语义不带(“我们的退货政策是 7 天”)。情节会"过时",语义除非主动下架否则不过期。
- 语义记忆 vs 程序记忆:语义是"是什么"(事实陈述),程序是"怎么做"(步骤、技能、模板)。例如:“我们的 API 默认超时 30 秒"是语义;“如何处理一次退款"是程序。
记忆、上下文与知识库
这三个概念经常会被混用,但它们其实处在不同的抽象层:
上下文 (context) 是指一次模型调用输入的所有 token 的总和。它是最贴近模型的"瞬时输入”,大小受 context window 限制(8K / 32K / 128K / 1M 不等)。每次模型调用上下文都要重新组装。它不持久存在——这次调用结束就消失。
记忆(memory) 指的是跨调用 / 跨会话持久存储的信息总和。它有四种类型,各有自己的存储介质。记忆是信息池,每次模型调用从信息池里取出一部分放进上下文。
知识库(knowledge base, KB)是"语义记忆"的具体载体——一套企业内部存放、索引、检索文档的系统。它是工程产品,有 UI 有 API,可以独立部署。一个 Agent 可以接好几个 KB(产品 KB、运维 KB、合规 KB)。
它们之间的关系可以用下面的图来概括:
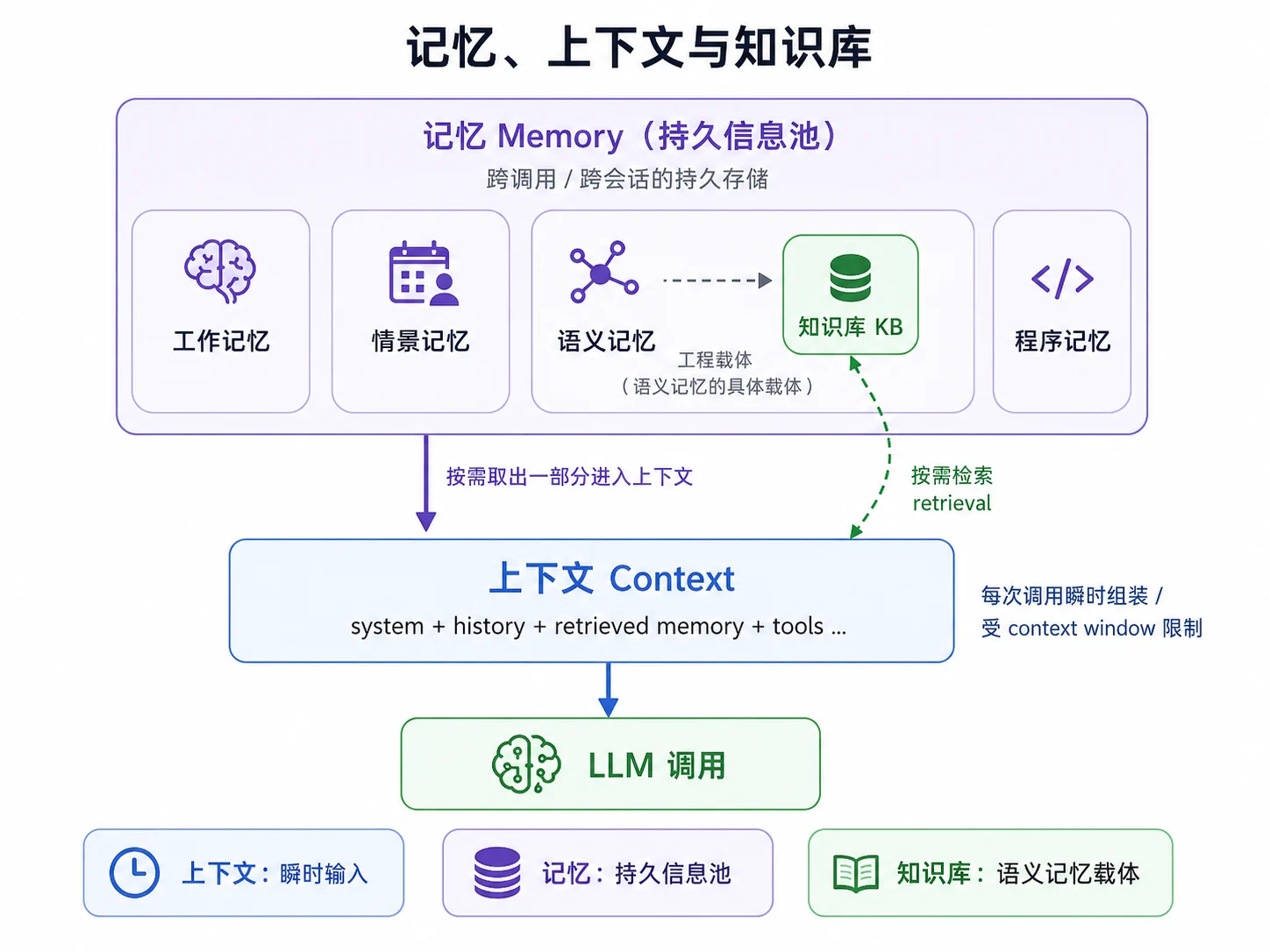
一句话总结:记忆是水池,上下文是从水池里舀的一勺。知识库是水池的一个具体形态(承载语义记忆)。
有了 RAG 就是有记忆了吗?并不是。RAG 只覆盖语义记忆这一种;对话历史、用户偏好、过去交互都还要单独管理。模型的上下文窗口是针对单次会话而言,上下文窗口再大也是瞬时的,并不能解决跨会话持久化问题。
记忆的工程问题
工程上实现一套记忆系统的难点主要在以下三个方面:
写什么
不是所有信息都该被记住。
会话结束后要写入情节记忆吗?写什么?
- 用户每一句话都存吗 → 隐私问题 + 噪声多
- 只存"用户偏好"吗 → 怎么提取偏好?
- 整段对话摘要写入吗 → 谁来摘要?用便宜的小模型?
- 标记重要性吗 → 重要性由谁判断?
业界通用做法是摘要 + 实体抽取,用一次小模型调用从对话里提"实体 + 偏好 + 决策"而不是存全部对话内容。
读什么
应该什么何时检索?检索多少?结果怎么排序?
模型调用之前要从记忆里取相关内容放进 prompt。但:
- 何时取?每轮都取吗(贵)还是模型主动调"召回工具”(灵活)?
- 取多少?top 5 还是 top 20?多了上下文爆炸,少了召回不够
- 怎么排序?最近优先?最相关优先?重要性加权?
这正是后面“混合检索与 rerank”要回答的问题。到了 Agentic RAG 部分,我们会把"何时取"这个决策权交给模型自己。
丢什么
记忆系统的容量满了之后应该删谁?
记忆不能无限增长。容量满时有四种淘汰策略(借鉴操作系统页面置换):
| 策略 | 选谁丢 | 适用 |
|---|---|---|
| LRU | 最久没访问的 | 通用,简单 |
| LFU | 访问次数最少的 | 长期低频但重要的会被错杀 |
| 时间衰减 | 越老权重越低,组合分数最低的丢 | 模拟人脑遗忘曲线,适合情节记忆 |
| 重要性 + 时间 | 用一个分数综合算 | 最贴近人脑,但实现复杂 |
人脑遗忘曲线(Ebbinghaus 1885)告诉我们:新鲜信息记得最牢,几天后会衰减 50% 以上,几个月后只留下被反复用到的那部分。情节记忆的淘汰策略应该模仿这条曲线——给每条记忆一个时间衰减因子,反复访问可以"提醒"它从而延寿,长期不访问就自动失效。
这三件事——写什么 / 读什么 / 丢什么——是 M09 9.1 上下文工程的核心命题。本章我们先把语义记忆(知识库 + RAG)做扎实,M09 9.8再讲跨四种记忆的统一治理。
本章范围
本章主要以语义记忆为主线
- 它是企业级 Agent 最普遍的需求——客服、文档助手、研究助理、代码助手、运维助手,几乎都要解决"让 Agent 看着公司内部文档回答"
- 它的工程挑战最完整——索引、切分、向量化、检索、重排、评估,几乎涵盖了 RAG 全部技术栈
- 它的技术可以迁移到情节记忆——学完本章的检索技术,把"历史会话"当成"文档"存进 KB 就能复用
下面我们就用"如何让 Agent 看着企业知识库回答"作为主线,系统讲清整套 RAG 技术栈。
7.2 RAG
语义记忆的工程实现就是 RAG(Retrieval-Augmented Generation,检索增强生成)。这一节系统介绍为什么需要 RAG、它与微调的根本区别、它由什么组成、怎么工作、有几代演进、什么场景下不该用、怎么评估好坏。
为什么需要 RAG
大模型有两个根本局限:
- 它不知道你的私有数据——内部文档、实时业务数据、客户信息、API 规范,都不在它的训练集里
- 它的知识有一个训练截止日——具体每家厂商每个版本的截止日以官方说明为准(各家披露口径不一,且常常只到月份/季度级别),任何模型都没有训练完成日之后的新知识——这是物理事实
举具体例子。问 LLM:
“我们公司的退货政策是什么?”
它不可能知道答案——你们公司的退货政策从未公开过(私有数据)。它只有两条路:承认不知道(诚实但没用)、或者编一个看似合理的答案(幻觉,生产事故)。
再问:
“我们昨天发布的 v2.3.7 hotfix 改了什么?”
如果训练数据停在某个时间点之前、而你们昨天发的版本在那之后——同样不可能知道,只能给出没有依据的猜测。关键不是"训练截止具体是哪天"而是"任何 LLM 都看不到训练完成之后的信息"。
RAG 的思路很直接:既然模型不知道,那就在它回答前先从知识库里检索出相关资料放进 prompt,让它基于资料回答。
这件事改变了模型的运作模式:从"仅凭参数记忆作答"变成"依据外部资料作答"——你给它资料,它阅读理解后作答。这一变化带来三个工程价值:
- 知识可实时更新:换新版资料,模型立即"知道";不用重新训练模型
- 来源可追溯:答案的依据是哪一段资料,可以指给用户看(citation)
- 私有数据不出域:把资料临时放进 prompt,不需要"训练"模型,数据不进模型权重
RAG vs Fine-tuning
学员第一次接触 RAG 经常问:“为什么不直接微调一个模型让它’知道’我的数据?”
这个问题值得展开说一下。
微调(Fine-tuning) 是走另一条路:用你的数据继续训练模型,让"知识"被编码进模型权重。听起来简单直接——模型直接有了我的数据,不用每次组织资料。但是走这条路的成本很高:
| 维度 | RAG | Fine-tuning |
|---|---|---|
| 知识更新 | 改资料即生效 | 重训(几小时到几天) |
| 来源追溯 | 可以指给用户看出处 | 不可,知识混进权重 |
| 数据合规 | 数据不进模型,可控 | 数据进权重,难删除(GDPR 担忧) |
| 私有性 | 资料留在你的库里 | 模型一旦泄露,数据也泄露 |
| 成本 | embedding + 检索 + 模型调用 | GPU 训练 + 推理服务自托管 |
| 准确性 | 受限于检索质量 | 准确性可能高,但易过拟合 |
| 时效性 | 实时反映最新数据 | 训练截止那天的快照 |
| 灾难性遗忘 | 不存在 | 微调可能让原能力下降 |
| 多领域 | 多个 KB 切换即可 | 多领域微调难,易冲突 |
| 起步门槛 | 几百行代码 + 一个向量库 | 数据集准备 + 训练管线 + GPU |
最关键的是选好适合自己业务场景的路,什么场景该微调模型,什么场景该 RAG。
- RAG(95% 企业场景):内容会变(文档、政策、业务数据)、需要 citation、量大但每条不需深度记忆、合规对数据有要求
- 微调:风格 / 语气 / 输出格式定制(让模型说话像你品牌)、特定任务模式(医学诊断步骤、法律条款解析)、推理能力增强(需要在领域里"想得更深")
- 两者结合(理想方案):微调一个"懂你领域思维方式"的模型 + RAG 提供"具体事实",效果上限更高,但工程投入也更大
绝大多数企业 Agent 项目都是选择先把 RAG 做扎实再考虑模型微调。因为 RAG 已经能解决 80% 的问题了,做微调的边际收益往往不抵成本。
RAG 的形式化定义
RAG 的形式化定义如下:
RAG = Retriever(检索器) + Generator(生成器) + Augmented Prompt(增强提示词)三个组成部分缺一不可:
| 缺少的部分 | 退化成什么 |
|---|---|
| Retriever | 退化成普通调用,模型只能凭记忆答 |
| Generator | 退化成纯搜索引擎,返回原文不综合 |
| Augmented Prompt | 资料拿到了但组织方式不对,模型无法稳定依据资料回答 |
RAG 这个名字来自 Lewis 等 2020 年的论文 “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”(发表于 NeurIPS 2020)。论文里 Retriever 用的是 DPR(Dense Passage Retrieval),Generator 用的是 BART。论文最大的贡献是把"检索 + 生成"这套组合明确为一种通用 pattern——后来 ChatGPT 时代各家用 GPT / Claude 换掉 BART,用各种 embedding 模型换掉 DPR,但总体骨架没变。
RAG 的三步骨架
RAG 分为以下三个步骤,先记住这个骨架。后面所有内容都是在给这三步做优化:
索引(离线):把文档切成小块 → 每块向量化(embedding) → 存进向量库。这一步需要在文档入库时预先做好,后续都用得上。
检索(在线):用户提问 → 把问题向量化 → 在向量库里找最相似的几块。这一步必须快(秒级以下)。
生成(在线):把检索到的块作为上下文 → 连同问题一起发给模型 → 模型依据资料生成回答。这一步要让模型优先使用检索资料,而不是凭模型参数里的印象作答。
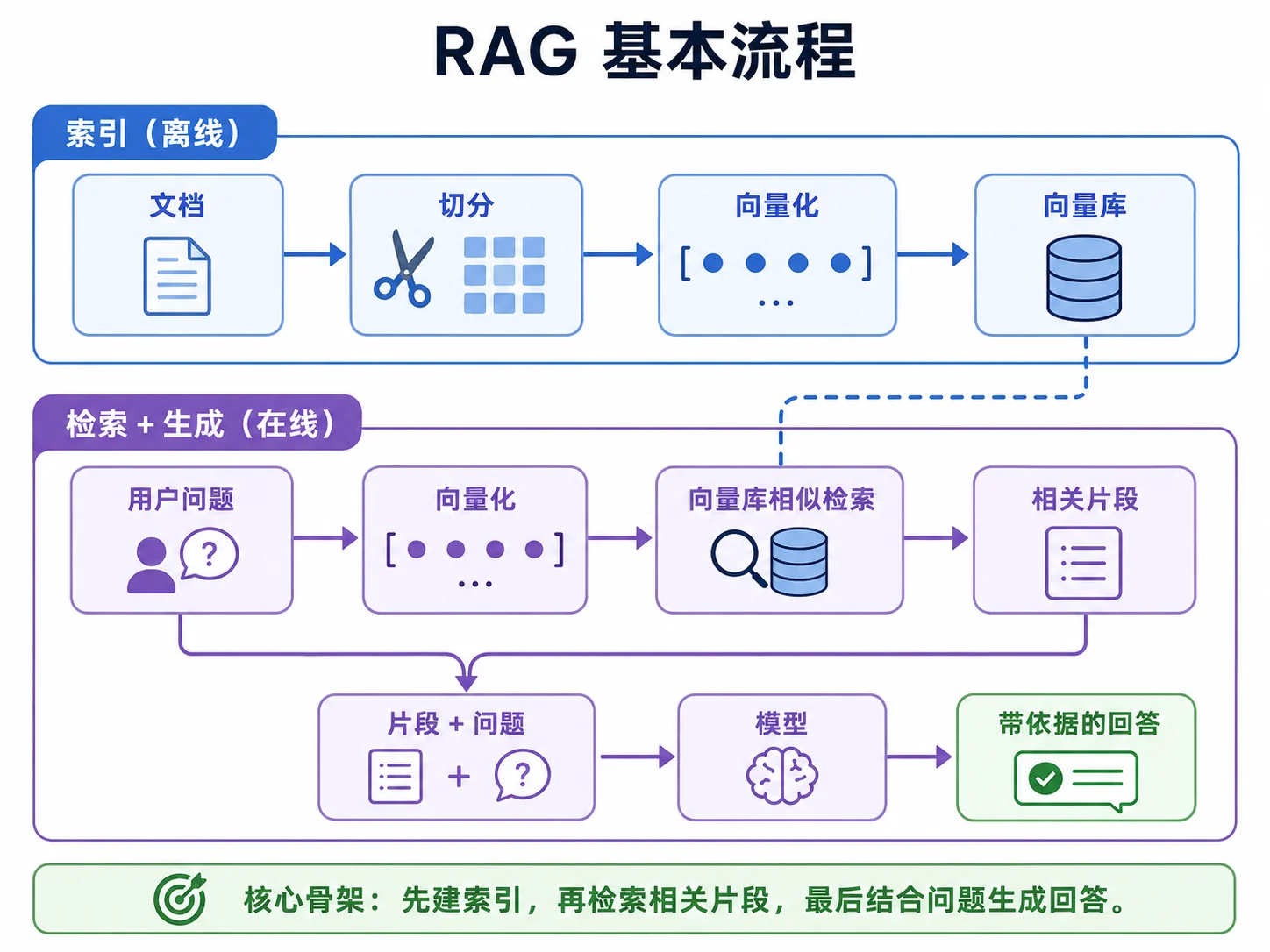
每一步都有关键决策点:
| 步骤 | 关键决策 | 本章对应 |
|---|---|---|
| 切分 | 切多大?如何处理跨段语义? | 文档切分 |
| 向量化 | 用什么模型?什么维度?多语言? | Embedding |
| 存储 | 用 pgvector / Milvus / Qdrant? | 向量数据库 |
| 检索 | 只向量 / 混合 / 加 rerank? | 混合检索与 rerank |
| 增强 | 怎么组织资料?多少?怎么让模型不无视? | Agentic RAG |
| 评估 | 怎么知道效果好不好? | M10 10.6 评估数据集与 RAG 指标 |
RAG 的演进谱系
RAG 从 2020 年提出至今,经历了至少四代演进。理解这条演进线你才知道遇到问题时该往哪个方向走。
2020 2023 2024 2024-2025 2025+
Naive → Hybrid → Agentic → GraphRAG → AgentMem /
RAG RAG RAG LazyRAG Long-Context-Tuning
│ │ │ │ │
│ │ │ │ │
"基础三步" "BM25+向量" "Agent 主导检索" "图结构+实体" "把记忆做成一阶能力"第 1 代:Naive RAG(2020-2022)
最基础的实现:文档分句切分 → 单个 embedding 模型向量化 → 余弦相似度 top-K 检索 → 放进 prompt。这是论文里的范式,理解 RAG 的起点。但生产里它有几个典型问题:
- 精确匹配容易失败,例如运单号、ID 等场景;
- 长文档信号被稀释(切大了找不到细节,切小了上下文不全)
- 多义词容易跑偏;
- 召回低:单靠向量,top-5 命中率可能只有 60-80%
第 2 代:Hybrid RAG(2023 起)
针对召回问题引入多路召回 + 重排:
- BM25(关键词)+ 向量(语义)双路召回
- RRF(Reciprocal Rank Fusion)合并两路
- Rerank 模型在合并结果上重排,把最相关的前 K 个挑出
工程上的复杂度会增加,但生产效果通常能稳定提升召回。后面的“混合检索与 rerank”会深入介绍这个路线。
第 3 代:Agentic RAG(2024 起)
前两代的核心问题是检索这件事是被动的——固定流程检索固定次数。但有些问题需要多轮检索(查 A 拿到结果发现还要查 B)、有些问题不需要检索(问"你好"也检索一遍会增加成本和噪声)、有些问题需要主动验证(检索回来的资料矛盾时怎么办)。
Agentic RAG 的思路:把检索包装成工具,让 Agent 在 M04 的循环里自主调用。模型自己决定:何时检索、检索什么、检索完是否够、要不要再检索一次。这就把 M04 Agent 循环、M06 工具系统和本章 RAG 组合起来——RAG 不再是固定管线,而是 Agent 的能力之一。后面的“Agentic RAG”会详细展开。
第 4 代:GraphRAG / LazyGraphRAG(2024 末起)
微软 2024 年提出 GraphRAG:索引时不只切块 + 向量化,还抽取实体 + 关系,建一张知识图谱;检索时既可以走向量(细节),也可以走图(整体结构)。优势是全局视角强(给 100 篇财报让你写"行业总结"纯 RAG 很难回答,GraphRAG 能走图汇总)。代价是索引成本高 5-10x——每篇文档都要跑一次 LLM 抽实体抽关系。
后来微软自己又推出 LazyGraphRAG(2025):索引时只切块向量化,等查询来了再 lazy 抽实体——把"昂贵 + 全局视角"做成按需付费。后文会做一个简要介绍。
第 5 代:正在发生(2025-2026)
学界与业界还在探索:
- AgentMem / MemGPT:把"记忆"做成 Agent 的一阶能力(主动写、主动读、主动忘),模拟人脑分层记忆
- 长上下文 + Tuning:Gemini 2M token / Claude 1M token 让"全文放进 prompt"成为可能,某些场景不需要 RAG
- Multimodal RAG:图、表、代码、音视频的统一检索
长上下文和 RAG 两者会长期共存,各自适合不同场景。
RAG 的局限
和 Embedding 一样 RAG 也有它的局限:
- 不是"知识问题"的场景
- 代码补全 / 重构 / 改写
- 文风转换、翻译、改写
- 计算密集型任务
这些场景下,“检索更多资料"不解决问题——模型不缺资料,缺的是推理或执行能力。RAG 解决的是"模型缺少外部知识"的问题,不能替代模型能力、工具执行或规则校验。
- 需要全局视角的场景
“对比 5 家竞品的财报”、“总结这本书的核心主张” —— 纯向量检索每次只能找几个最相关的 chunk,全局视角丢失。这是 GraphRAG / LazyRAG 试图补足的问题。
- 实时数据
“现在我账户余额是多少”、“昨天的销售数据” —— 这些不该走"文档 RAG”,该走 RAG over API。也就是把数据接口当成 Tool,交给 Agent 按需调用。
- 多模态混合内容
text-only RAG 看不见图、读不懂复杂表格、不理解代码语义。要么用专门的多模态 embedding,要么把图表 OCR / 描述后再 RAG —— 都是工程妥协。
- 极端高准确度场景
医疗诊断、法律判决、金融风控——RAG 召回上限 80-95% 仍可能不够,模型还会偶尔无视检索资料(hallucination)。这些场景往往需要规则引擎 + 专家系统 + RAG 多重保险不能光靠 RAG。
RAGAS 评估维度
RAG 怎么评估好坏?业界共识的四维指标(出自 RAGAS 框架):
| 维度 | 问什么问题 | 指标方向 |
|---|---|---|
| Context Recall(召回) | 该找到的资料找到了吗? | 高 = 该找到的没漏 |
| Context Precision(精度) | 找到的资料是相关的吗? | 高 = 找到的都对 |
| Faithfulness(忠实度) | 模型回答是不是基于检索的资料? | 高 = 没有编造或脱离资料 |
| Answer Relevancy(相关性) | 模型回答有没有答到用户问题? | 高 = 答的就是用户问的 |
这四个维度互相独立,任何一个低都说明 RAG 有问题:
- 召回低 → 改切分 / 改 embedding / 加混合检索
- 精度低 → 加 rerank / 改 top-K
- 忠实度低 → 改 prompt 让模型优先依据资料回答、加 citation 要求
- 相关性低 → 模型本身能力或 prompt 设计问题
本章地图
到此我们已经对 RAG 系统有了一个整体认识。本章接下来的每一节都是在“索引、检索、生成”这条三步骨架上做局部优化:
| 节 | 主题 | 解决哪一步 |
|---|---|---|
| Embedding | 文本向量化 | 向量化(索引步) |
| 文档切分 | RecursiveChunker | 切分(索引步) |
| 向量数据库 | pgvector 实战 | 存储 + 检索 |
| 混合检索与 rerank | 混合检索 + rerank | 检索质量(对应 Hybrid RAG) |
| HyDE | 假设答案改写 | 检索精度 |
| Agentic RAG | Agent 主导检索 | 第三代:让 Agent 主导 |
| GraphRAG 与 LazyGraphRAG | 图增强检索 | 第四代速览 |
| 长上下文 vs RAG | 经济学决策 | 方案取舍 |
接下来的内容将从 Embedding 开始解决这张演进谱系里的一个具体问题。
7.3 Embedding
前面说过 RAG 的第一步是"把文档向量化"。这一节系统介绍:为什么要向量化、向量化背后的原理是什么、什么时候会失效。如果你之前接触过 embedding 但只是"调一下 API 拿向量",这一节也是补地基的好时机。
为什么需要 Embedding
先看一个现实场景。你的客服系统里有这样一篇内部文档:
《宠物厌食症状识别与干预》 —— 当宠物连续 24 小时拒食或显著减食,常见原因有应激反应、消化系统疾病、口腔问题……
用户来问:“我家的猫不吃饭怎么办?”
这个问题与那篇文档字面零重合——「猫」≠「宠物」、「不吃饭」≠「厌食」、「怎么办」≠「干预」。但你和我都知道它们说的是同一件事。
传统检索是怎么做的?要么 SQL LIKE %猫% 找一遍、再 LIKE %不吃饭% 找一遍取交集——什么都找不到;要么用 PostgreSQL 全文索引(基于 TF-IDF / BM25)按词频权重打分——同样找不到,因为关键词压根没出现过。
类似的"语义对得上、字面对不上"的场景在企业知识库里比比皆是:
| 用户输入 | 文档原文 | 关键词匹配 |
|---|---|---|
| Go 开发面试题 | golang 笔试常考点 | ✗ |
| VM 启动慢 | 虚拟机性能调优手册 | ✗ |
| Postgres 慢查询 | 数据库性能优化指南 | ✗ |
| k8s 容器编排 | Kubernetes 集群管理 | ✗ |
| 如何配置超时 | 超时参数怎么设 | ✗ |
每一对的本质需求只有一句话:找意思相同的内容,不是找字面相同的内容。
传统检索靠加同义词词表、查询扩展、模糊匹配补救,每加一种语言/领域就要重做一遍——又是 N×M 重复劳动。Embedding 用一套通用机制一次性解决了"这段话表达的意思是什么"。
Embedding 是什么
一句话来说就是把每段文字变成多维空间里的一个点;意思相近的文字,点的位置也相近。
专业的说法是 embedding 是一个把文本映射到 n 维实数向量空间的函数:
f(text) → R^n n 通常取 384 / 768 / 1024 / 1536 / 3072二维直观图(真实空间是高维,这里为了方便演示降到二维):
语义维度 A
▲
│ ⭐ "我家的猫不吃饭怎么办"
│ ⭐ "宠物厌食症状识别"
│ ⭐ "如何让小狗多吃点"
│
│
│ ⭐ "汽车换轮胎教程"
│ ⭐ "车胎漏气怎么处理"
│ ⭐ "轿车保养间隔"
└──────────────────────────────▶ 语义维度 B左上角一簇都是"宠物 + 进食"语义,右下角一簇都是"汽车 + 维修"语义。两簇内部的点彼此靠近,两簇之间彼此远离——这就是"按意思找"的几何基础。
为什么位置相近就代表语义相近?
凭什么"意思相近的文字位置也相近"?这不是天然成立的几何规律,而是被"训练出来"的工程设计。
要把这个"训出来"讲透得从一个 60 多年的语言学公理说起。
分布假说(Distributional Hypothesis)——1954 年语言学家 Zellig Harris 提出的核心论断:
出现在相同语境中的词,往往具有相似含义。
通俗讲:两段文字如果经常出现在几乎一样的语境里,它们的语义大概率相似;反之上下文几乎不重叠,语义就基本无关。
- “开心"和"高兴"互换不影响句子合理性,上下文几乎一致 → 语义相近
- “苹果"和"香蕉"都常与「水果、吃、甜、削皮」搭配 → 语义相近
- “电脑"和"米饭"的上下文几乎不重叠 → 语义无关
分布假说是 embedding 体系的哲学根基。它的含义是:只要我们能让模型把"上下文共现关系"建模出来,就等于建模了语义。
下面就是 embedding 模型干的事——用一个数学优化问题把"上下文共现关系"翻译成"向量空间里的位置关系”。具体怎么翻译?后文会展开三种范式(Word2Vec / BERT / 对比学习)如何兑现这件事。这里先用一个简化的思想实验帮你建立感性认识。
一个简化的思想实验:假设一个 embedding 是 5 维向量,每一维都恰好对应一个可命名的隐性语义特征(真实模型的维度没有这么干净的物理意义):
| 维度 | 含义(假想) | “我家的猫不吃饭” | “宠物厌食症状” | “汽车换轮胎” |
|---|---|---|---|---|
| 1 | 这段话有多"关于动物” | 0.92 | 0.88 | 0.05 |
| 2 | 这段话有多"涉及健康/不适” | 0.75 | 0.90 | 0.10 |
| 3 | 这段话有多"机械/工业" | 0.05 | 0.10 | 0.95 |
| 4 | 这段话有多"焦虑/求助" | 0.60 | 0.35 | 0.20 |
| 5 | 这段话有多"日常生活" | 0.80 | 0.55 | 0.60 |
把每行看成一个 5 维向量。前两段在维度 1、2 上取值都很高、在维度 3 上都很低——它们在 5 维空间里的位置自然就靠近。第三段在维度 3 上独占一方、在维度 1 上垫底——它的位置与前两段自然就远。
几何上的"靠近"只是结果,真正的因果链条是:
意思相近的两段文本
│
▼
在 N 个语义维度上的取值相似
│
▼
N 维向量的几何位置接近
│
▼
余弦相似度 / 距离指标算出来的值很高实际的嵌入(embedding)模型维度通常为 384、1536、3072 等,但每个维度并不对应某个可明确命名的具体特征 —— 而是成百上千个抽象语义特征交织形成的混合编码,这在机器学习领域被称为分布式表示(distributed representation)。我们不可能拆开模型指着某一维说 “第 173 维就是专门对应「动物」概念的”。 但核心的直观逻辑依然成立:模型把「分布假说定义下的语义相近关系」编码进了各维度的数值组合之中,向量在空间上的几何邻近,只是这一机制的必然结果。
讲到这里你应该清楚了:“位置相近 = 语义相近” 并不是向量空间天生就有的规律,而是模型在工程训练中被刻意塑造出的特性,它的底层根基就是分布假说这一语言学核心假设。 就像我们约定平面坐标系里 x 轴向右代表数值增大一样,让嵌入空间的距离对应语义相似度,也是模型设计者做出的设计约定。而这个约定之所以能成立,正是因为分布假说在大规模真实文本中被反复验证,有着扎实的统计支撑。
总结
“embedding"这个英文词字面意思就是"嵌入”——把一段离散、不可比较的文字嵌进一个连续、可计算的几何空间。一旦进入了空间,所有几何工具(距离、角度、聚类、降维)都能用。而"进了空间之后位置代表意思"这件事,是模型基于分布假说训出来的能力。
向量距离与语义距离
检索的本质在 embedding 视角下就简化成了找最近的几个点。
完整链路:
索引(离线): 文档 ──embed──► 向量 ──► 入库
检索(在线): 问题 ──embed──► 问题向量
│
▼
[在库里找最近的 K 个向量]
│
▼
返回最近邻对应的原文片段“近"怎么定义?有三种主流距离度量,各有适用:
| 度量 | 公式 | 范围 | 适用 |
|---|---|---|---|
| 余弦相似度 | cos(θ) = A·B / (|A|·|B|) | [-1, 1],越大越相似 | 最常用:看方向,忽略长度 |
| 欧氏距离 | √Σ(aᵢ - bᵢ)² | [0, ∞),越小越近 | 直觉好理解,但高维下失真 |
| 点积 | A·B | (-∞, ∞),越大越相似 | 速度最快,但受向量长度影响 |
在实际工程落地中,95% 以上的场景都会选用余弦相似度来计算向量相似度。原因很简单:嵌入模型输出的向量,其长度通常不承载语义信息 —— 很多模型会对向量做 L2 归一化处理,让所有向量的长度都统一等于 1,真正决定语义的是向量的方向。 打个比方,比较两个向量的长度,就好比比较两篇文档的字数多少:字数多少和 “两篇内容讲的是不是同一件事” 几乎没有关系。而比较向量方向(也就是余弦相似度的核心),本质是在判断它们指向的是不是同一个语义方向。
使用 Go 语言实现余弦公式,作为后续判断检索结果合理性时会用到的基础函数:
package rag
import "math"
// cosine 计算两个等长向量的余弦相似度,范围 [-1, 1],越大越相似。
func cosine(a, b []float32) float32 {
if len(a) != len(b) {
return 0
}
var dot, na, nb float64
for i := range a {
dot += float64(a[i]) * float64(b[i])
na += float64(a[i]) * float64(a[i])
nb += float64(b[i]) * float64(b[i])
}
if na == 0 || nb == 0 {
return 0
}
return float32(dot / (math.Sqrt(na) * math.Sqrt(nb)))
}实际项目里你不会自己算(向量库内置实现且做了 SIMD 加速),但当你看检索结果里 “这两段分数 0.85,那两段才 0.42”——你心里应该清楚这分数实际是两个向量在 1536 维空间里的夹角的余弦,分数越高代表它们越相似。理解到这一层对我们后面调用检索很重要。
Embedding 模型的训练范式
上一节我们提到了分布假说,这里抛出一个核心问题:模型是怎么习得「让语义相近的文本在向量空间中彼此靠近」的能力?
答案是精心设计的训练目标 + 海量训练样本。在 Embedding 模型的发展史上,先后出现过三种主流训练范式,它们本质上都是分布假说的不同工程实现,能力层层递进:
Word2Vec
Word2Vec 是分布假说最直白的落地:一个词的语义,由它周围的上下文词定义。它包含两种训练模式:
- Skip-Gram:用中心词预测滑动窗口内的上下文词
- CBOW:用上下文词预测中心词
举个例子:句子「我 爱吃 苹果」,取滑动窗口内的 [爱吃, 苹果] 作为“苹果”的上下文。整个训练流程是:
- 随机初始化每个词对应的向量
- 用「苹果」的向量预测「爱吃」(或反过来)
- 预测存在误差 → 通过反向传播更新向量参数
经过海量文本的反复迭代优化:
- 经常互为上下文的词(比如苹果/香蕉、猫咪/小狗),向量距离会逐步拉近
- 几乎没有共现关系的词(比如苹果/键盘),向量距离会逐步拉远
这就是经典"语义算术"现象成立的原因:
国王 - 男人 + 女人 ≈ 女王
巴黎 - 法国 + 日本 ≈ 东京向量的相对位置直接编码了语义关系,这就是 Embedding 技术的魔力。但 Word2Vec 也有明显局限:它只关注局部小窗口的共现,产出的是词级 Embedding,对整句话的语义表征能力有限。
BERT / MLM 预训练
BERT 通过掩码语言模型(Masked Language Modeling, MLM),把分布假说的适用范围从“局部窗口”扩展到了“整句级别”:随机遮住句子中的某个词,让模型利用整句的双向上下文还原被遮住的内容。
底层逻辑依然延续了分布假说,只是上下文的范围更大了:
- 句子 A:「今天天气很不错」
- 句子 B:「今日天气挺好的」
两句话的上下文和表达意图完全一致,模型为了降低还原误差,会持续压缩二者的向量距离。
但原版 BERT 直接用来做检索效果并不好——它的训练目标是“还原被遮挡的词”,而非“判断两句话的语义相似度”。因此后续衍生出了 SBERT(Sentence-BERT):在 BERT 的基础上,用孪生网络结构专门针对句子相似度任务做了微调,让模型的能力从“填词”升级为“判断句子相似性”。SBERT 才是检索类 Embedding 真正的起点。
对比学习
如今业界 SOTA 级别的 Embedding 模型(比如 OpenAI text-embedding-3、Voyage-3、BGE-M3、Cohere v3),几乎都采用对比学习范式。它的逻辑最直接:
- 构造正样本对:语义相近的两段文本——比如搜索 Query + 用户实际点击的文档、问答对、同义改写句、同一句话的多语言翻译等
- 构造负样本对:随机配对的不相关句子
- 训练目标(InfoNCE / Triplet Loss):拉近正样本对的向量距离,推远负样本对的向量距离
经过千万到十亿级别样本对的训练后,整个高维向量空间会自然形成语义聚类:同类语义的文本聚在一起,不同语义的文本相互分隔。到这一步,「位置相近 = 语义相近」就被训练目标强约束住了——这也是对比学习训练的模型长期霸占 MTEB 检索榜前列的核心原因。
三种范式的本质共性
| 范式 | 出现时期 | 上下文范围 | 训练信号 |
|---|---|---|---|
| Word2Vec | 2013年 | 小窗口(5–10个词) | 窗口内中心词 ↔ 上下文的共现预测 |
| BERT / MLM | 2018年起 | 整句双向 | 还原被遮蔽的词;SBERT 额外增加句对相似度任务 |
| 对比学习 | 2022年起 | 句子对 / 跨样本 | 拉近正样本对、推远负样本对 |
三种范式本质上是相通的:都是对分布假说的工程化落地——给模型输入大量“哪些文本应该靠近、哪些应该远离”的信号,优化向量参数,让几何位置反映语义关系。差异只在于上下文范围越来越大,训练信号越来越直接对齐“语义相似度”这个最终目标。
这里也梳理一下主流模型的发展脉络,大家看到这些名字时能有个大致认知:
| 时期 | 代表模型 | 训练范式 | 关键贡献 |
|---|---|---|---|
| 2013–2018 | Word2Vec / GloVe | 窗口共现 | 奠定词级 Embedding 基础,提出“语义算术”概念 |
| 2019 | BERT | MLM | 开启句子级语义表征,但原生检索效果一般 |
| 2019–2021 | SBERT | MLM + 句对微调 | 检索类 Embedding 的真正起点,开源社区主流方案 |
| 2022 | OpenAI ada-002 | 对比学习 | 以 API 形式普及 Embedding,中文表现一般 |
| 2023–2024 | E5 / BGE / GTE | 对比学习 | 中文开源模型标杆(BGE 来自智源、E5 来自微软、GTE 来自阿里) |
| 2024–2025 | text-embedding-3 / Cohere v3 / Voyage | 对比学习 + Matryoshka | 高维 + 多语言 + 支持维度截断 |
| 2025–2026 | Voyage-3-large / BGE-M3 / Qwen3-embedding | 对比学习 + 大规模多语训练 | 榜单头部水平,中英多语言场景 SOTA |
绝大多数场景下,你都不需要自己训练 Embedding 模型,使用公开模型已经能覆盖绝大多数工程需求。从工程实践的角度看,更合理的路径是先选一个适配场景的现成模型,把索引、检索、评估和运维整套链路跑通。
Go 工程落地
讲完原理,我们落到代码实现上。生成 Embedding 需要调用模型服务,和之前对话模型的 Provider 设计思路一致,我们先定义一个中立的 Embedder 接口,屏蔽不同厂商的实现差异:
package rag
import "context"
type Embedder interface {
// Embed 批量把文本转成向量。批量是为了省往返、提吞吐。
Embed(ctx context.Context, texts []string) ([][]float32, error)
Dim() int // 向量维度,建表时要用(下一节 pgvector 列类型就是 vector(Dim()))
}Dim() 这个方法看起来不起眼,实际上是个硬约束:后面创建 pgvector 表时,维度是写死的(比如 vector(1536)),如果更换 Embedding 模型导致维度变化,整张表都需要重建。这一点在模型选型和后续扩展中会反复提到。
绝大多数厂商(OpenAI、国内各大模型厂商、Voyage、Cohere)都提供兼容 OpenAI 规范的 /embeddings 接口,因此实现方式和对话模型的套路一致:
package rag
// openaiEmbedder 走 OpenAI 兼容的 /embeddings 端点。
type openaiEmbedder struct {
baseURL, apiKey, model string
dim int
client *transport.Client // 复用 M01 的生产级客户端
}
func (e *openaiEmbedder) Dim() int { return e.dim }
func (e *openaiEmbedder) Embed(ctx context.Context, texts []string) ([][]float32, error) {
body, _ := json.Marshal(map[string]any{"model": e.model, "input": texts})
req, err := http.NewRequestWithContext(ctx, http.MethodPost, e.baseURL+"/embeddings", bytes.NewReader(body))
if err != nil {
return nil, err
}
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", "Bearer "+e.apiKey)
resp, err := e.client.Do(req) // M01 的 Client.Do:自动重试 429/5xx
if err != nil {
return nil, err
}
defer resp.Body.Close()
var out struct {
Data []struct {
Embedding []float32 `json:"embedding"`
} `json:"data"`
}
if err := json.NewDecoder(resp.Body).Decode(&out); err != nil {
return nil, err
}
vecs := make([][]float32, len(out.Data))
for i, d := range out.Data {
vecs[i] = d.Embedding
}
return vecs, nil
}(导入沿用 M01 生产级 HTTP 客户端与 M02 OpenAI 风格客户端中的 bytes、context、encoding/json、net/http、transport。)
Embedding 模型选型
选模型绝不是“盯着评测榜挑第一”这么简单,下面五个维度需要综合权衡:
- 向量维度——精度与存储成本的权衡
| 维度 | 单条向量占用 | 100万条占用空间 | 检索精度 |
|---|---|---|---|
| 384 | 1.5 KB | 1.5 GB | 中等 |
| 768 | 3 KB | 3 GB | 良好 |
| 1536 | 6 KB | 6 GB | 优秀 |
| 3072 | 12 KB | 12 GB | 优秀+ |
精度的提升并非线性:从 768 维升到 1536 维,提升效果很明显;但从 1536 维升到 3072 维,提升幅度会收窄,存储和计算成本却直接翻倍。默认选择 1536 维是性价比很高的甜点位(OpenAI text-embedding-3-small、BGE-large 都在这个量级)。
OpenAI text-embedding-3-large、Voyage-3-large 等较新的模型支持 Matryoshka 截断:同一个 3072 维的向量,可以截断到 1024 维甚至 512 维继续使用,精度会有可控的下降。这给了我们“先用高维 Embedding 上线,后续遇到成本压力再截断降维”的灵活空间。
- 语种适配
- 纯中文场景:BGE-M3 / Qwen3-embedding / 智源 / 阿里灵积 表现优秀,成本也更低
- 中英混合场景:OpenAI text-embedding-3 / Voyage / Cohere v3
- 跨语言检索(用中文查英文文档):BGE-M3 / Voyage 在设计时就考虑了跨语言场景
- 注意:ada-002 等老模型中文能力非常弱,不建议选用
- 调用成本(按百万 token 计算)
| 模型 | 价格 | 备注 |
|---|---|---|
| OpenAI text-embedding-3-small | 约 $0.02 | 1536 维,成本较低 |
| OpenAI text-embedding-3-large | 约 $0.13 | 3072 维,价格是前者的 6.5 倍,精度差距约 5–10% |
| Cohere embed-v3 | 约 $0.10 | 多语言能力强 |
| Voyage-3-large | 约 $0.18 | 榜单头部水平 |
| 国内 SaaS 服务(智谱 / 阿里 / 百川) | 0.5–2 元/百万 token | 通常比海外模型便宜 50–80% |
| 自托管(BGE / E5 + vLLM) | 服务器固定成本 | 流量大到一定程度会比 API 更划算 |
- API 调用 vs 自托管
| 对比项 | API 方案 | 自托管方案 |
|---|---|---|
| 上手难度 | 一行代码调用 | 需要部署 GPU 服务 |
| 合规性 | 数据出域(部分场景可能不允许) | 内网部署,数据可控 |
| 延迟 | 网络往返 50-200ms | 内网访问 10-30ms |
| 成本 | 按 token 按量计费 | 服务器固定成本 |
| 维护成本 | 零维护 | 需要关注 OOM、扩容等问题 |
- 模型版本兼容性——重要的工程约束
一旦更换 Embedding 模型,整个知识库的向量都必须重新计算。不同模型的向量空间完全不兼容:维度不同直接无法使用,维度相同也会是完全不同的几何分布。因此选型时,要把它当作“一旦上线就很难更换”的决策来对待。
MVP 阶段可以选小参数、快速度的模型跑通流程,但一定要预留“全量重索引”的运维通道(比如连接器异步全量重算 + 双写过渡期 + 平滑切换),避免后续升级时卡壳。
实操建议:可以参考 MTEB Leaderboard(Massive Text Embedding Benchmark)(Massive Text Embedding Benchmark)排行榜,按“语种 + 任务类型(检索)”筛选,从前 10 名里找同时满足合规、价格、维度要求的模型。看公开中立的排行榜,比看任何厂商自宣的评测数据都靠谱。
Embedding 的局限
讲了这么多 Embedding 的优势,也得说清楚它不擅长什么——这正是我们后面要引入混合检索和重排的根本原因。
- 精确匹配场景失效
查询:"查一下运单 SF1234567890"
文档:"运单 SF1234567890 已签收"像 SF1234567890 这种特定标识,在 Embedding 的训练数据里几乎不会出现,模型对它没有“语义认知”,向量化后接近随机噪声。类似的场景还有:订单 ID、商品 SKU、IP 地址、UUID、手机号、邮箱。这类内容必须依靠 SQL、倒排索引或全文索引做精确匹配。
- 数值与时间范围查询失效
查询:"价格在 100 到 200 之间的商品"
查询:"最近 7 天的工单"Embedding 不携带时序信息,也不擅长数值比较运算。这类需求必须依靠结构化字段过滤(比如 WHERE price BETWEEN 100 AND 200、WHERE created_at > now() - interval '7 days')来实现。
- 否定/反义识别陷阱
"我喜欢猫" vs "我不喜欢猫"很多 Embedding 模型会把这两句话的向量放得很近——因为它们都在讨论“喜欢”和“猫”。高质量模型(比如 Voyage-3、BGE-M3)已经改善了这个问题,但仍容易混淆。对于合规判断、风险评估等关键决策类场景,一定要加上规则校验,不能纯靠 Embedding 相似度做是非判断。
- 长文档语义信号被稀释
一篇 5000 字的文档如果只生成一个向量,所有细节都会被“平均”成“这篇文章大概讲了什么”,某段关键内容会被整体淹没,检索时召不回来。解决方案是文档切分(chunking):把长文档切成 200-1000 字的小块,分别向量化、分别检索。这正是文档切分要解决的核心问题。
- 否定性查询能力弱
"找不含 SQL 注入的回答"Embedding 擅长“找相似”,不擅长“排除相似”,没法直接找出“不含某内容”的结果。 处理这类查询需要元数据过滤 + Embedding 组合:先用过滤条件排除带 SQL 标签的内容,再做 Embedding 相似度排序。
- 多模态场景需要专用模型
文本 Embedding 只能处理文本;图片、表格、代码、音频需要对应的专用 Embedding 模型(比如 CLIP、CodeBERT、Whisper 衍生模型),或者多模态统一模型(比如 Voyage-multimodal)。
- 一词多义陷阱
“Apple”既是水果,也是科技公司。如果训练数据同时包含两种用法,这个词的向量就会落在两个语义簇的中间位置——和两边都“有点像”但都不“很像”。
短查询尤其容易出问题:单独一句“我买了个苹果”,Embedding 无法判断该归到买水果簇还是数码簇。这是分布假说的天然短板——它默认一个词对应一种主流上下文分布,多义词违反了这个假设。常见的处理办法:
- 查询上下文扩充:让模型先生成一段假想答案再向量化,上下文展开后歧义自然消除。这个技巧就是后面要讲的 HyDE
- 产品侧消歧:提供候选词列表、领域过滤器
- 业务元数据区分:给不同业务域的文档打标签,检索时通过过滤条件限定范围
- 训练数据偏置——选错模型会导致误召回
Embedding 模型的“语义认知”完全由训练数据决定。一个主要在英文通用文本上训练的模型(比如早期的 ada-002),对中文专业领域(法律、医学、金融术语)的语义建模能力会很弱,会大量出现“向量距离近但语义无关”的情况。
更隐蔽的情况是:你的业务领域用词特殊,和公开训练语料的分布不一样。比如运维场景里,“重启”和“重发”完全是两回事,但在通用语料里它们的上下文高度重合——通用 Embedding 会把这两段内容拉得很近,但业务上需要它们明确区分。
选型时不能只看 MTEB 综合排名,还要关注对应领域的子榜单(MTEB 已经细分了金融、生物、代码、法律等领域),或者在自己的业务语料上做一次小规模评测:准备 20-50 对“应当相似”和“应当不同”的样本,计算不同模型的区分度。这一步在 MVP 阶段就该做,不要等上线后发现召回率差才回头排查。
把这些局限综合起来看:单靠 Embedding 的检索,召回率上限通常只有 60–80%。这正是混合检索方案的由来:
BM25(关键词) ──► 召回精确匹配的(运单号、ID、唯一名词)
向量(embedding) ──► 召回语义相近的(同义、上下位、跨语言)
────────────── RRF 合并 ──────────────
│
▼
reranker 重排
│
▼
top-K 给模型这一节我们把 embedding 这一层夯实了——它是基础,但不是全部。接下来会依次解决长文档怎么切、向量怎么存、以及怎么把 embedding 与关键词检索合起来用。
7.4 文档切分
为什么非要做文档切分?核心原因有两个:一是 Embedding 模型有输入长度上限,整篇长文无法直接处理;更重要的是检索粒度的问题。如果一整篇文档只对应一个向量,检索回来的是整篇内容,里面大部分和问题无关,既稀释了有效信息,又浪费上下文窗口。切成小块,才能精准定位到“就是讲这件事的那一段”。
但切分不能乱切。如果在句子中间硬生生切断,会把完整语义劈成两半。好的切分要尽量在自然边界处切割(优先级:段落 > 句子 > 词),并且让相邻块保留一定重叠(overlap),避免关键信息正好落在切口处,被分到两个块里。
这就是 RecursiveChunker(递归字符切分)的核心思想:优先用粗粒度的分隔符(比如段落)切,切完还是太大,就降级用更细的分隔符(句子、标点),直到每块都不超过目标大小。
我们来手写一个实现。首先是配置和入口函数:
package rag
import "strings"
type RecursiveChunker struct {
ChunkSize int // 每块目标最大长度(按 rune 计,对中文友好)
Overlap int // 相邻块重叠长度
Separators []string // 分隔符,从粗到细,如 ["\n\n", "\n", "。", "!", "?", " "]
}
func NewRecursiveChunker(chunkSize, overlap int) *RecursiveChunker {
return &RecursiveChunker{
ChunkSize: chunkSize,
Overlap: overlap,
Separators: []string{"\n\n", "\n", "。", "!", "?", "; ", " "},
}
}
func (c *RecursiveChunker) Split(text string) []string {
atoms := c.recurse(text, 0)
return c.addOverlap(atoms)
}核心是 recurse 方法:用当前层级的分隔符切割,对仍然超标的片段递归使用更细的分隔符,最后把碎片贪心合并成不超过 ChunkSize 的块:
func (c *RecursiveChunker) recurse(text string, sepIdx int) []string {
if len([]rune(text)) <= c.ChunkSize {
if strings.TrimSpace(text) == "" {
return nil
}
return []string{text}
}
if sepIdx >= len(c.Separators) {
return hardSplit([]rune(text), c.ChunkSize) // 没有更细的分隔符了,硬切
}
sep := c.Separators[sepIdx]
parts := strings.Split(text, sep)
// 把仍然过大的 part 用更细的分隔符进一步切碎,得到一串“原子片段”
var atoms []string
for _, p := range parts {
if len([]rune(p)) > c.ChunkSize {
atoms = append(atoms, c.recurse(p, sepIdx+1)...)
} else if strings.TrimSpace(p) != "" {
atoms = append(atoms, p)
}
}
// 贪心合并相邻原子,尽量填满每一块
return mergeAtoms(atoms, sep, c.ChunkSize)
}
// hardSplit 在没有任何自然边界时按定长硬切(最后的兜底)。
func hardSplit(runes []rune, size int) []string {
var out []string
for i := 0; i < len(runes); i += size {
end := i + size
if end > len(runes) {
end = len(runes)
}
out = append(out, string(runes[i:end]))
}
return out
}
// mergeAtoms 用分隔符把原子片段贪心拼成 ≤ chunkSize 的块。
func mergeAtoms(atoms []string, sep string, chunkSize int) []string {
var out []string
var cur strings.Builder
curLen := 0
flush := func() {
if curLen > 0 {
out = append(out, cur.String())
cur.Reset()
curLen = 0
}
}
sepLen := len([]rune(sep))
for _, a := range atoms {
al := len([]rune(a))
add := al
if curLen > 0 {
add += sepLen
}
if curLen > 0 && curLen+add > chunkSize {
flush()
add = al // 新块开头不加分隔符
}
if curLen > 0 {
cur.WriteString(sep)
}
cur.WriteString(a)
curLen += add
}
flush()
return out
}最后给相邻块加上重叠:把上一块的尾部拼到下一块的开头。
func (c *RecursiveChunker) addOverlap(chunks []string) []string {
if c.Overlap <= 0 || len(chunks) <= 1 {
return chunks
}
out := make([]string, len(chunks))
out[0] = chunks[0]
for i := 1; i < len(chunks); i++ {
prev := []rune(chunks[i-1])
tail := prev
if len(prev) > c.Overlap {
tail = prev[len(prev)-c.Overlap:]
}
out[i] = string(tail) + chunks[i]
}
return out
}ChunkSize 取 300~500 字、Overlap 取 50 字左右,是比较稳妥的通用配置。切分质量是 RAG 系统里经常被低估、但对效果影响极大的一环——切得好,后面的检索和重排才有好的素材;切得太碎或者切断语义,后续模型也很难补救。生产环境也可以用现成的切分库,但核心原理就是上面这套递归切分 + 贪心合并 + 重叠补全的思路。7.5 向量数据库
解决了向量化和文档切分,接下来就是怎么存、怎么查的问题。这一节我们系统讲透向量数据库:为什么传统数据库做不了、它的核心组成是什么、主流近邻搜索算法怎么选、市面上的系统怎么挑,最后落到 pgvector 的工程实战。
为什么需要向量数据库
先看一个具体场景:你有 100 万条文本片段,每条向量化成 1536 维的 float32 向量。用户提一个问题,你想找出最相似的 5 条。能不能用传统 SQL 实现?
朴素做法:把向量存在 PostgreSQL 的 float[] 列里,写一条 SQL:
SELECT id, content FROM chunks
ORDER BY cosine_similarity(embedding, query_vec) DESC LIMIT 5会发生什么?
- 没有可用索引:B+ 树索引擅长精确匹配和范围查询(比如
WHERE id = ?、WHERE age > 18),不擅长“按相似度排序”这种操作 - 全表扫描:每次查询都要遍历 100 万行,每行计算一次 1536 维向量的余弦相似度
- 单次余弦相似度计算需要 1536 次乘法 + 1536 次加法 + 一次开方
- 总计约 1500 亿次浮点运算
- 在普通服务器上耗时几十秒到几分钟——完全不可用
核心认知:向量检索是“找最近邻(Nearest Neighbor)”,不是“找相等的值”。这是两种完全不同的操作:
| 操作 | 数据结构 | 复杂度 | 代表 |
|---|---|---|---|
| 精确匹配 | B+ 树 / Hash | O(log N) | 传统 SQL WHERE id = ? |
| 范围查询 | B+ 树 | O(log N + K) | WHERE age BETWEEN ... |
| 全文检索 | 倒排索引 | O(log N) | PostgreSQL tsvector + GIN |
| 最近邻检索 | 专用 ANN 索引 | O(log N) 近似 | 向量数据库 |
最近邻检索需要专门的算法支撑——这就是向量数据库存在的核心价值。
向量数据库的核心能力
形式化地说:向量数据库 = 向量存储 + ANN 索引 + 混合查询。三件事缺一不可:
| 组件 | 职责 |
|---|---|
| 向量存储 | 高效存储 N×D 的浮点矩阵(N 条记录,每条 D 维) |
| ANN 索引 | 近似最近邻算法,把 O(N) 的全表扫描降到 O(log N) |
| 混合查询 | 支持向量距离计算 + 元数据过滤组合(如"找最相似的 5 条 + WHERE classification=‘public’”) |
ANN(Approximate Nearest Neighbor,近似最近邻)里的“Approximate”是关键:为了提升速度,接受不返回 100% 准确的最近邻,只返回“足够近”的 K 个结果。
这是一个典型的权衡:
精确最近邻(Exact NN): 必须 O(N) 复杂度,召回率 100%
近似最近邻(ANN): 可做到 O(log N),召回率 95%+对 RAG 场景而言,95% 的召回率通常足够用——本来 Embedding 召回本身就有上限,ANN 损失的那部分精度,在 RAG 整体的精度损失里通常不是主要矛盾。用精度换性能,是向量数据库的核心取舍逻辑。
除了三项基础能力,生产级向量数据库通常还会提供:
- 分布式横向扩展:支持十亿级向量分片到多节点
- 副本与备份:高可用 + 灾备能力
- 元数据索引:在 ANN 之外单独建立元数据索引(比如按文档 ID、标签过滤)
- 权限控制 / 多租户:不同用户、不同工作空间的数据隔离
- 快照与版本管理:全量重向量化时不影响线上服务
不同系统在这些附加能力上差异很大,后面的系统对比会展开讲。
主流 ANN 算法:Flat / IVF / HNSW
ANN 索引算法经历了几代演进,每个向量数据库内部都实现了其中一种或几种。理解这些算法的特点,再看 pgvector、Milvus、Qdrant 的文档就不会迷路。
Flat(暴力枚举,Brute Force)
最朴素的方案:每次查询,都和库里所有向量逐个计算距离,排序取 top-K。
- 召回率:100%(精确最近邻)
- 复杂度:O(N · D) —— N 条向量、D 维
- 适用场景:小于 10 万条向量的规模下,Flat 在 CPU 上也能在百毫秒内完成
- 实现特点:简单,无需训练和调参
关键洞察:对于小数据集,Flat 反而是最佳选择。不要在数据量很小时就过早引入 ANN——1 万条向量的场景下,ANN 建索引的时间可能比 Flat 全表扫描还长。
IVF(倒排文件索引,Inverted File Index)
核心思路:先用 K-means 把向量空间聚成 nlist 个簇,查询时只搜索和查询向量最近的几个簇。
1. 索引构建:用 K-means 计算出 nlist 个聚类中心
2. 把每个向量分配到最近的中心,形成 nlist 个倒排列表
3. 查询时:先和 nlist 个中心计算距离,选出最近的 nprobe 个簇
4. 在这 nprobe 个簇内做精确搜索- 召回率:90-98%(可调,nprobe 越大越准)
- 复杂度:O(√N) —— 当 nlist ≈ √N 时
- 适用场景:大于 100 万条向量、写入频繁
- 调参项:nlist(簇数量)、nprobe(查询时搜索的簇数量)
- 局限:需要训练数据(至少需要 30 × nlist 条向量做 K-means);冷启动不友好
常见变种:IVF-PQ(IVF + 乘积量化)——对每个向量做量化压缩,存储空间从 D×4 字节降到 nbits 字节,内存占用节省 16-32 倍,但召回率下降 2-5%。是十亿级向量库的常用方案。
HNSW(分层可导小世界,Hierarchical Navigable Small World)
核心思路:构建一张分层的图,高层稀疏,只连接远距离的邻居;低层密集,连接近距离邻居;查询时从顶层开始贪心导航,逐步定位到目标。
高层(稀疏,大跳跃)
●─────●
/ \ /
● ● ● <- 查询从这层开始,粗定位
/| |/
● ●───●─● <- 中层
/|/| |\|
●●●●─●─●●● <- 底层(密集,精确)- 召回率:95-99%(是当前 ANN 算法中召回率最高的之一)
- 复杂度:O(log N)
- 适用场景:100 万-1 亿条向量、查询频繁、对召回敏感
- 调参项:M(每层连接数,典型值 16-48)、ef_construction(建索引时的贪心宽度)、ef_search(查询时的贪心宽度)
- 局限:建索引慢、内存占用高(每个向量需要存储 M 个邻居 ID 和元数据)
为什么 HNSW 会成为主流? 因为它在召回率、查询速度、工程复杂度之间达到了最佳平衡。pgvector、Qdrant、Milvus、Weaviate 都默认支持 HNSW。
其他算法(了解即可)
- LSH(Locality-Sensitive Hashing,局部敏感哈希):用哈希函数把相近向量映射到同一个桶。早期方案,如今基本被 HNSW 和 IVF 替代
- ScaNN(Google):Google 内部使用,基于优化的 K-means + PQ,在 Google Cloud Vertex AI 上可用
- Annoy(Spotify):基于随机投影树,实现简单,Spotify 用它做音乐推荐;新项目较少使用
- DiskANN(Microsoft):索引可落盘,内存压力小;适合十亿级别+内存受限的场景
算法对比表
| 算法 | 召回率 | 查询速度 | 索引内存占用 | 建索引时间 | 适合规模 |
|---|---|---|---|---|---|
| Flat | 100% | O(N) 慢 | 仅向量本身 | 即时 | < 10 万 |
| IVF | 90-98% | O(√N) 中 | 仅向量 + 聚类中心 | 中等 | 100 万-1 亿 |
| IVF-PQ | 88-95% | O(√N) 中 | 约 1/16 | 中等 | > 1 亿(内存受限时) |
| HNSW | 95-99% | O(log N) 快 | 向量 + 邻居 ID | 慢 | 100 万-1 亿(当前默认选项) |
| LSH | 80-92% | O(log N) 中 | 中等 | 快 | 历史方案,新项目少用 |
选型经验法则:
- 数据量 < 10 万 → Flat(简单可靠)
- 数据量 10 万-1 亿、追求召回率 → HNSW(2024 年起的默认选择)
- 数据量 1 亿+、内存受限 → IVF-PQ 或 DiskANN(工业级方案)
主流向量数据库系统对比
理解了算法,再来看市面上的产品。截至 2026 年,主流向量数据库大致分为三类:
现有数据库的扩展
适合“已经有成熟数据库、不想额外维护一套新系统”的团队。
| 系统 | 形态 | 默认 ANN 算法 | 适合规模 | 主要优势 |
|---|---|---|---|---|
| pgvector | PostgreSQL 扩展 | HNSW / IVF | < 1000 万 | 可与业务表 JOIN、事务一致性、无额外运维成本 |
| Elasticsearch 8+ | ES 集群 + dense_vector | HNSW | < 1 亿 | 全文检索+向量混合检索、日志生态成熟 |
| Redis Stack(RediSearch) | Redis 模块 | HNSW / FLAT | < 5000 万 | 内存级速度、实时索引 |
专门的向量数据库
适合“向量检索是核心场景、需要专门优化”的团队。
| 系统 | 开发语言 | 默认 ANN 算法 | 适合规模 | 主要优势 |
|---|---|---|---|---|
| Milvus | Go/C++ | HNSW / IVF / DiskANN | 十亿级 | 工业级、云原生、字节出品 |
| Qdrant | Rust | HNSW | 1-10 亿 | 性能极佳、内置 RBAC、写入性能强 |
| Weaviate | Go | HNSW | 1-10 亿 | GraphQL 接口、内置重排、模块化设计 |
| Vespa | Java/C++ | HNSW + 多种 | 十亿级 | Yahoo 出品、大规模搜索+ML 一体化 |
| Chroma | Python | HNSW(hnswlib) | < 1000 万 | Python 原生、开发友好 |
| Vald | Go | HNSW(NGT) | 十亿级 | K8s 原生 |
SaaS 向量服务
适合“不想运维、按量付费”的团队。
| 系统 | 主要优势 |
|---|---|
| Pinecone | 最早商业化向量库,Serverless 模式无运维 |
| Weaviate Cloud | 自托管版的 SaaS 形态 |
| Qdrant Cloud | 自托管版的 SaaS 形态 |
| Aliyun DashVector | 阿里云原生,与阿里生态打通 |
| Tencent Cloud VectorDB | 腾讯云 |
关键对比维度:
| 维度 | pgvector | Milvus | Qdrant | Weaviate | Chroma | Pinecone |
|---|---|---|---|---|---|---|
| 运维成本 | 复用现有 PG | 集群运维 | 单二进制 | Helm Chart | 嵌入式 | 零运维(SaaS) |
| 规模上限 | 1000 万 | 百亿 | 10 亿 | 10 亿 | 千万 | 十亿(分片) |
| 典型延迟 | 10-50 ms | 5-20 ms | 5-15 ms | 10-30 ms | 5-20 ms | 50-200 ms(SaaS 网络) |
| 写入吞吐 | 中 | 高 | 极高 | 中 | 中 | 中 |
| 混合查询(元数据 filter) | SQL JOIN | 强 | 强 | 强 | 一般 | 强 |
| 多租户能力 | schema 隔离 | collection | collection | tenant | collection | namespace |
| 成本 | 服务器成本 | 服务器成本 | 服务器成本 | 服务器成本 | 服务器成本 | 按量计费,成本较高 |
pgvector 工程实战
对绝大多数团队来说,最优解不是单独搭一套向量数据库,而是给已经在用的 PostgreSQL 装上 pgvector 扩展。原因很实在:
- 对 1000 万条以内向量,它又快又省心
- 能和业务表 JOIN(
SELECT chunk.* FROM chunks JOIN documents USING (doc_id) WHERE documents.workspace_id = $1) - 没有额外的运维负担(还是同一个 PostgreSQL)
- 免费获得事务一致性
只有当数据量达到 1000 万以上,或者向量是绝对核心场景,才值得上专门向量库。常见路径是 pgvector 起步 → 规模或性能不满足后切 Qdrant / Milvus,而不是一开始就上 Milvus。
建表与索引(SQL)
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE kb_chunks (
id BIGSERIAL PRIMARY KEY,
doc_id TEXT NOT NULL,
content TEXT NOT NULL,
embedding vector(1024) -- 维度必须与 Embedder.Dim() 一致
);
-- 二选一的近似索引(下面解释怎么选):
CREATE INDEX ON kb_chunks USING hnsw (embedding vector_cosine_ops);
-- 或: CREATE INDEX ON kb_chunks USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);pgvector 的索引算法选择:
| hnsw | ivfflat | |
|---|---|---|
| 召回率 | 95-99%(高) | 90-97% |
| 查询速度 | 快(O(log N)) | 中(O(√N)) |
| 建索引时间 | 慢 | 快 |
| 内存占用 | 高 | 低 |
| 是否需要训练数据 | 否 | 是(至少 30 × lists) |
| 推荐场景 | 常用默认选项,数据相对稳定 | 频繁全量重建、内存受限 |
默认选 hnsw 就对了,除非内存严重受限或要频繁全量重建索引,否则它的召回和查询速度都更优。
Go 侧接入实现
Go 侧用 pgx 接入。pgvector 的向量在 SQL 里是 '[0.1,0.2,...]' 字面量格式,所以要把 []float32 格式化成字符串:
package rag
import (
"context"
"fmt"
"strings"
"github.com/jackc/pgx/v5/pgxpool"
)
type Document struct {
ID string
DocID string
Content string
Score float32 // 检索时回填
}
type PgVectorStore struct {
pool *pgxpool.Pool
}
// vecLiteral 把向量转成 pgvector 认识的字面量字符串 "[a,b,c]"。
func vecLiteral(v []float32) string {
parts := make([]string, len(v))
for i, x := range v {
parts[i] = fmt.Sprintf("%g", x)
}
return "[" + strings.Join(parts, ",") + "]"
}
func (s *PgVectorStore) Add(ctx context.Context, docID string, chunks []string, embs [][]float32) error {
batch := make([][]any, len(chunks))
for i := range chunks {
batch[i] = []any{docID, chunks[i], vecLiteral(embs[i])}
}
for _, row := range batch {
_, err := s.pool.Exec(ctx,
`INSERT INTO kb_chunks (doc_id, content, embedding) VALUES ($1, $2, $3)`,
row...)
if err != nil {
return err
}
}
return nil
}
// Search 用余弦距离检索最相似的 k 个片段。<=> 是 pgvector 的余弦距离算子。
func (s *PgVectorStore) Search(ctx context.Context, queryEmb []float32, k int) ([]Document, error) {
rows, err := s.pool.Query(ctx,
`SELECT id, doc_id, content, 1 - (embedding <=> $1) AS score
FROM kb_chunks
ORDER BY embedding <=> $1
LIMIT $2`,
vecLiteral(queryEmb), k)
if err != nil {
return nil, err
}
defer rows.Close()
var docs []Document
for rows.Next() {
var d Document
if err := rows.Scan(&d.ID, &d.DocID, &d.Content, &d.Score); err != nil {
return nil, err
}
docs = append(docs, d)
}
return docs, rows.Err()
}<=> 代表余弦距离(值越小越相近),所以 ORDER BY embedding <=> $1 升序就是"最相似的在前";1 - 距离 转成相似度分数,更符合阅读习惯。生产环境可以用 github.com/pgvector/pgvector-go 库让向量类型映射更优雅,但理解“格式化成字面量 + 距离算子排序”这套逻辑,就抓住了 pgvector 的本质。向量数据库选型
讲完理论和系统,落到实操:面对一个新项目,该怎么选向量数据库?可以用下面这棵决策树来判断:
要做向量检索
│
├─ 数据量 < 100K?
│ │是 → Flat 也行(任意系统)。最简单方案:
│ pgvector 不建索引、用 SeqScan,几十毫秒搞定
│
├─ 数据量 < 1000 万 + 已有 Postgres?
│ │是 → 优先考虑 pgvector
│ 理由:无新运维 + 与业务表 JOIN + 事务一致
│
├─ 数据量 1000 万 - 10 亿 + 向量是核心场景?
│ │
│ ├─ 想要"自托管开源 + 高性能"?
│ │ ├─ 写多读多/RBAC → Qdrant
│ │ ├─ 工业级生态/字节系 → Milvus
│ │ ├─ 内置 reranker/GraphQL → Weaviate
│ │ └─ 已有 ES 集群 → Elasticsearch
│ │
│ └─ 想要"SaaS 零运维"?
│ └─ Pinecone / Weaviate Cloud / Qdrant Cloud
│
├─ 数据量 10 亿+?
│ │是 → Milvus / Vespa / Vald(工业级专门方案)
│ 或:专项 IVF-PQ / DiskANN 算法,接受召回略降换内存省
│
└─ Python 原生开发 / 快速 prototype?
│是 → Chroma(开发体验最好,但生产规模有限)几个反复出现的核心判断标准:
- 数据量是第一判断标准 —— 10K / 1M / 100M / 10B 不同数量级有完全不同的最优解
- 已有技术栈是第二判断标准 —— 已经在用 PostgreSQL,优先 pgvector;已经在用 ES,优先 ES 8+
- 运维能力是第三判断标准 —— 团队没人想维护新组件,SaaS 优于自托管开源
- 延迟 / 召回要求在前三项都满足时再做细化考量
7.6 混合检索与 rerank
这一节是整章里对效果提升最明显的部分。只用向量检索有个天生的短板:它擅长找“语义相近”的内容,但遇到关键词精确匹配的场景——比如用户查具体的产品型号、错误码、专有名词,反而可能因为语义泛化,不如关键词匹配来得准确。
目前业界通用的生产基线方案是:混合检索 + 重排。
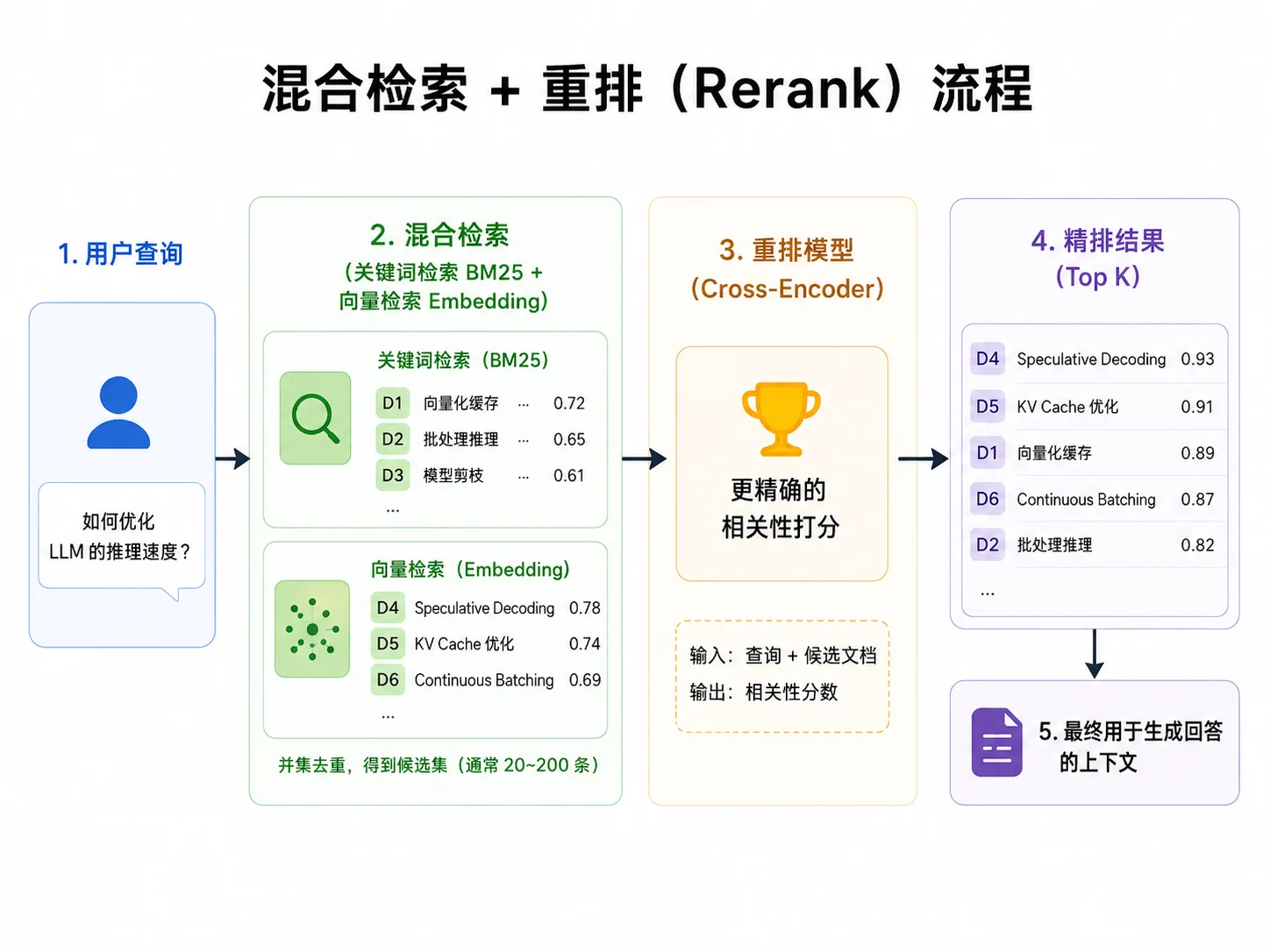
第一支柱:混合检索
混合检索(Hybrid Search) = 向量检索(语义) + BM25 关键词检索(精确匹配),两路结果用 RRF(Reciprocal Rank Fusion,倒数排名融合)合并。
RRF 不关心各路的原始分数(不同检索器的分数量级不可比),只看排名:一个文档在某一路里排得越靠前,贡献的分数就越高。它简单、稳健、几乎不需要调参,是融合多路检索结果的经典方法。
package rag
import "sort"
// RRF 用倒数排名融合多路检索结果。每路是一个按相关度降序排列的文档 ID 列表。
// k 是平滑常数,经验值 60。返回融合后按总分降序的 ID。
func RRF(rankings [][]string, k int) []string {
score := make(map[string]float64)
for _, ranking := range rankings {
for rank, id := range ranking {
score[id] += 1.0 / float64(k+rank+1) // 排名越靠前(rank 越小),加分越多
}
}
ids := make([]string, 0, len(score))
for id := range score {
ids = append(ids, id)
}
sort.Slice(ids, func(i, j int) bool { return score[ids[i]] > score[ids[j]] })
return ids
}BM25 那一路,可以直接用 PostgreSQL 自带的全文检索(tsvector/ts_rank),不需要额外组件。这又是“已经在用 PostgreSQL”的额外红利。两路各取 top-N,交给 RRF 融合即可。
第二支柱:重排(Rerank)
混合检索给出的是一批“粗筛”后的候选(比如 top-50),但它们和问题的真实相关度还可以做更精细的排序。重排使用交叉编码器(cross-encoder)模型,把「问题 + 每个候选片段」成对输入打分,得到精准的相关度排序,再取最高的几个(比如 top-5)送入大模型。
它比 Embedding 相似度准确得多,但代价是速度慢、成本高,所以只对粗筛后的少量候选做处理。
整条检索管线就是:混合检索粗筛 top-50 → 重排精排 → 取 top-5 进入上下文。
使用 Go 语言做接口封装:
package rag
import "context"
// Reranker:用交叉编码器对候选重新打分。Voyage rerank-2.5 是常用实现。
type Reranker interface {
Rerank(ctx context.Context, query string, docs []Document, topN int) ([]Document, error)
}
// Retriever 把"混合检索 + rerank"封装成一次 Retrieve 调用。
type Retriever struct {
Store *PgVectorStore
Embedder Embedder
Reranker Reranker
// keywordSearch 是 BM25/全文检索那一路,返回按相关度排序的文档。
keywordSearch func(ctx context.Context, query string, k int) ([]Document, error)
}
func (r *Retriever) Retrieve(ctx context.Context, query string, topN int) ([]Document, error) {
// 1) 向量检索 top-50
qemb, err := r.Embedder.Embed(ctx, []string{query})
if err != nil {
return nil, err
}
vecHits, err := r.Store.Search(ctx, qemb[0], 50)
if err != nil {
return nil, err
}
// 2) 关键词检索 top-50
kwHits, err := r.keywordSearch(ctx, query, 50)
if err != nil {
return nil, err
}
// 3) RRF 融合两路排名
byID := make(map[string]Document)
var vecRank, kwRank []string
for _, d := range vecHits {
vecRank = append(vecRank, d.ID)
byID[d.ID] = d
}
for _, d := range kwHits {
kwRank = append(kwRank, d.ID)
byID[d.ID] = d
}
fusedIDs := RRF([][]string{vecRank, kwRank}, 60)
// 4) 取融合后的前若干个候选,交给 rerank 精排
const candidateN = 50
candidates := make([]Document, 0, candidateN)
for _, id := range fusedIDs {
if len(candidates) >= candidateN {
break
}
candidates = append(candidates, byID[id])
}
if r.Reranker == nil {
if len(candidates) > topN {
candidates = candidates[:topN]
}
return candidates, nil // 没配 rerank 就直接返回融合结果
}
return r.Reranker.Rerank(ctx, query, candidates, topN)
}7.7 HyDE:假设性文档嵌入
接下来分享一个轻量但通常效果不错的技巧:HyDE(Hypothetical Document Embeddings,假设性文档嵌入)。
它针对的是一种常见的错配:用户的“提问”和知识库的“答案”在文字风格上差异很大。用户可能问“这个超时咋配啊”,而文档里写的是“超时时间通过 timeout 参数设置,单位为秒,默认值为 30……”。直接拿用户问题去做向量检索,可能匹配不到最相关的片段。
HyDE 的巧思在于:先让大模型根据问题,生成一段假设性的答案,再拿这段假设答案(而不是原问题)去做检索。因为假设答案的风格和用词更接近真实文档,检索命中率反而更高——哪怕假设答案的内容是错的也没关系,我们只用它的向量,最终回答依然基于检索到的真实文档。
// HyDE:先生成假设答案,再用它检索。p 是 M02 的对话 Provider。
func (r *Retriever) RetrieveHyDE(ctx context.Context, p llm.Provider, model, query string, topN int) ([]Document, error) {
system := "针对用户问题,写一段简短的、像是来自企业文档的假设性回答(两三句即可)。" +
"不必保证正确,只需在风格和用词上贴近正式文档。"
resp, err := p.Chat(ctx, llm.ChatRequest{
Model: model,
Messages: []llm.Message{
{Role: llm.RoleSystem, Content: system},
{Role: llm.RoleUser, Content: query},
},
})
if err != nil || strings.TrimSpace(resp.Content) == "" {
return r.Retrieve(ctx, query, topN) // 生成失败就退回普通检索
}
return r.Retrieve(ctx, resp.Content, topN) // 用假设答案去检索
}7.8 Agentic RAG:让检索更智能
到这里,我们已经能搭出一个可用的基础 RAG了:用户提问 → 检索一次 → 把结果放进上下文 → 生成回答。但固定流程的基础 RAG 有不少局限:
- 它每次都检索,不管该不该检索。用户说“谢谢”,它也去知识库查一遍,浪费资源还可能引入噪声。
- 它只检索一次,且只用原始问题检索。遇到需要多跳的问题(比如“我们线上跑的那个版本,有没有已知的安全补丁”)——得先查到当前部署的版本号,再查该版本的补丁公告,一次检索根本不够。
- 它不判断检索结果够不够。返回的片段如果不相关,它也会按固定流程进入生成步骤。
Agentic RAG 就是把这三个“死板”操作变成“自主”操作变成:让 Agent 自己决定何时检索、用什么查询检索、检索回来的结果够不够、要不要换个查询再检索一次。
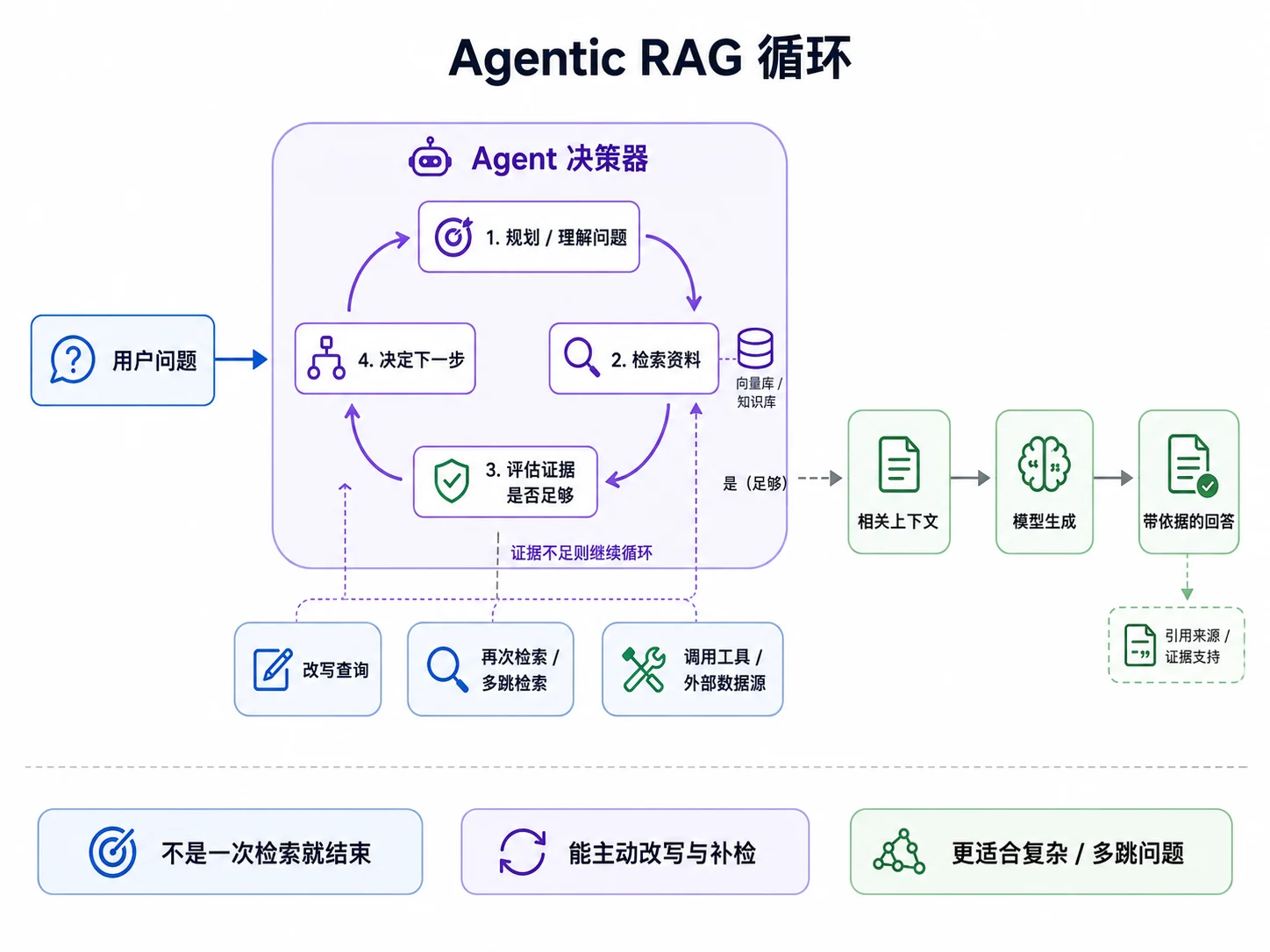
而实现 Agentic RAG,我们几乎不需要新的基础设施——把“检索”做成一个工具,注册给 Agent,它就具备了自主检索的能力。这正是前面几章能力组合后的自然结果:
type kbSearchArgs struct {
Query string `json:"query" desc:"要在知识库中检索的查询。请提炼出精准的检索关键词或问题。"`
}
// SearchTool 把检索管线包装成一个 Agent 工具。
func SearchTool(r *Retriever) tool.Tool {
return tool.NewTypedTool(
"search_knowledge_base",
"在企业知识库中检索资料。当你需要依据公司政策、产品文档或历史资料回答时调用;"+
"可以用不同的查询多次调用以获取更全面的信息。",
func(ctx context.Context, a kbSearchArgs) (string, error) {
docs, err := r.Retrieve(ctx, a.Query, 5)
if err != nil {
return "", err
}
if len(docs) == 0 {
return "知识库中未找到相关资料。", nil
}
var sb strings.Builder
for i, d := range docs {
// 带上来源标注,便于模型在回答里引用、也便于事后审计
fmt.Fprintf(&sb, "[来源 %d | doc=%s | 相关度=%.2f]\n%s\n\n",
i+1, d.DocID, d.Score, d.Content)
}
return sb.String(), nil
})
}把这个工具注册进 Agent,基础的 Agent 循环就具备了 Agentic RAG 能力:
- 用户说“谢谢”时,模型判断不需要检索,就不会调用这个工具(解决“该不该检索”的问题);
- 遇到多跳问题,模型会先调用一次工具拿到当前版本号,再用知识库检索查该版本的变更说明(解决“检索什么”的问题——它自己提炼查询词);
- 如果第一次检索回来的片段不相关,模型在下一轮可以换个查询再调用一次(解决“够不够”的问题——这正是反思思想的体现)。
reg := tool.NewRegistry(
SearchTool(retriever), // 知识库检索
lookupVersionTool, // 查询当前版本号(M06 的工具)
)
ag := agent.New(provider, model, reg, agent.WithSystemPrompt(
"你是文档助手。回答必须依据 search_knowledge_base 检索到的资料,"+
"并在回答中标注来源;资料不足时如实说明,不要编造。"))
ag.Run(ctx, userQuestion)7.9 GraphRAG 与 LazyGraphRAG
我们目前做的向量 RAG,有一类问题天生不擅长:全局性、关系型、需要多跳推理的问题。比如“把所有客户投诉里反复出现的三个主要问题总结一下”——这需要纵览整个语料、归纳主题,而向量检索只会返回“和这句话最像的几个片段”,通常答不好。
GraphRAG 换了个思路:先从文档里抽取出实体和它们之间的关系,构建成知识图谱,检索时在图上做遍历(顺着关系跳转)。这让它擅长回答“A 和 B 是什么关系”、“跨多个文档的实体如何关联”、“整个语料的主题结构”这类问题。
GraphRAG 的代价是索引成本极高——需要用大模型把整个语料的实体和关系都抽取一遍。微软后续提出的 LazyGraphRAG 推迟了全量抽取这步昂贵的操作,根据微软官方公布的数据,可将索引成本大幅降低(约为传统 GraphRAG 的 0.1%,具体数值随场景变化),让图方法在大语料上也具备了实用性。
选型建议:什么时候用?
给一个务实的判断标准:
| 问题类型 | 推荐方案 |
|---|---|
| 具体事实查找(比如“默认超时是几秒”) | 向量 RAG(本章主线方案) |
| 多跳关系查询(比如“A 公司的子公司有哪些客户”) | GraphRAG |
| 全局归纳总结(比如“所有反馈里的共性问题”) | GraphRAG |
| 绝大多数事实型问答 | 向量 RAG 足矣 |
7.10 长上下文 vs RAG
最后聊一个绕不开的话题:现在大模型动不动就上百万 token 的上下文,那能不能直接把整个知识库放进上下文,不用做 RAG 了?
这本质上不是技术问题,是经济学和效果的权衡。把全部内容放进上下文(长上下文方案)有几个明显的代价:
- 成本:上下文里的每个 token,每一次调用都要计费。如果知识库有 50 万 token,用户每问一句都带上,问 100 句就是 5000 万 token 的输入费用。而 RAG 每次只取最相关的几千 token。
- 效果(“中间遗忘”问题):上下文极长时,模型对中间部分的信息利用率会下降(也就是常说的 lost in the middle),不是资料放得越多效果越好。
- 延迟:处理超长上下文的速度更慢。
但天平的另一侧也有变量:Prompt Caching 能把“不变的长上下文”缓存起来,大幅摊薄重复计费的成本——这让长上下文方案在某些场景重新变得划算。
具体如何选择,可以用下面的决策框架来判断:
| 情况 | 倾向 |
|---|---|
| 语料小且稳定、能放进窗口、配 Prompt Caching | 长上下文可能更简单划算 |
| 语料大 / 频繁更新 | RAG |
| 需要精确引用来源(合规 / 可追溯要求) | RAG(检索天然带来源) |
| 单次问答、一次性资料 | 直接放进上下文 |
配套练习:mini-kb 知识库问答
把本章的内容串联起来,实现一个可用的知识库问答工具。
需求:索引本地文档目录(.md/.txt 格式),支持提问并给出带来源标注的回答;检索采用“混合检索 + 重排”;最终包装成 Agentic RAG 工具接入 Agent 系统。用 docker-compose 启动 PostgreSQL+pgvector。
验收要点(覆盖本章核心内容):
- 索引管线:遍历目录 →
RecursiveChunker切分 →Embedder向量化 →PgVectorStore.Add入库; - 检索管线:
Retriever实现向量 + Postgres 全文检索两路,用RRF融合,再 rerank 取 top-5; - 用
SearchTool把检索包成工具,注册进 Agent,验证它会"按需检索"、“多查几次”; - 回答必须带来源标注,检索不到时如实说明“未找到”,不编造内容
- 对比实验:同一个问题,分别跑“纯向量检索”和“混合+重排”,直观感受质量差异
- 给
RRF、RecursiveChunker.Split(含超长无分隔符的硬切用例)写表驱动测试。
提供以下索引入口代码骨架:
func indexDir(ctx context.Context, dir string, ch *rag.RecursiveChunker, emb rag.Embedder, store *rag.PgVectorStore) error {
return filepath.WalkDir(dir, func(path string, d fs.DirEntry, err error) error {
if err != nil || d.IsDir() {
return err
}
if ext := filepath.Ext(path); ext != ".md" && ext != ".txt" {
return nil
}
data, err := os.ReadFile(path)
if err != nil {
return err
}
chunks := ch.Split(string(data))
embs, err := emb.Embed(ctx, chunks) // 批量向量化
if err != nil {
return err
}
return store.Add(ctx, path, chunks, embs)
})
}本章小结
| 核心知识点 | 在真实系统中的作用 |
|---|---|
| Embedding 三种训练范式 | 理解向量表征语义的底层逻辑 |
| RecursiveChunker 递归切分 | 知识库文档切分,是检索效果的地基 |
| Embedding + pgvector | 文本向量化与存储检索 |
| 混合检索 + RRF + 重排 | 业界通用的生产级检索基线,显著提升效果 |
| HyDE 假设性文档嵌入 | 解决问题与文档风格错配的补救技巧 |
| Agentic RAG(检索即工具) | 能自主决定检索时机与查询的知识库内核 |
| GraphRAG / 长上下文经济学 | 理解不同方案的适用场景,学会做技术选型 |
思考题
- 现在一个 Agent 同时握着“检索”“查数据”“做计算”等好几个工具,处理复杂任务时单 Agent 忙不过来、上下文也越堆越乱。如果把“检索专家”“数据专家”拆成各自独立的 Agent 协作,会不会更清晰?代价是什么?
- Agentic RAG 里,Agent 可能检索很多轮,对话消息里塞满了大段检索结果,迅速逼近上下文上限。你会怎么压缩这些已经用过的检索结果?
- 我们的检索质量目前靠主观感受判断。如何量化一个 RAG 系统的好坏——比如召回率、答案是否忠于检索内容(不幻觉)、是否答非所问?