M05 记忆系统与 RAG 实现
前面几章已经完成了 Agent 的基础工程能力、LLM 调用、多 Provider 接入、Agent 运行循环和工具系统。到这里,一个 Agent 已经可以接收用户问题、调用模型、选择工具,并把工具结果反馈给模型继续推理。
但如果 Agent 每次对话都从零开始,它仍然很难进入真实业务场景。用户的偏好、过去任务的执行过程、企业内部文档、历史问答记录,都不应该只依赖一次上下文窗口临时保存。
本章要解决的问题是:如何用 Go 为 Agent 设计一套可扩展的记忆系统,并基于 Embedding、向量数据库和 RAG,让 Agent 能够检索企业知识库并生成带引用的回答。
学习目标
完成本章后,你应该能够:
- 理解短期记忆、长期记忆、情景记忆和语义记忆的区别
- 能够设计统一的
Memory接口和记忆数据结构 - 能够在 Go 中调用 Embedding 模型生成文本向量
- 理解余弦相似度和向量检索的基本原理
- 能够使用 PostgreSQL + pgvector 存储和检索向量数据
- 能够实现文档加载、切分、Embedding 和入库的处理流水线
- 理解 RAG 的检索、组装上下文、生成答案和引用溯源流程
- 了解 HyDE、重排序等 RAG 进阶优化手段
- 能够完成一个企业知识库问答 Agent 的最小可用版本
本章内容
- Agent 记忆系统的分层设计
- 统一记忆接口与会话记忆实现
- Embedding 模型接入与相似度计算
- pgvector 向量数据库集成
- 文档处理流水线与文本切分
- RAG 检索增强生成流程
- HyDE 与重排序
- 企业知识库问答 Agent 项目实践
一、为什么 Agent 需要记忆
对于普通聊天机器人来说,一次请求只要把用户问题发给模型,再把模型回答返回给用户就够了。
但 Agent 的使用场景通常更复杂:
- 用户希望它记住之前的对话内容
- 企业希望它能回答内部文档中的问题
- 系统希望它能复用过去任务的执行结果
- 多轮任务中,Agent 需要知道自己已经做过什么
- 同一个用户下次回来时,希望 Agent 能保留部分偏好和事实
如果没有记忆系统,这些能力都只能临时塞进 prompt。上下文窗口一旦超过限制,旧信息就会被截断;会话结束后,所有状态也会丢失。
所以在 Agent 系统中,记忆不是一个“附加功能”,而是一层基础能力。
从工程实现上看,记忆系统至少要解决三个问题:
- 哪些信息应该被记录
- 这些信息应该存在哪里
- 运行时应该如何检索和使用这些信息
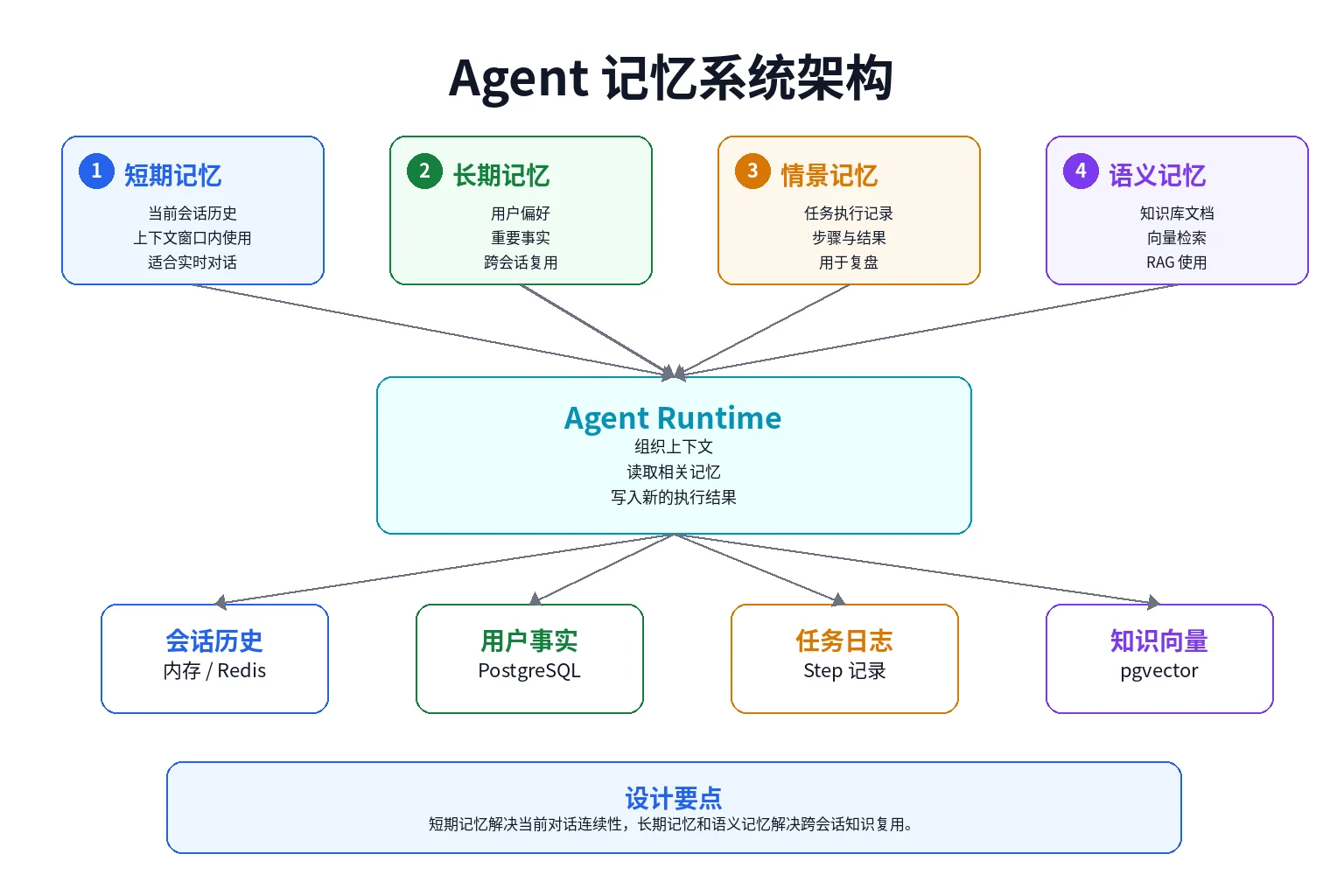
二、四类常见记忆
在课程中,我们把 Agent 记忆拆成四类:短期记忆、长期记忆、情景记忆和语义记忆。
1. 短期记忆
短期记忆通常指当前会话的上下文,例如最近几轮用户输入和模型回答。
这类信息一般保存在内存中,也可以放到 Redis 这类临时存储里。它的主要作用是让模型知道当前对话前面发生了什么。
例如:
User: 我想做一个企业知识库系统
Assistant: 你需要先准备文档摄取和检索模块
User: 那数据库选什么?最后一句“数据库选什么”依赖前文上下文。如果没有短期记忆,模型很难知道用户说的是知识库系统里的数据库。
2. 长期记忆
长期记忆用于保存跨会话仍然有价值的信息。
比如:
- 用户常用的技术栈
- 用户偏好的代码风格
- 某个项目的长期背景
- 已确认过的业务规则
这类信息不能无限制保存,也不能随便写入。真实系统中通常需要明确的写入策略、过期策略和用户可控的删除机制。
3. 情景记忆
情景记忆保存的是过去任务的执行过程。
例如一个数据分析 Agent 执行过这样的任务:
读取 sales.csv
分析各季度销售额
生成折线图
输出结论每一步的 Thought、Action、Observation、Error 和 Duration 都可以成为情景记忆的一部分。后续排查问题、做任务复盘、生成执行报告时都会用到。
4. 语义记忆
语义记忆主要指知识库内容,例如文档、网页、FAQ、产品手册、代码说明等。
这类信息通常不会直接塞进 prompt,而是先做向量化存储。用户提问时,系统再根据问题检索相关片段,把检索结果放到 prompt 中,让模型基于这些上下文回答问题。
这就是 RAG 的基础。
三、统一记忆接口
在工程实现中,不同类型的记忆可以有不同存储方式,但上层 Agent 不应该直接依赖具体实现。
可以先定义一个统一接口:
type Memory interface {
Store(ctx context.Context, entry MemoryEntry) error
Retrieve(ctx context.Context, query string, limit int) ([]MemoryEntry, error)
Clear(ctx context.Context) error
}
type MemoryEntry struct {
ID string
Content string
Metadata map[string]any
Embedding []float32
CreatedAt time.Time
SessionID string
}这个接口只保留三个动作:写入、检索和清空。
短期会话记忆可以实现这个接口,长期记忆和向量数据库也可以实现这个接口。这样 Agent 运行时只依赖抽象,而不关心底层是内存、PostgreSQL、Redis 还是 pgvector。
一个简单的会话记忆可以这样写:
type ConversationMemory struct {
messages []Message
maxLen int
mu sync.RWMutex
}
func (m *ConversationMemory) Add(msg Message) {
m.mu.Lock()
defer m.mu.Unlock()
m.messages = append(m.messages, msg)
if len(m.messages) > m.maxLen {
m.messages = m.messages[len(m.messages)-m.maxLen:]
}
}
func (m *ConversationMemory) Messages() []Message {
m.mu.RLock()
defer m.mu.RUnlock()
result := make([]Message, len(m.messages))
copy(result, m.messages)
return result
}这里有两个细节值得注意。
第一,读写需要加锁。会话记忆可能被多个 goroutine 同时访问,不能直接暴露内部 slice。
第二,返回消息时要复制一份,避免调用方修改内部状态。
四、Embedding:把文本变成向量
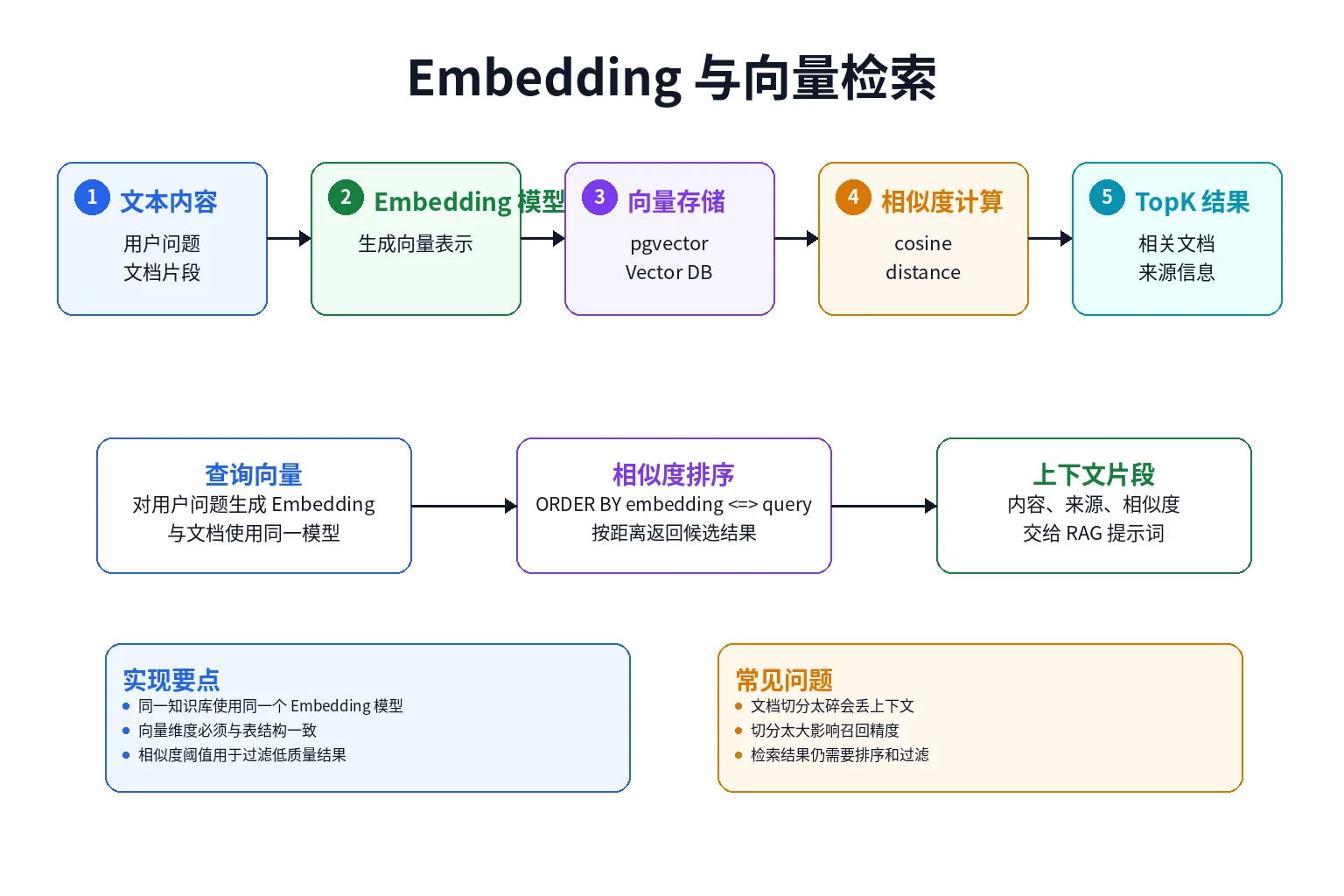
RAG 的基础是向量检索,而向量检索的前提是把文本变成向量。
Embedding 模型的作用就是把一段文本映射成一个高维浮点数组。语义接近的文本,其向量距离通常也更近。
一个 Embedding 客户端可以这样设计:
type Embedder interface {
Embed(ctx context.Context, texts []string) ([][]float32, error)
}
type EmbeddingClient struct {
client *openai.Client
model string
}
func (c *EmbeddingClient) Embed(
ctx context.Context,
texts []string,
) ([][]float32, error) {
resp, err := c.client.CreateEmbeddings(ctx, openai.EmbeddingRequest{
Input: texts,
Model: openai.EmbeddingModel(c.model),
})
if err != nil {
return nil, err
}
result := make([][]float32, len(resp.Data))
for i, d := range resp.Data {
result[i] = make([]float32, len(d.Embedding))
for j, v := range d.Embedding {
result[i][j] = float32(v)
}
}
return result, nil
}真实项目里,Embedding 调用要特别注意几个问题:
- 批量调用,减少网络开销
- 缓存结果,避免重复计费
- 控制单批文本数量,避免超过服务限制
- 同一个知识库尽量使用同一个 Embedding 模型
- 表结构中的向量维度必须和模型输出维度一致
五、相似度计算
向量检索本质上是在找“离查询向量最近的文档向量”。
在课程里,我们先用余弦相似度理解这个过程:
func CosineSimilarity(a, b []float32) float32 {
var dot, normA, normB float32
for i := range a {
dot += a[i] * b[i]
normA += a[i] * a[i]
normB += b[i] * b[i]
}
if normA == 0 || normB == 0 {
return 0
}
return dot / (
float32(math.Sqrt(float64(normA))) *
float32(math.Sqrt(float64(normB)))
)
}这个函数适合教学和小规模测试。生产环境一般不会在 Go 代码里遍历所有向量,而是交给向量数据库完成排序。
六、使用 pgvector 存储向量
如果你的主数据库已经使用 PostgreSQL,那么 pgvector 是一个很适合课程项目的选择。
它的优点是:
- 可以和业务数据放在同一个 PostgreSQL 中
- 可以同时保存向量和元数据
- 可以使用 SQL 做过滤、排序和分页
- 部署复杂度低于单独维护一套向量数据库
一个基础文档表可以这样设计:
CREATE TABLE IF NOT EXISTS documents (
id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
content TEXT NOT NULL,
metadata JSONB,
embedding vector(1536),
created_at TIMESTAMPTZ DEFAULT NOW()
);
CREATE INDEX IF NOT EXISTS documents_embedding_idx
ON documents USING ivfflat (embedding vector_cosine_ops);写入文档时,需要同时保存原文、元数据和向量:
func (s *PGVectorStore) Upsert(
ctx context.Context,
entry MemoryEntry,
) error {
_, err := s.db.ExecContext(ctx, `
INSERT INTO documents (id, content, metadata, embedding)
VALUES ($1, $2, $3, $4)
ON CONFLICT (id)
DO UPDATE SET content = $2, metadata = $3, embedding = $4
`,
entry.ID,
entry.Content,
marshalJSON(entry.Metadata),
pgvector.NewVector(entry.Embedding),
)
return err
}检索时,根据查询向量做相似度排序:
func (s *PGVectorStore) Search(
ctx context.Context,
queryEmb []float32,
limit int,
) ([]MemoryEntry, error) {
rows, err := s.db.QueryContext(ctx, `
SELECT id, content, metadata,
1 - (embedding <=> $1) AS similarity
FROM documents
ORDER BY embedding <=> $1
LIMIT $2
`, pgvector.NewVector(queryEmb), limit)
if err != nil {
return nil, err
}
defer rows.Close()
// 扫描 rows 并组装 MemoryEntry
return scanMemoryEntries(rows)
}vector(1536) 必须和你实际使用的 Embedding 模型输出维度一致,否则写入时会失败。七、文档处理流水线
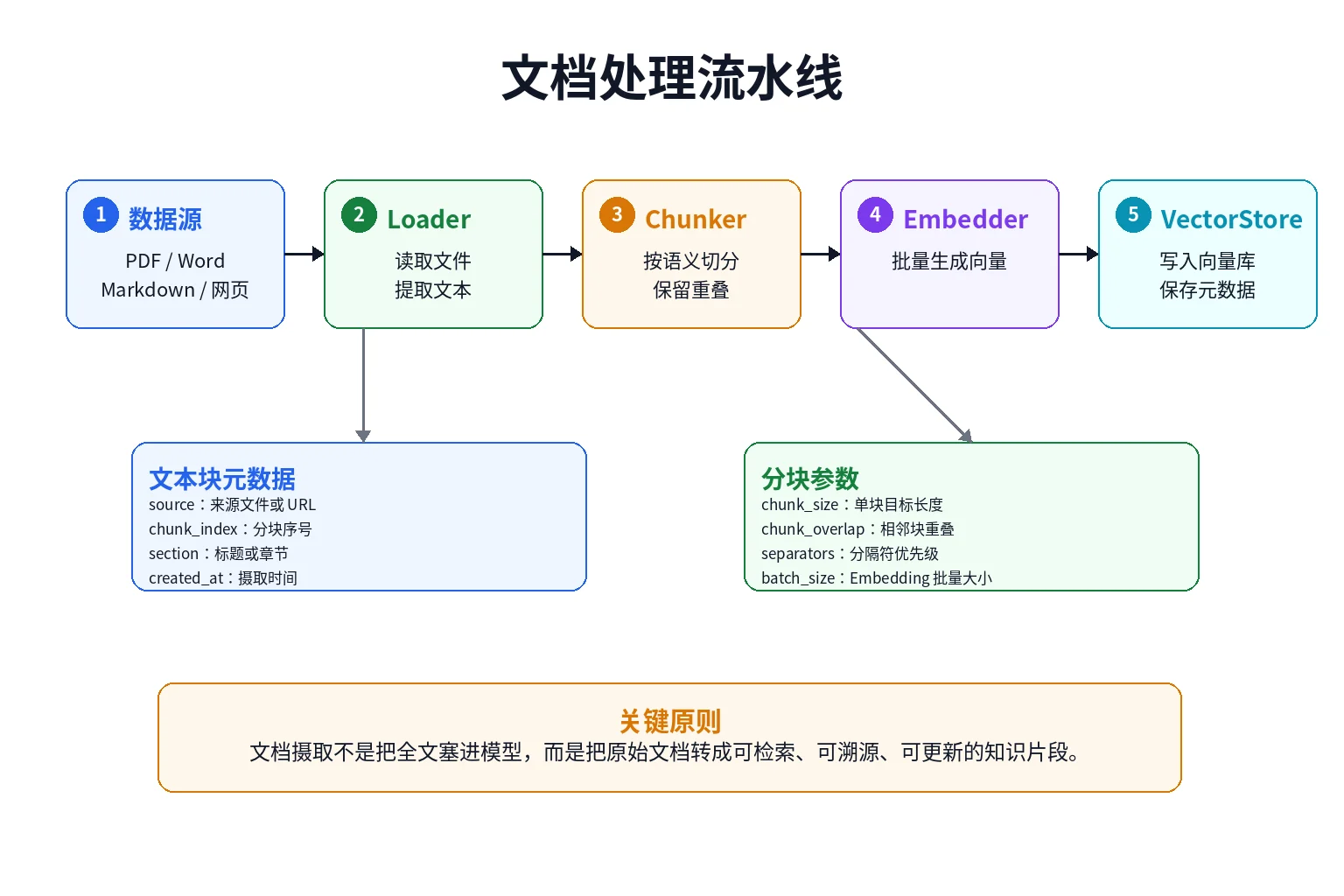
企业知识库通常不是直接处理一小段文本,而是处理大量文档。
文档从上传到可检索,一般要经过这几步:
- 加载文档
- 提取文本
- 清洗内容
- 切分文本块
- 生成 Embedding
- 写入向量数据库
可以把这条链路抽象成一个 DocumentPipeline:
type DocumentPipeline struct {
loader DocumentLoader
chunker TextChunker
embedder Embedder
store VectorStore
}
func (p *DocumentPipeline) Ingest(ctx context.Context, source string) error {
docs, err := p.loader.Load(ctx, source)
if err != nil {
return err
}
var chunks []TextChunk
for _, doc := range docs {
chunks = append(chunks, p.chunker.Split(doc)...)
}
texts := make([]string, len(chunks))
for i, chunk := range chunks {
texts[i] = chunk.Content
}
embeddings, err := p.embedder.Embed(ctx, texts)
if err != nil {
return err
}
for i, chunk := range chunks {
if err := p.store.Upsert(ctx, MemoryEntry{
Content: chunk.Content,
Embedding: embeddings[i],
Metadata: chunk.Metadata,
}); err != nil {
return err
}
}
return nil
}这个流水线的好处是职责清楚:Loader 只负责加载,Chunker 只负责切分,Embedder 只负责向量化,Store 只负责存储。
后续无论你要支持 PDF、Word、Markdown 还是网页爬取,都可以通过实现新的 Loader 接入。
文本切分
文本切分是 RAG 中很容易被低估的一步。
切得太大,检索时容易带入太多无关内容;切得太小,语义上下文又不完整。
一个常见做法是递归字符切分:
type RecursiveChunker struct {
ChunkSize int
ChunkOverlap int
Separators []string
}
func NewDefaultChunker() *RecursiveChunker {
return &RecursiveChunker{
ChunkSize: 1000,
ChunkOverlap: 200,
Separators: []string{
"\n\n",
"\n",
". ",
" ",
"",
},
}
}这段配置表达了一个基本思路:优先按段落切,再按行切,再按句子和空格切。如果都切不开,最后才按字符切。
八、RAG 的基本流程
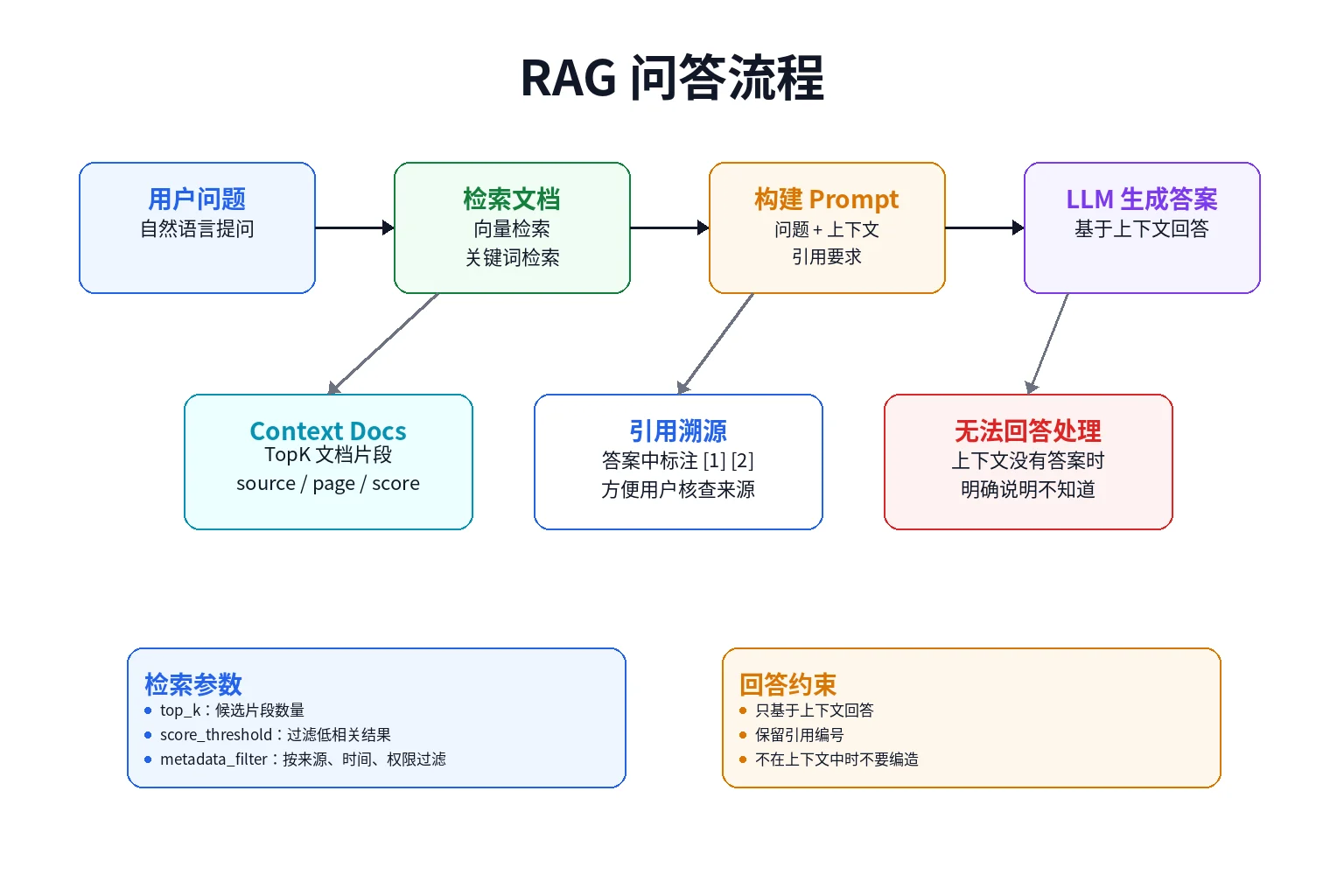
RAG 的全称是 Retrieval-Augmented Generation,即检索增强生成。
它的核心流程可以概括为:
- 用户提出问题
- 系统对问题生成查询向量
- 从向量数据库中检索相关文档
- 把相关文档作为上下文拼进 prompt
- 模型基于上下文生成答案
- 答案中保留引用来源
一个 RAG prompt 可以这样写:
const RAGPromptTemplate = `Based on the following context documents,
answer the user's question. If the answer is not in the context, say so.
Context:
{{range $i, $doc := .Docs}}
[{{add $i 1}}] {{$doc.Content}} (Source: {{$doc.Metadata.source}})
{{end}}
Question: {{.Question}}
Answer with citations like [1], [2] etc.:`这里有两个重点。
第一,要明确告诉模型只能根据上下文回答。如果上下文中没有答案,就应该说明找不到,而不是自由发挥。
第二,要让模型保留引用。这样用户可以回到原始文档核查答案来源。
九、RAG 进阶:HyDE 与重排序
基础 RAG 并不总是能取得理想效果。
有些用户问题很短,例如“报销规则是什么”;有些问题和文档里的表达方式不一致,例如用户说“差旅补贴”,文档里写的是“出差津贴”。这时候直接用用户问题检索,可能召回不到最相关的内容。
HyDE
HyDE 的思路是:先让模型基于问题生成一段“假设答案”,再用这段假设答案去做向量检索。
func (r *HyDERetriever) Retrieve(
ctx context.Context,
query string,
) ([]Document, error) {
hypothesis, err := r.llm.Complete(ctx, CompletionRequest{
Messages: []Message{{
Role: "user",
Content: "Write a short passage that answers: " + query,
}},
})
if err != nil {
return nil, err
}
emb, err := r.embedder.Embed(ctx, []string{hypothesis.Content})
if err != nil {
return nil, err
}
return r.store.Search(ctx, emb[0], r.topK)
}HyDE 适合提升召回,但它会增加一次模型调用成本,不适合所有问题都无脑启用。
重排序
向量检索通常先返回一批候选文档,例如 Top 20。重排序的作用是进一步判断这些候选文档和问题的匹配程度,再筛选出更适合放进上下文的结果。
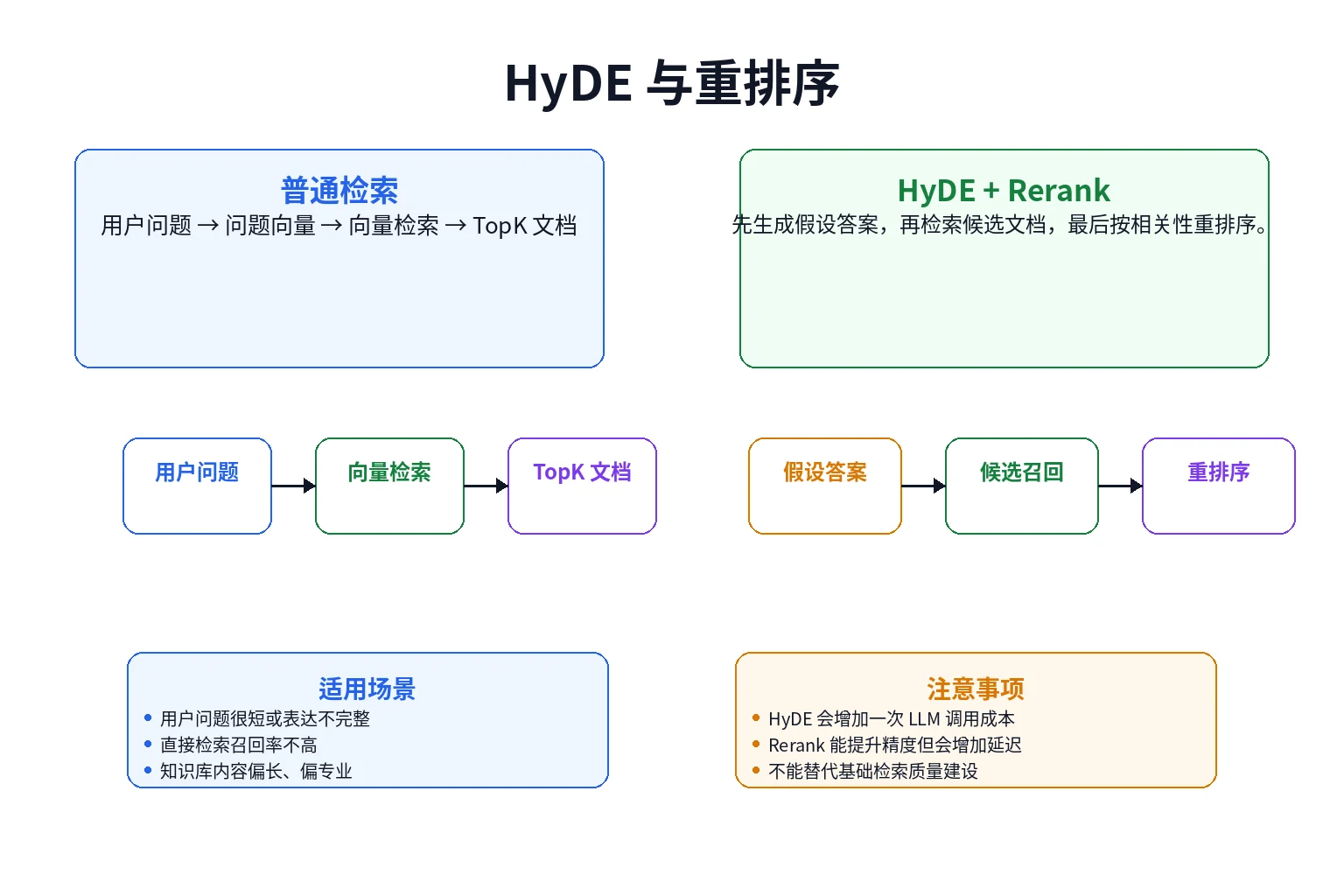
一个简单的重排序接口可以这样设计:
type Reranker interface {
Rerank(ctx context.Context, query string, docs []Document) ([]Document, error)
}真实项目中可以使用专门的 rerank 模型,也可以先用规则和轻量评分策略实现一个简单版本。
十、项目四:企业知识库问答 Agent
本章的综合项目是企业知识库问答 Agent。
它的目标不是做一个“能聊天”的机器人,而是做一个能够回答企业内部文档问题,并且保留引用来源的知识库问答系统。
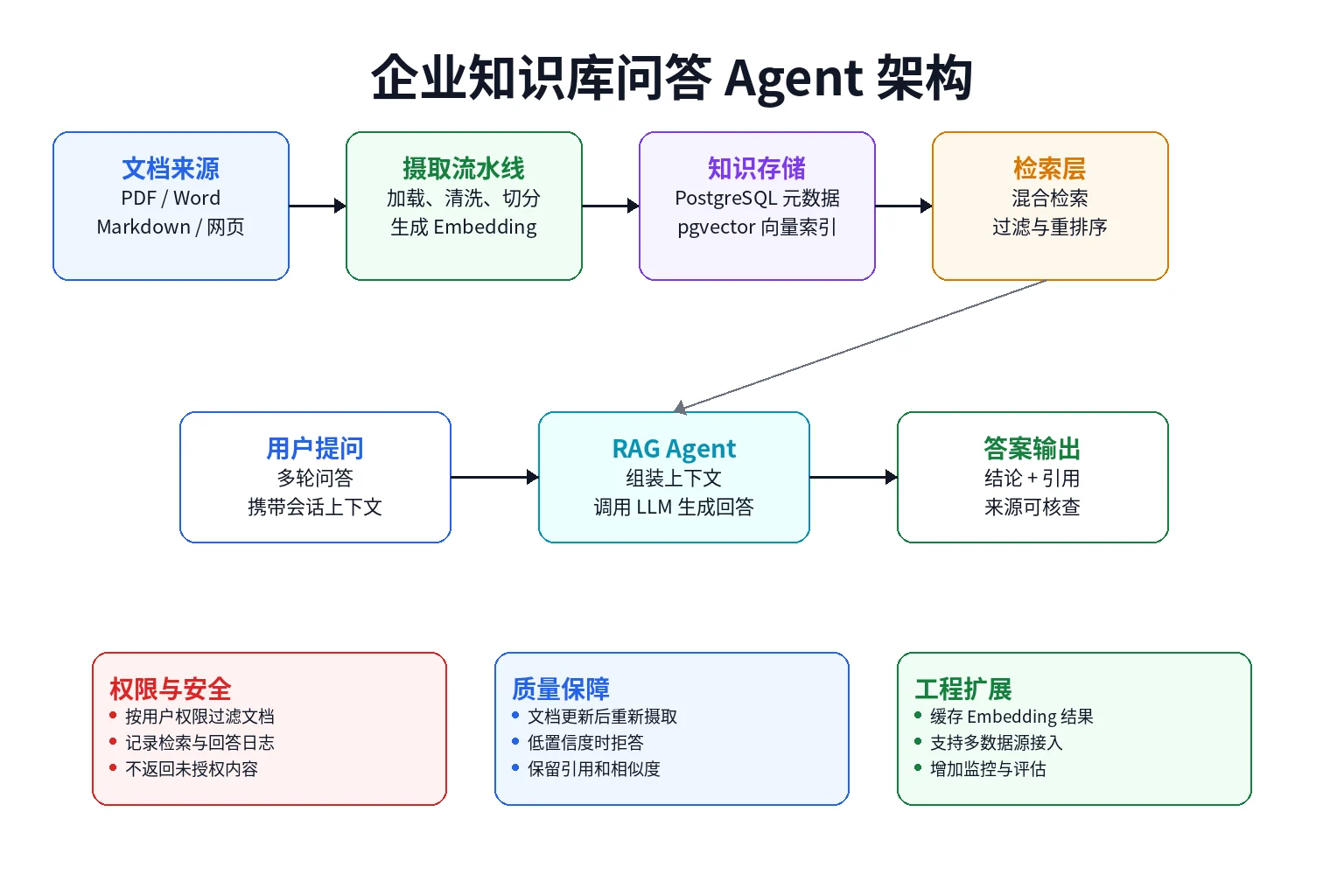
一个最小可用版本可以包含这几层:
- 摄取层:支持 Markdown、PDF、Word 或网页内容导入
- 存储层:PostgreSQL 保存元数据,pgvector 保存向量
- 检索层:根据问题检索相关文档片段
- 生成层:把检索结果组装为 RAG prompt
- 引用层:在答案中保留来源信息
项目的核心链路是:
上传文档 → 文本提取 → 分块 → Embedding → 向量入库
用户提问 → 检索文档 → 组装 Prompt → LLM 回答 → 返回引用建议优先完成一个最小版本:
- 支持上传 Markdown 文件
- 使用固定大小切分文本
- 调用 Embedding API 生成向量
- 使用 pgvector 存储和检索
- 用 RAG prompt 生成带引用的回答
等这条主链路跑通后,再扩展 PDF、Word、网页爬取、混合检索、重排序和权限控制。
十一、常见问题
1. RAG 能不能完全解决幻觉问题?
不能。
RAG 可以减少幻觉,但不能保证模型绝对不编造。你仍然需要在 prompt 中明确约束模型,并在系统层做引用校验、低置信度拒答和人工复核。
2. 文档切分应该按字符还是按 token?
课程中先用字符切分,便于理解和实现。真实系统中可以结合 token 计算、标题层级和语义边界做更精细的切分。
3. pgvector 是否足够生产使用?
对于中小规模知识库,pgvector 是非常实用的选择。它部署简单,和 PostgreSQL 集成紧密。等到数据规模、检索性能或多租户隔离需求变复杂,再考虑独立向量数据库也不迟。
4. 是否需要缓存 Embedding?
需要。
Embedding 调用有成本,且同一段文本重复生成向量没有意义。可以用文本内容的 hash 作为缓存 key,缓存 Embedding 结果。
十二、本章小结
本章围绕 Agent 的记忆系统和 RAG 实现,完成了从概念到工程落地的一条完整链路。
需要重点掌握的是:
- 记忆系统不是一个单一存储,而是由多种记忆类型组成
- 短期记忆负责当前对话,长期记忆负责跨会话信息
- 语义记忆通常通过 Embedding 和向量数据库实现
- 文档摄取要经过加载、切分、向量化和存储
- RAG 的关键是检索相关上下文,并让模型基于上下文回答
- 引用溯源和无法回答处理是知识库系统的基本要求
- HyDE 和重排序可以提升检索质量,但也会增加成本和延迟
学完这一章后,你已经具备了构建企业知识库问答 Agent 的基本能力。下一章会在此基础上继续扩展到多智能体系统,讨论多个 Agent 如何分工协作完成复杂任务。
课后练习
必做练习
- 实现一个
ConversationMemory,支持添加消息、读取最近 N 条消息和清空会话。 - 实现一个
Embedder接口,并使用任意 Embedding API 生成文本向量。 - 使用 PostgreSQL + pgvector 创建文档表,并完成文档写入和 TopK 检索。
- 实现一个最小 RAG 问答流程:输入问题,检索文档,组装 prompt,输出带引用的答案。
选做练习
- 为文档摄取流程增加 Embedding 缓存,避免重复调用 API。
- 实现一个 Markdown 文件 Loader,并保留标题层级作为 metadata。
- 实现一个简单的 Reranker,对候选文档按关键词命中和向量相似度加权排序。
- 为企业知识库问答 Agent 增加“上下文中找不到答案时拒答”的测试用例。
参考资料
- pgvector:
https://github.com/pgvector/pgvector - PostgreSQL:
https://www.postgresql.org/docs/ - OpenAI Embeddings API:
https://platform.openai.com/docs/guides/embeddings - Go database/sql:
https://pkg.go.dev/database/sql - HyDE: Hypothetical Document Embeddings for Zero-Shot Dense Retrieval