M05 Agent 设计模式
M04 手写了单个 Agent 循环:模型决定下一步,代码执行工具,把观察结果再交回模型。这个循环是 Agent 的基础核心。但真实系统很少只靠一个裸循环解决所有问题,更多时候会把多次 LLM 调用、多个 Agent 或多个工具按某种结构组织起来,以换取更高的可靠性、质量或速度。
这些组织结构在实践中逐渐沉淀成一组设计模式。本章的重点不是死记硬背各种模式名称,而是要建立一种判断力:面对一个任务,应该用哪种结构?是使用确定性工作流、单 Agent、多 Agent,还是根本不需要复杂结构。
学习目标
学完本章,你应该能够:
- 用“工作流 vs 智能体”的框架判断任务应该用确定性编排还是自主 Agent;
- 实现并区分五种核心模式:Prompt Chaining、Routing、Parallelization、Evaluator-Optimizer 和 Orchestrator-Workers;
- 理解 Planner / Generator / Evaluator 三 Agent 范式,并用它落地一个代码审查 Agent;
- 清楚说明什么时候不该上多 Agent,理解多 Agent 的 token 成本、延迟、调试难度和失败模式;
- 在 Go 中用
context、goroutine、接口和结构化输出,把这些模式组织成可维护的代码。
本章承接 M04 的 Agent 核心。后续 M06会把工具系统做完整,M08会把本章模式扩展到多智能体系统,M10会讨论复杂 Agent 的观测、评估和调试。
配套练习是一个小型代码审查 Agent:Planner 规划审查维度,Generator 并行审查,Evaluator 评估并补漏。
5.1 工作流与智能体
在写代码之前,先把工作流和智能体的概念搞清楚。Anthropic 在 Building Effective Agents 中把这类系统分成两大类:工作流和智能体。这个区分非常适合落到 Go 工程里。
- 工作流(Workflow)是确定性编排。LLM 调用和工具按预先写定的代码路径执行,每一步走向哪里由代码决定,模型负责完成某个步骤中的内容。这类结构可预测、可测试、成本低。
- 智能体(Agent)则把更多控制权交给模型。下一步做什么、调用什么工具、何时结束,模型在运行时根据上下文和观察结果决定。M04 4.4 ReAct 循环就是这种结构。它更灵活,适合开放任务,但也更贵、更难预测、更难调试。
这两者不是非黑即白,而更像是一条光谱。本章前几个模式更偏工作流,后几个模式逐渐把更多决策权交给模型。
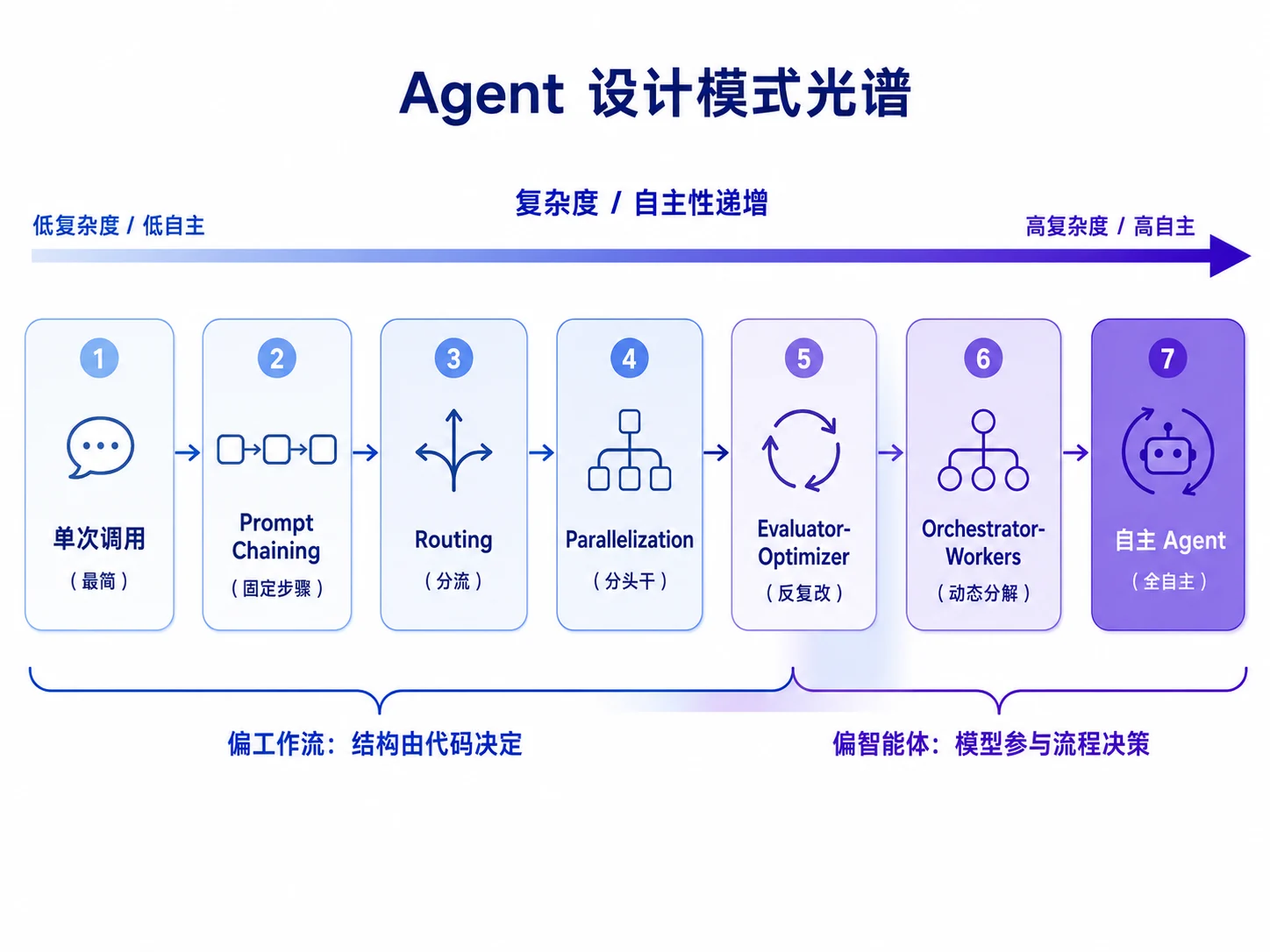
这张图对应一个工程判断:模式是为了解决具体痛点,不是为了让系统看起来复杂。很多任务一次精心设计的模型调用,配合好的上下文和少量检索,已经足够。只有当简单方案在质量、可靠性、速度或可维护性上确实不够时,才应该引入更复杂的模式。
5.2 增强型 LLM
所有模式的基础组件,可以称为增强型 LLM:一个能调用工具、能检索、有记忆的模型调用单元。M04 做出的 agent.Agent就是这类构件的一个版本;后续 M07 的记忆与 RAG会让它更完整。
为了让本章模式代码更清楚,先准备一个最轻量的组件:一次带系统提示词的模型调用。它不包含工具循环,只是把 System 和 User 消息发给模型并返回文本。Prompt Chaining、Routing、Voting 这些模式都可以建立在它之上。
package patterns
import (
"context"
"github.com/yourname/llmagent/internal/llm"
)
// complete 是一次最朴素的模型调用:给系统提示词和用户输入,返回文本。
// 本章很多模式都建立在它之上。
func complete(ctx context.Context, p llm.Provider, model, system, user string) (string, error) {
resp, err := p.Chat(ctx, llm.ChatRequest{
Model: model,
Messages: []llm.Message{
{Role: llm.RoleSystem, Content: system},
{Role: llm.RoleUser, Content: user},
},
})
if err != nil {
return "", err
}
return resp.Content, nil
}需要工具循环时,就使用 M04 的 agent.Agent;不需要工具时,就使用 complete。按需选择构件的重量,是本章所有模式都要遵循的原则。
5.3 Prompt Chaining
Prompt Chaining 解决的是“一个任务能清晰拆成固定几步”的问题。比如先生成产品文案,再翻译成英文,再压缩到 100 词以内。如果把所有要求塞进一次提示词,模型可能顾此失彼;拆成几步后,每一步只做一件事,结果通常更稳定。
它的结构是线性串联:前一步输出作为后一步输入。必要时,可以在步骤之间加入 gate 做校验,例如第一步生成的 JSON 必须能解析,否则提前中止,不继续浪费后续调用。
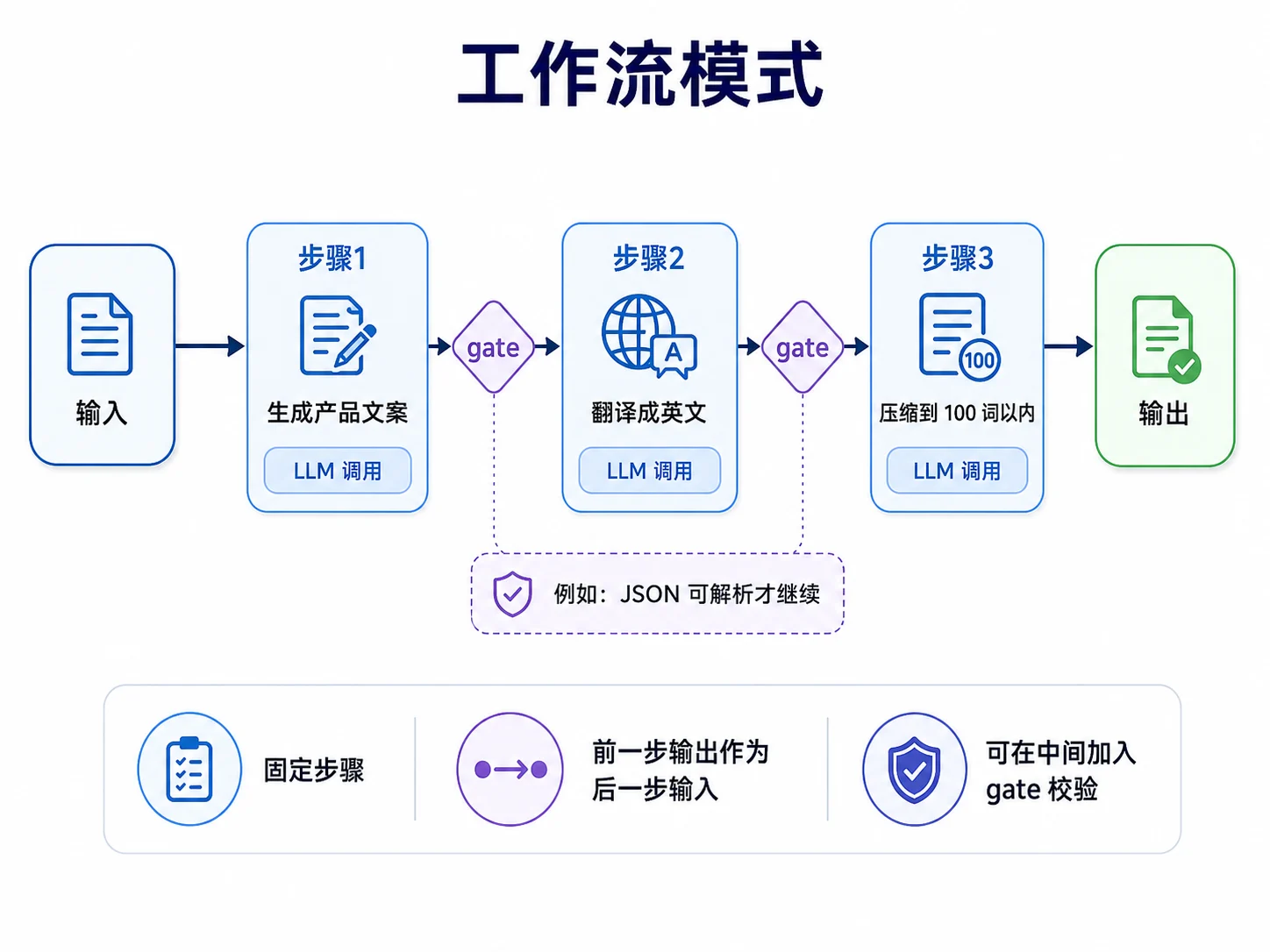
代码实现里,把“每个步骤”抽象成 ChainStep:它知道自己叫什么、用什么系统提示词、如何从上一步输出构造本步输入,以及可选的校验逻辑。
package patterns
import (
"context"
"fmt"
"github.com/yourname/llmagent/internal/llm"
)
type ChainStep struct {
Name string // 步骤名,用于报错定位
System string // 本步的系统提示词
Build func(prev string) string // 用上一步输出构造本步用户输入
Gate func(out string) error // 可选:校验本步输出,返回 err 则中止链
}
// RunChain 顺序执行各步骤,前一步输出作为后一步输入。
func RunChain(ctx context.Context, p llm.Provider, model, input string, steps []ChainStep) (string, error) {
cur := input
for _, s := range steps {
out, err := complete(ctx, p, model, s.System, s.Build(cur))
if err != nil {
return "", fmt.Errorf("步骤 %q 调用失败: %w", s.Name, err)
}
if s.Gate != nil {
if err := s.Gate(out); err != nil {
return "", fmt.Errorf("步骤 %q 校验未通过: %w", s.Name, err)
}
}
cur = out
}
return cur, nil
}Gate 是 Prompt Chaining 里很重要的设计点。它让链条可以在中间尽早失败:与其让一个跑偏的中间结果污染后面所有步骤,不如在出错那一步就拦下来。这是“用确定性代码约束不确定模型”的典型手法。
不适合使用 Chaining 的情况也很明确:如果步骤序列不是固定的,而是要根据输入现场决定,那么应该考虑 Routing 或 M04 的 Agent 循环。
5.4 Routing
Routing 解决的是输入种类差异很大的问题。一套提示词、一个处理器很难通吃所有类型的任务。用户可能在同一个入口里写代码、查文档、做计算、闲聊,这些请求需要不同提示词、工具、模型甚至完全不同的处理流程。
Routing 的结构是:先用一次轻量 LLM 调用做意图分类,再把请求分发给对应的专门处理器。处理器可以是一次 complete,也可以是一条 Chain、一个 agent.Agent,甚至是另一个路由器。
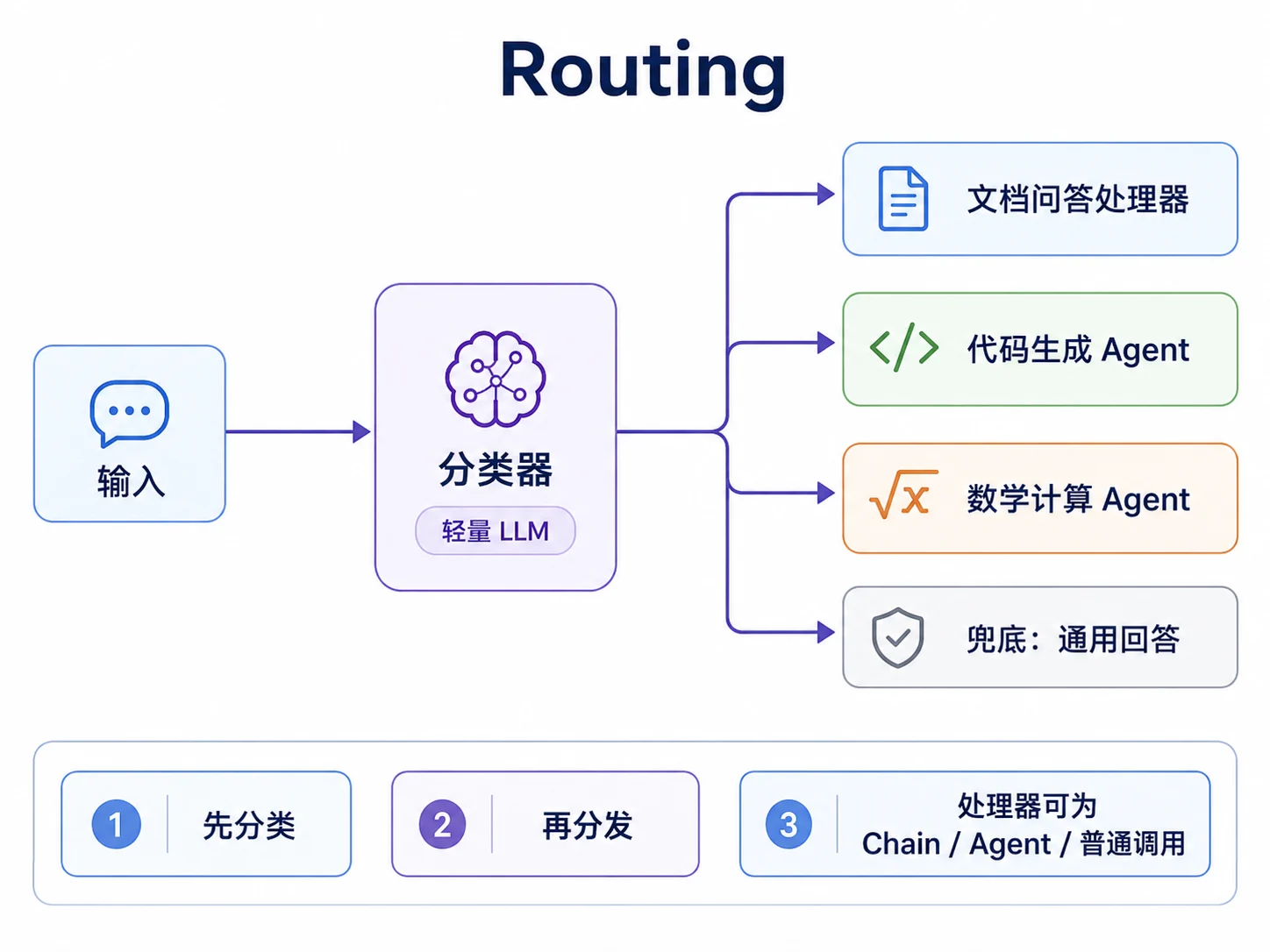
代码上,每个路由目标是一个 Route,包含名字、描述和处理函数。分类器把所有路由描述交给模型,让它输出结构化意图名,再用 M02 2.8的 ParseInto 解析。
package patterns
import (
"context"
"fmt"
"strings"
"github.com/yourname/llmagent/internal/llm"
)
type Route struct {
Name string // 意图名,如 "code_gen"
Description string // 给分类器看的说明,如 "用户想让你写或修改代码"
Handle func(ctx context.Context, input string) (string, error)
}
type IntentRouter struct {
Provider llm.Provider
Model string
Routes []Route
Fallback func(ctx context.Context, input string) (string, error) // 分类失败/无匹配时
}
// routeChoice 是分类器的结构化输出。
type routeChoice struct {
Route string `json:"route"`
}
func (r *IntentRouter) Dispatch(ctx context.Context, input string) (string, error) {
name, err := r.classify(ctx, input)
if err == nil {
for _, rt := range r.Routes {
if rt.Name == name {
return rt.Handle(ctx, input)
}
}
}
// 分类出错或没匹配上:走兜底(这本身就是一种优雅降级)
if r.Fallback != nil {
return r.Fallback(ctx, input)
}
return "", fmt.Errorf("无法路由,且未配置兜底(意图=%q, err=%v)", name, err)
}
func (r *IntentRouter) classify(ctx context.Context, input string) (string, error) {
var b strings.Builder
for _, rt := range r.Routes {
fmt.Fprintf(&b, "- %s: %s\n", rt.Name, rt.Description)
}
system := "你是意图分类器。从下列类别中选出最匹配用户输入的一个," +
"严格只输出 JSON:{\"route\": \"类别名\"}。\n类别:\n" + b.String()
out, err := complete(ctx, r.Provider, r.Model, system, input)
if err != nil {
return "", err
}
choice, err := llm.ParseInto[routeChoice](out)
if err != nil {
return "", fmt.Errorf("分类输出无法解析: %w", err)
}
return choice.Route, nil
}这里有两个工程细节。
第一,分类通常可以用更快、更便宜的小模型。它只是做一道选择题,不一定需要旗舰模型。
第二,Fallback 不是可有可无的,而是必需品。分类器偶尔会输出意料外的类别名,或者把 JSON 包在 Markdown 代码块里,导致解析失败。生产中应该先抽取 JSON 片段,再解析;本章先靠“严格只输出 JSON”的提示词和 Fallback 兜底,M06 6.2 类型安全工具会把工具输入输出解析做得更完整。
5.5 Parallelization
Parallelization 解决两类问题:
- 有些任务天然可以拆开并行做,串行执行会浪费时间;
- 还有些场景下让模型从多个角度独立判断、再综合,比单次判断更可靠。Go 的并发能力在这里可以直接体现出收益。
并行化有两种典型形态:
- Sectioning:把一个大任务切成互不依赖的子任务,并行执行,再汇总。例如代码审查时,并发安全、错误处理、性能、可读性可以分开审查。
- Voting:对同一个任务独立跑多次,或用不同提示词跑多次,再按多数或共识聚合。例如内容安全或风控判断,可以用多次独立判断降低单次误判风险。
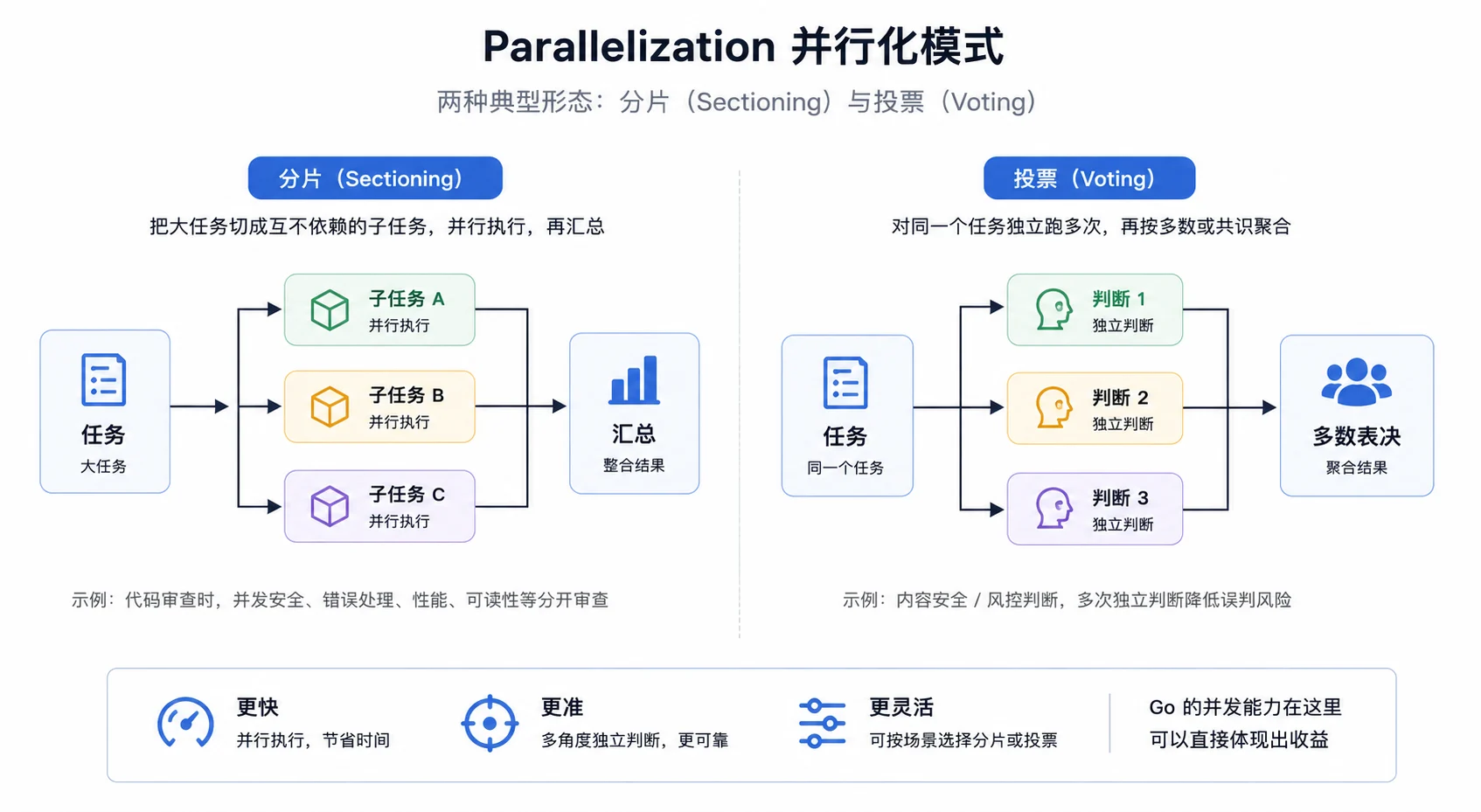
底层逻辑都是“并行跑一批任务,收集结果”,所以先写一个通用的并行执行器。它复用 M04 4.9 Plan-and-Execute里的并发纪律:WaitGroup 等待、sync.Once 记录首错、context 取消传播。
package patterns
import (
"context"
"sync"
)
// Sectioning 并行执行一批互不依赖的任务,按原顺序返回结果;任一失败即整体失败。
func Sectioning(ctx context.Context, tasks []func(context.Context) (string, error)) ([]string, error) {
results := make([]string, len(tasks))
var wg sync.WaitGroup
var firstErr error
var once sync.Once
cctx, cancel := context.WithCancel(ctx)
defer cancel()
for i, task := range tasks {
wg.Add(1)
go func(i int, task func(context.Context) (string, error)) {
defer wg.Done()
out, err := task(cctx)
if err != nil {
once.Do(func() { firstErr = err; cancel() })
return
}
results[i] = out // 每个 goroutine 只写自己的下标,互不重叠,无需加锁
}(i, task)
}
wg.Wait()
if firstErr != nil {
return nil, firstErr
}
return results, nil
}上述代码中的 results[i] = out 没有加锁,这是合理的:多个 goroutine 虽然并发写同一个 slice,但每个 goroutine 只写自己的下标,内存位置不重叠。这个模式可以理解为用“分区写入”替代锁。落地后可以用 go test -race 验证。
有了 Sectioning,Voting 就是它的一个特例:同一个任务跑 N 次。
package patterns
import (
"context"
"github.com/yourname/llmagent/internal/llm"
)
// Voting 用相同提示词独立跑 n 次,返回 n 个结果,交给上层聚合。
func Voting(ctx context.Context, p llm.Provider, model, system, user string, n int) ([]string, error) {
tasks := make([]func(context.Context) (string, error), n)
for i := range tasks {
tasks[i] = func(ctx context.Context) (string, error) {
return complete(ctx, p, model, system, user)
}
}
return Sectioning(ctx, tasks)
}
// Majority 返回出现次数最多的结果,适合"是/否"或有限类别的投票。
func Majority(votes []string) string {
counts := make(map[string]int)
best, bestN := "", 0
for _, v := range votes {
counts[v]++
if counts[v] > bestN {
best, bestN = v, counts[v]
}
}
return best
}Parallelization 不适合所有场景。Voting 会把模型调用成本放大 N 倍,只有在可靠性比成本更重要的场景才划算。Sectioning 要求子任务真正独立;如果子任务之间有依赖,那应该使用 M04 的 Plan-and-Execute,而不是简单并行。
5.6 Evaluator-Optimizer
Evaluator-Optimizer 解决的是“一次生成能用,但质量不够好”的问题。比如一段代码、一份报告、一封客诉回复,常常需要先生成,再评估,再根据反馈修改。
这个模式也常被称为 Reflection。它和 M04 4.7 错误自愈形状相似,但目标不同:错误自愈针对格式坏了、工具挂了这类运行错误;Evaluator-Optimizer 针对输出质量,希望把“能用”打磨到“更好”。
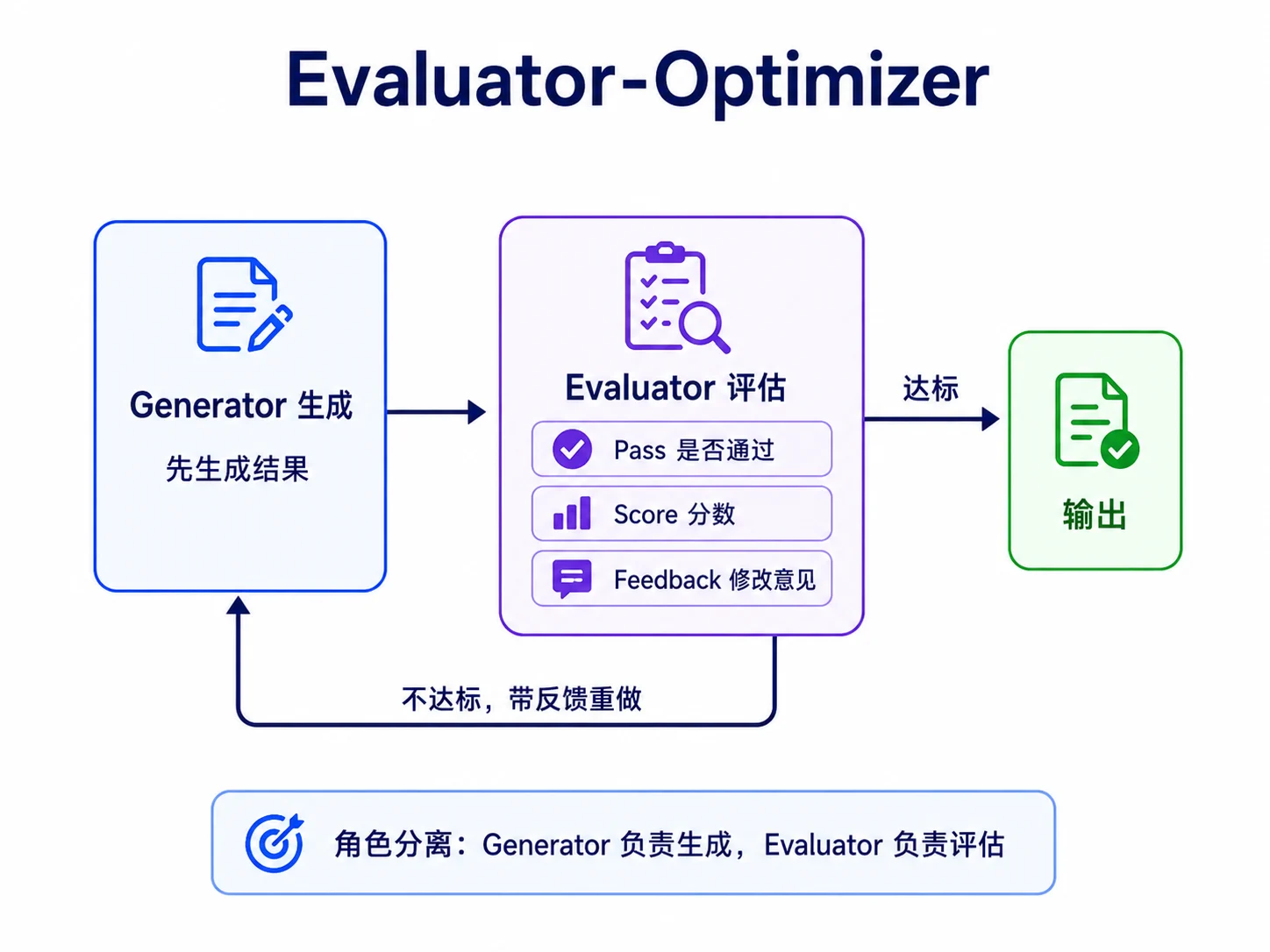
关键设计是把生成和评估做成两个独立角色,往往使用不同提示词,必要时甚至使用不同模型。让同一个调用既当生成者又当裁判,容易给自己过高评价;角色分离后,评估者可以更挑剔,效果也通常会更好一些。
评估结果要结构化,至少包含是否通过、分数和修改意见。生成器和评估器可以抽象成函数类型。
package patterns
import "context"
// Evaluation 是评估者的结构化输出。
type Evaluation struct {
Pass bool `json:"pass"` // 是否达标
Score int `json:"score"` // 0-100 分
Feedback string `json:"feedback"` // 不达标时的具体修改意见
}
// Generator 根据上一轮反馈生成内容(首轮 feedback 为空)。
type Generator func(ctx context.Context, feedback string) (string, error)
// Evaluator 评估一份内容,给出是否达标与反馈。
type Evaluator func(ctx context.Context, output string) (Evaluation, error)
// EvaluatorOptimizer 生成→评估→(不达标则带反馈重生成)循环,至多 maxRounds 轮。
// 返回最终内容、最后一次评估、错误。
func EvaluatorOptimizer(ctx context.Context, gen Generator, eval Evaluator, maxRounds int) (string, Evaluation, error) {
var output string
var ev Evaluation
feedback := ""
for round := 0; round < maxRounds; round++ {
var err error
output, err = gen(ctx, feedback)
if err != nil {
return "", ev, err
}
ev, err = eval(ctx, output)
if err != nil {
return "", ev, err
}
if ev.Pass {
return output, ev, nil // 达标,提前返回
}
feedback = ev.Feedback // 带着意见进入下一轮
}
return output, ev, nil // 用尽轮次:返回最后一版(注意 ev.Pass 可能为 false)
}maxRounds 是硬上限。任何让模型反复迭代的循环都必须有停止条件,否则一个永远不满意的评估者可以把预算耗尽。返回时保留最后一次评估,可以让调用方知道结果是否真正达标,再决定接受、降级还是让用户确认。
不适合使用 Evaluator-Optimizer 的场景也很明确:如果没有清晰、可操作的评估标准,反思循环就容易空转。它适合代码审查、报告完整性检查、客服回复覆盖度检查这类“好坏有判据”的任务,不适合完全主观的偏好任务。
5.7 Orchestrator-Workers
Orchestrator-Workers 解决的是“子任务结构需要运行时决定”的问题。前面的 Sectioning 要求你事先知道怎么切分任务,但很多复杂任务只有看了具体输入才知道要拆成哪些子任务。
比如“帮我重构这个模块”,要改哪些文件、每个文件做什么、是否需要先查调用关系,都需要分析后才能确定。
结构上,一个 Orchestrator 负责把任务动态拆解成若干子任务,为每个子任务派发一个 Worker,最后再综合各 Worker 的结果。
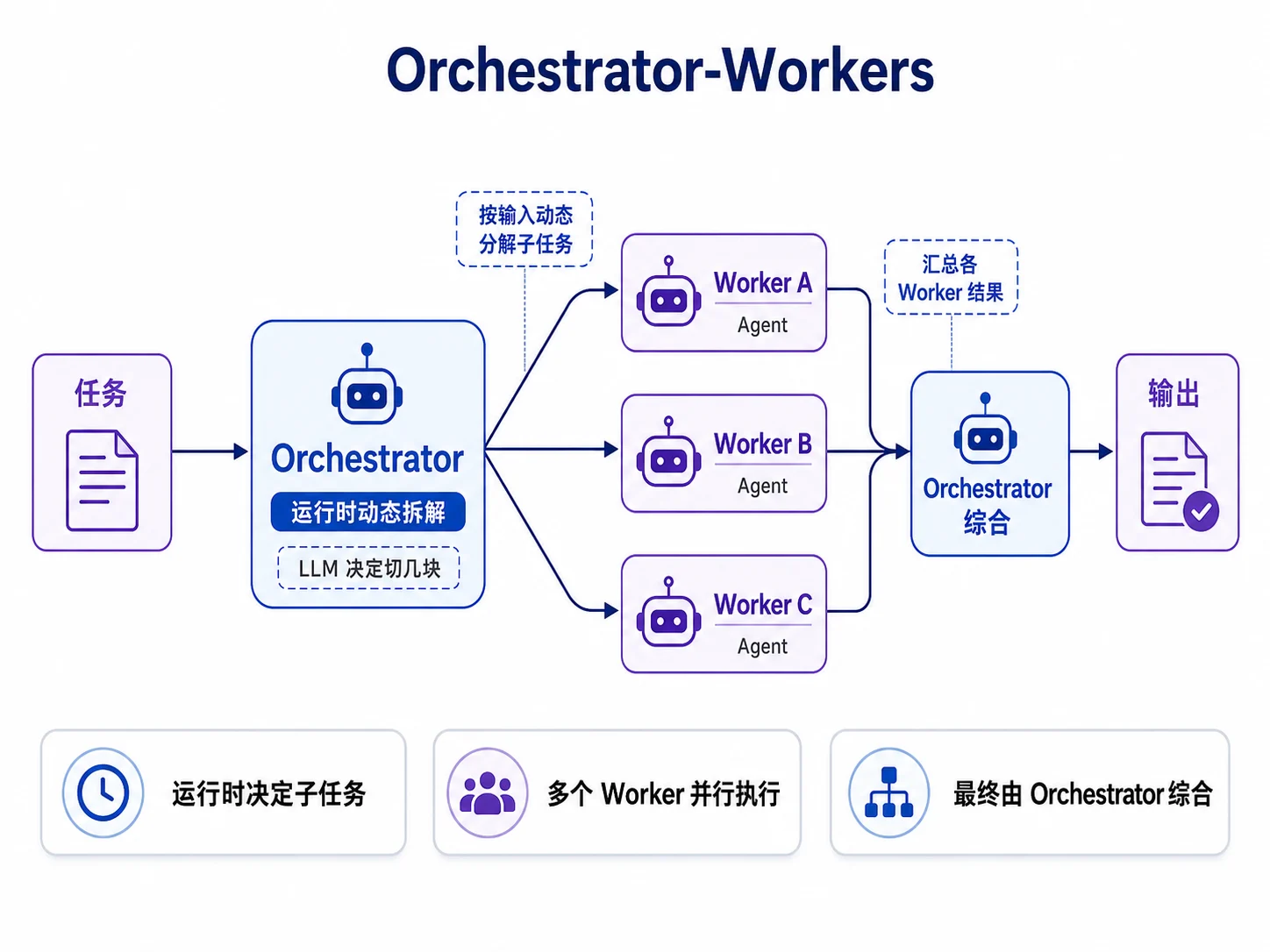
它和 Sectioning 的本质区别是:子任务划分由模型在运行时决定,而不是代码提前写死。也正因为如此,它开始从工作流滑向智能体。
实现分三步:先让 Orchestrator 结构化输出子任务;再并行执行 Worker,复用前面的 Sectioning;最后让 Orchestrator 综合结果。
先给 M04 的 Agent补一个非流式公开入口,方便当 Worker 使用。
// agent 包:补一个公开的非流式入口(包装 M04 的 runFunctionCalling)
func (a *Agent) Run(ctx context.Context, goal string) (string, error) {
st, err := a.runFunctionCalling(ctx, goal)
if err != nil {
return "", err
}
return st.Answer, nil
}然后实现编排者。
package patterns
import (
"context"
"fmt"
"strings"
"github.com/yourname/llmagent/internal/agent"
"github.com/yourname/llmagent/internal/llm"
)
type subtask struct {
ID string `json:"id"`
Description string `json:"description"`
}
type decomposition struct {
Subtasks []subtask `json:"subtasks"`
}
type Orchestrator struct {
Provider llm.Provider
Model string
NewWorker func() *agent.Agent // 工厂:每个子任务一个全新 worker,上下文互相隔离
}
func (o *Orchestrator) Run(ctx context.Context, goal string) (string, error) {
// 1) 分解:让编排者把任务拆成子任务(结构化输出)
system := "你是任务编排者。把用户任务拆解为若干可独立完成的子任务," +
"严格只输出 JSON:{\"subtasks\":[{\"id\":\"t1\",\"description\":\"...\"}]}"
raw, err := complete(ctx, o.Provider, o.Model, system, goal)
if err != nil {
return "", err
}
d, err := llm.ParseInto[decomposition](raw)
if err != nil {
return "", fmt.Errorf("分解结果无法解析: %w", err)
}
if len(d.Subtasks) == 0 {
return "", fmt.Errorf("编排者未产出任何子任务")
}
// 2) 并行执行:每个子任务一个独立 worker(上下文隔离,互不污染)
tasks := make([]func(context.Context) (string, error), len(d.Subtasks))
for i, st := range d.Subtasks {
st := st // 捕获循环变量(Go 1.22+ 已自动,这里显式以兼容旧版)
tasks[i] = func(ctx context.Context) (string, error) {
worker := o.NewWorker()
res, err := worker.Run(ctx, st.Description)
if err != nil {
return "", fmt.Errorf("子任务 %s 失败: %w", st.ID, err)
}
return fmt.Sprintf("[%s] %s\n%s", st.ID, st.Description, res), nil
}
}
results, err := Sectioning(ctx, tasks)
if err != nil {
return "", err
}
// 3) 综合:把各 worker 的结果交给编排者整合成最终回答
synthSystem := "下面是各子任务的执行结果,请综合成对原始任务的完整、连贯的回答。"
return complete(ctx, o.Provider, o.Model, synthSystem,
"原始任务:\n"+goal+"\n\n子任务结果:\n"+strings.Join(results, "\n\n"))
}这里 NewWorker 是工厂函数,而不是一个共享 Agent。每个子任务都拿到一个新的 Agent,上下文彼此隔离。这样做能避免不同子任务互相污染对话历史,也是 M08 8.5 隔离 Subagent和 M09 9.6 上下文隔离都会反复用到的思想。
Orchestrator-Workers 是本章最重的模式。它需要一次分解调用、N 个 Worker 的完整执行,再加一次综合调用。只有当任务确实复杂到无法预先切分,且子任务并行价值很高时才值得使用。
5.8 三 Agent 范式
把前面几个模式组合起来,就得到一个非常强力、也是 Anthropic 在构建高效智能体应用时极力推崇的通用骨架——三 Agent 范式:Planner、Generator、Evaluator。
- Planner:分析任务,产出计划或检查清单;
- Generator:按计划逐项产出内容,必要时内部使用工具;
- Evaluator:对照计划和质量标准检查产出,给出通过与否和改进意见;不通过则回到 Generator 重做。
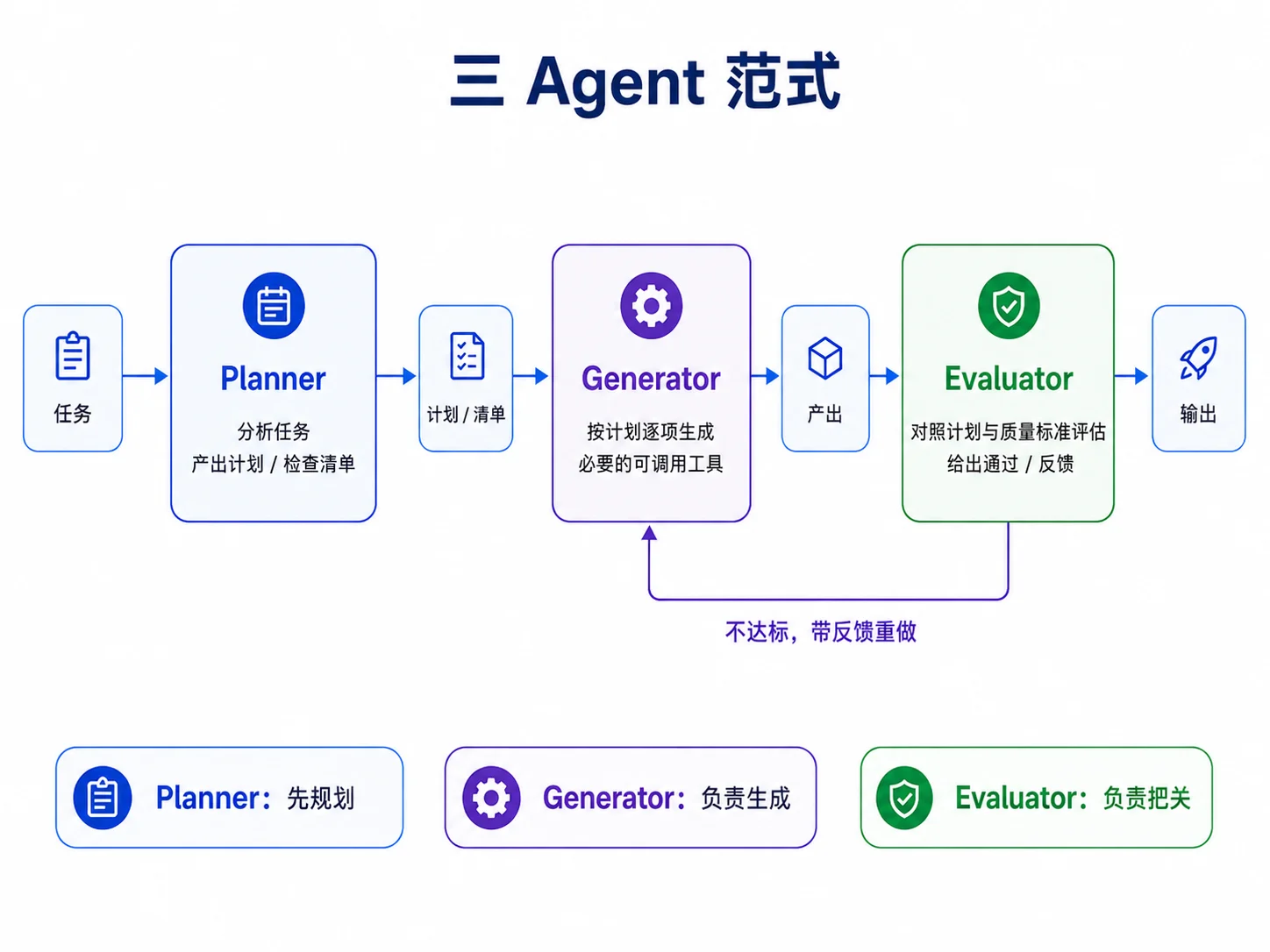
这个范式的价值在于职责分离和自我校正。Planner 保证不漏要点,Generator 专注产出,Evaluator 独立把关。三者用不同提示词,各自负责一个角色,通常比一个“既规划又生成又检查”的全能 Agent 更稳定。
本章练习里的代码审查 Agent 就采用这个范式:Planner 决定审查维度,Generator 逐维度审查,Evaluator 判断报告是否充分。实现上不需要新的原语,它就是 complete、agent.Run、Sectioning 和 EvaluatorOptimizer 的组合。
5.9 是否使用多 Agent
前面讲了多种组合方式,但成熟工程师的标志之一,是知道什么时候不这么做。多 Agent 和复杂模式会带来 token 成本、延迟、调试难度和失败模式的叠加。
Anthropic 在其多 Agent 研究系统经验中提到,在它们的数据里,普通 Agent 通常使用约 4 倍于聊天交互的 token,多 Agent 系统约为聊天交互的 15 倍。这个数字不是所有场景的通用常量,但足以说明一个事实:每增加一层协作,成本和复杂度都会明显上升。
典型失败模式包括:
- 协调开销吞掉收益:Agent 之间传递上下文、等待彼此、综合结果,可能比直接让一个 Agent 做还慢;
- 错误逐级放大:Planner 拆错,Generator 再努力也是错的;某个 Worker 产出垃圾,综合阶段会把错误揉进最终答案;
- 调试难度上升:单 Agent 只看一条轨迹,多 Agent 要看多条交织轨迹;
- 不确定性叠加:每个 LLM 调用都有随机性,多个调用串并起来,整体行为更难复现。
在增加模式或 Agent 前,逐条问自己:
- 更简单的方案真的不够吗?一次精心设计的调用、配上好的提示词和检索,能不能解决?
- 任务能从并行或分解中获得真实收益吗?如果子任务有强依赖,多 Agent 只是徒增开销;
- 质量提升是否值得额外 token、延迟和复杂度?内部工具和大规模用户产品的答案可能不同;
- 是否有能力观测和调试它?没有 M10 的可观测设施,上复杂 Agent 后很难排查问题;
- 如果流程稳定且业务方比工程方更懂“对错”,是否应该把流程下沉成 Skill,而不是继续堆 Agent?
5.10 模式选型
把本章五种模式放到工程坐标里,可以得到一张选型表:
| 维度 | Prompt Chaining | Routing | Parallelization | Evaluator-Optimizer | Orchestrator-Workers |
|---|---|---|---|---|---|
| 解决痛点 | 一次做不完,固定拆 | 任务类型多样 | 子任务独立可并行 | 一次输出质量不够 | 任务结构运行时才知道 |
| 控制流 | 静态线性 | 动态分支 | 静态并行 | 静态循环 | 动态分解 |
| LLM 调用次数 | 固定 N | 路由 + 处理 | 固定 N | 多轮循环 | 动态,通常较多 |
| 延迟 | 串行累积 | 多一次路由 | 可并行,较快 | 多轮,较慢 | 高度变化 |
| Token 成本 | 中 | 低到中 | 中 | 高 | 中到高 |
| 收敛性 | 流水线尽头 | 路由完即收敛 | 等所有 worker | 评估通过或超限 | 编排者决定 |
| 可调试性 | 容易 | 中等 | 中等 | 中等 | 较难 |
| 失败模式 | 一环错全错 | 路由错导致后续错 | 一个 worker 慢拖整体 | 评估器弱或死循环 | 编排者拆解错导致整体错 |
| 典型场景 | 多步翻译、报告生成 | 客服分诊、多语言路由 | 文档分段总结、多视角分析 | 文案优化、代码审查 | 复杂研究、未知任务 |
可以把选型过程组织成下面这棵决策树。
有一个 LLM 任务要做
│
├─ 单次精心调用 + 好 prompt 够吗?
│ └─ 够 → 单次调用或单 Agent,不上模式
│
├─ 任务类型多样,需要分流?
│ └─ 是 → Routing 前置
│
├─ 路径已知,可拆固定几步?
│ │
│ ├─ 步骤独立可并行?
│ │ └─ 是 → Parallelization
│ │
│ └─ 步骤有依赖,需要串行?
│ └─ 是 → Prompt Chaining
│
├─ 一次质量不够,需要反复打磨?
│ └─ 是 → Evaluator-Optimizer
│
├─ 任务结构未知,运行时才能决定?
│ └─ 是 → Orchestrator-Workers
│
└─ 多 Agent 协作场景明显?
└─ 是 → 进入 M08 多智能体拓扑M05 的模式与 M08 的多 Agent 拓扑有联系,但层级不同。M05 关注单个 Agent 或一组 LLM 调用如何组织任务;M08 关注多个独立 Agent 之间如何协作。
| 本章模式 | M08 对应方向 | 关系 |
|---|---|---|
| Prompt Chaining | Pipeline | 概念接近,但本章多在单 Agent 内串联,M08是多个独立 Agent |
| Routing | Swarm / Handoff | 都涉及路由转交,但 Swarm 更去中心化 |
| Parallelization | Orchestrator 下的并行子代理 | 并行思想延续 |
| Evaluator-Optimizer | Debate / Critic | 都是反复评估和修正 |
| Orchestrator-Workers | Orchestrator + 子代理 | 最直接的升级路径 |
升级路径应该是平滑的:能用单次调用就不要上模式;能用本章单 Agent 内模式就不要直接上 M08 多 Agent 系统;只有当子任务复杂到需要独立上下文、不同工具集或明确协作协议时,再升级到多 Agent。
配套练习:小型代码审查 Agent
用三 Agent 范式做一个能审查 Go 代码片段的小工具,把本章模式串起来。
需求:输入一段 Go 代码,输出结构化审查报告。用三 Agent 范式组织:
- Planner:分析代码,决定要审查哪些维度,例如正确性、并发安全、错误处理、性能、可读性,并输出结构化维度清单;
- Generator:对每个维度并行审查,使用
Sectioning,各自产出该维度的发现; - Evaluator:汇总后评估报告是否充分,例如是否漏掉明显问题、发现是否具体可操作;不达标则带反馈让 Generator 补充,使用
EvaluatorOptimizer。
验收点:
- Planner 用
complete和ParseInto产出维度清单; - Generator 用
Sectioning对各维度并行审查; - 用
EvaluatorOptimizer包住“生成报告 → 评估 → 补漏”循环,并设置maxRounds; - 用
IntentRouter加一个前置分流:输入若不是代码,路由到普通回答而不是审查流程; - 在 README 里写下:这个任务真的需要三 Agent 吗?什么情况下一个精心提示的单次调用就够了?
代码骨架如下:
// 1) Planner:决定审查维度
type reviewPlan struct {
Dimensions []string `json:"dimensions"` // 如 ["并发安全","错误处理",...]
}
func planReview(ctx context.Context, p llm.Provider, model, code string) (reviewPlan, error) {
system := "你是资深 Go 评审。分析代码,列出最值得审查的 3-5 个维度," +
"只输出 JSON:{\"dimensions\":[\"...\"]}"
out, err := complete(ctx, p, model, system, code)
if err != nil {
return reviewPlan{}, err
}
return llm.ParseInto[reviewPlan](out)
}
// 2) Generator:每个维度并行审查(用 patterns.Sectioning)
// 3) Evaluator + EvaluatorOptimizer:评估报告是否充分,不足则补漏
// 4) IntentRouter:前置判断输入是否为代码
//
// TODO: 由你拼装。重点体会三个角色"各司其职"如何比一个全能 Agent 更稳。完成后建议做一个对比实验:再写一版单次调用版代码审查,把所有要求塞进一个提示词,用同一段代码跑两版,对比质量和 token 消耗。对短代码来说,单次调用可能又快又省,质量也够;只有面对长而复杂的代码,三 Agent 的分维度和自我把关才更可能体现价值。
本章小结
| 模式 | 解决的痛点 | 偏向 | 典型场景 |
|---|---|---|---|
| Prompt Chaining | 任务可拆成固定几步 | 工作流 | 文案生成、润色、合规检查 |
| Routing | 输入种类差异大 | 工作流 | 按意图分流到不同处理器 |
| Parallelization | 可并行或需多视角 | 工作流 | 多维度审查、内容安全投票 |
| Evaluator-Optimizer | 质量需反复打磨 | 中间 | 输出质量自动把关 |
| Orchestrator-Workers | 子任务需运行时决定 | 偏智能体 | 复杂任务动态分解 |
| 三 Agent 范式 | 需职责分离与自校正 | 偏智能体 | 代码审查、复杂报告 |
最重要的结论仍然是:默认用最简方案,只在实测不够时才加复杂度。复杂模式能提升能力,也会成倍放大成本、延迟和调试难度。
思考题
- Routing 的分类器本身也可能错。你会如何度量分类准确率?分类错误时,除了 Fallback,还能怎样让系统自我察觉并纠正?
- Orchestrator-Workers 里,Worker 之间完全隔离、互不通信。如果两个子任务需要共享中间结果,直接让它们通信会带来什么风险?
- 本章所有模式都把工具当成黑盒。一个工具如何描述自己、如何被模型正确调用、调用外部系统时如何防止被恶意利用?
下一步
下一章进入 M06 工具系统全貌。到那时,我们会把本章里反复出现的 tool.Tool、参数 Schema、工具调用结果、错误处理和安全约束系统化。Agent 模式能否稳定运行,很大程度取决于工具是否定义清楚、调用是否可控、失败是否能被模型理解。
参考资料
本章代码以讲解设计模式为目标。落到项目代码后,请在本机运行下面的命令复核。
go build ./...
go test ./...