M04 工具系统与外部集成
前一章我们已经实现了 Agent 的运行循环。Agent 可以根据目标、历史步骤和工具返回结果,不断决定下一步要做什么。
但如果 Agent 只能调用 LLM,它的能力边界仍然很有限。模型本身不能直接读取你的本地文件,不能查询数据库,不能访问业务系统,也不能真正执行一段分析代码。要让 Agent 进入真实业务场景,就必须为它提供一套可靠的工具系统。
这一章要解决的问题是:如何用 Go 设计一套可扩展、可测试、可约束的工具系统,让 Agent 能够安全地和外部世界交互。
学习目标
完成本章后,你应该能够:
- 理解 Agent 工具系统的基本组成
- 能够设计统一的
Tool接口和工具注册表 - 能够为工具输入生成 JSON Schema
- 能够实现 Web 搜索、HTTP 请求、文件和数据库类工具
- 理解代码执行工具为什么必须放到沙箱中运行
- 理解 NL2SQL 工具的基本流程与安全限制
- 能够完成一个数据分析 Agent 的最小可用版本
本章内容
- 工具系统架构设计
- 工具注册表与工具执行流程
- 通过 Go 结构体生成工具输入 Schema
- Web 搜索与 HTTP 工具实现
- 代码执行工具与 Docker 沙箱
- 数据库工具与 NL2SQL
- 浏览器自动化工具
- 数据分析 Agent 项目实践
- 工具执行安全原则
一、为什么 Agent 需要工具系统
Agent 的核心循环大致可以概括为:模型做决策,程序执行动作,再把结果反馈给模型。
这里的“动作”,在工程上通常就是工具调用。
比如:
- 用户问一个最新信息,Agent 需要调用搜索工具
- 用户要求分析 CSV 文件,Agent 需要调用文件读取工具和代码执行工具
- 用户希望查询业务数据,Agent 需要调用数据库工具
- 用户让 Agent 浏览网页内容,Agent 需要调用浏览器自动化工具
- 用户让 Agent 修改本地项目文件,Agent 需要调用受限的文件系统工具
如果没有工具系统,Agent 就只能停留在文本生成阶段;有了工具系统,Agent 才能访问外部信息、执行具体任务,并把中间结果纳入下一轮推理。
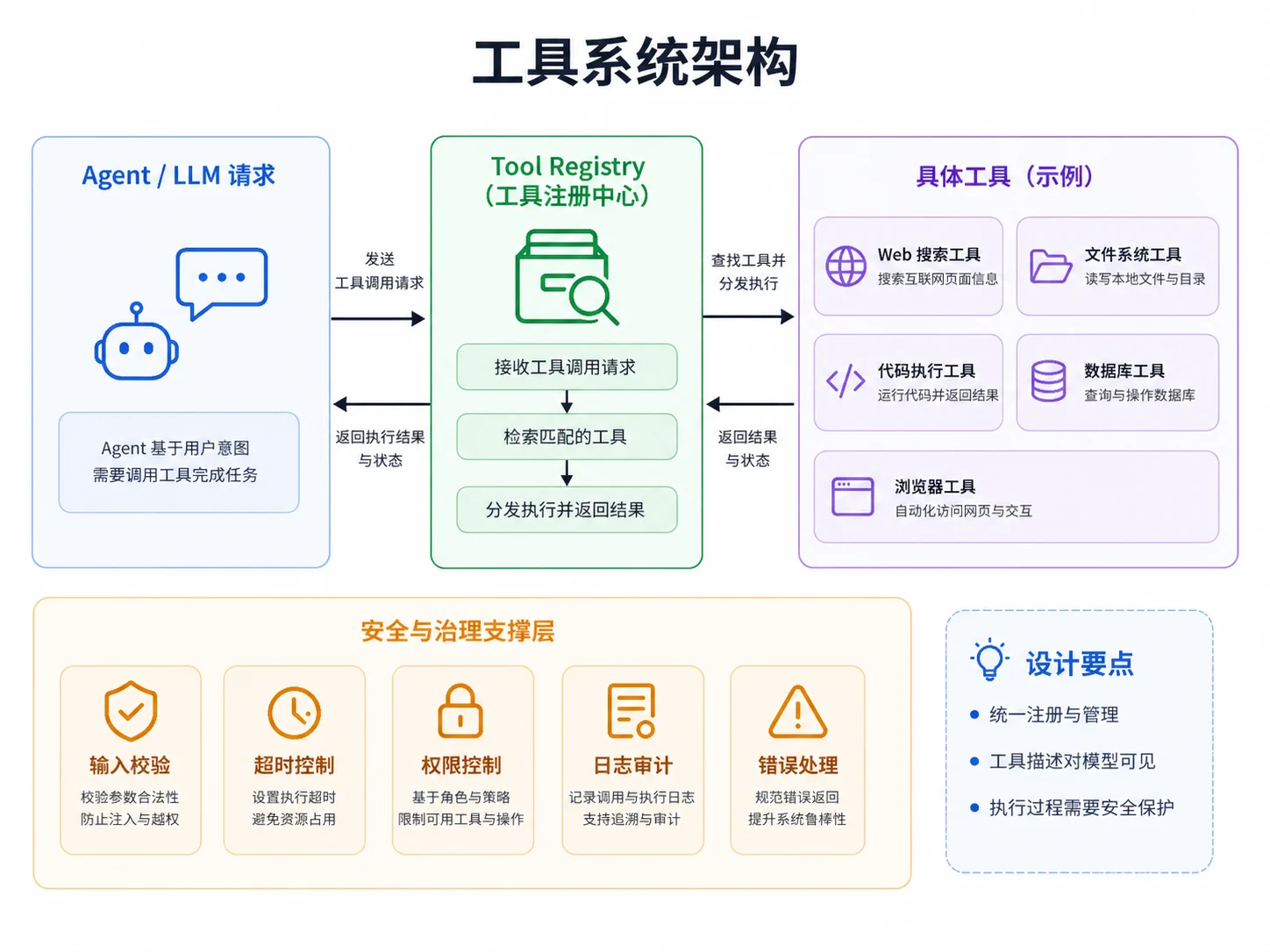
二、统一工具接口
设计工具系统时,第一步不是先实现搜索、数据库或者浏览器,而是先定义工具的公共抽象。
一个基础的工具接口可以这样设计:
type Tool interface {
Name() string
Description() string
InputSchema() json.RawMessage
Execute(ctx context.Context, input json.RawMessage) (string, error)
}这几个方法各自负责不同的事情:
Name:工具名称,供模型在 Tool Call 中引用Description:工具描述,告诉模型这个工具适合解决什么问题InputSchema:工具参数结构,通常以 JSON Schema 表示Execute:真正执行工具逻辑
这个接口看起来简单,但已经包含了工具系统最重要的几个约束:工具必须有名字,必须有说明,必须声明输入格式,必须通过统一入口执行。
1. 工具名要稳定
工具名会暴露给模型使用,所以不要频繁变化。
例如:
web_search
csv_reader
sql_query
python_executor
file_reader比下面这种名字更适合长期维护:
searchToolV2
runPythonNow
readFileNew工具名应该描述能力,而不是描述实现版本。
2. 工具描述要写给模型看
Description 不是写给用户看的文案,而是写给 LLM 的能力说明。
例如:
Search the web for recent information. Use this tool when the answer requires up-to-date facts.这样的描述可以帮助模型判断什么时候应该调用工具。
如果工具描述太含糊,模型就容易出现两个问题:
- 该调用工具时没有调用
- 不该调用工具时反复调用
三、工具注册表
有了统一接口以后,还需要一个工具注册表来管理所有工具。
注册表负责三件事:
- 注册工具
- 根据名称查找工具
- 统一执行工具并处理通用逻辑
基础实现如下:
type ToolRegistry struct {
tools map[string]Tool
mu sync.RWMutex
}
func NewToolRegistry() *ToolRegistry {
return &ToolRegistry{
tools: make(map[string]Tool),
}
}
func (r *ToolRegistry) Register(tool Tool) {
r.mu.Lock()
defer r.mu.Unlock()
r.tools[tool.Name()] = tool
}
func (r *ToolRegistry) Get(name string) (Tool, bool) {
r.mu.RLock()
defer r.mu.RUnlock()
tool, ok := r.tools[name]
return tool, ok
}工具执行入口可以继续收敛到注册表中:
func (r *ToolRegistry) Execute(
ctx context.Context,
name string,
input json.RawMessage,
) (string, error) {
r.mu.RLock()
tool, ok := r.tools[name]
r.mu.RUnlock()
if !ok {
return "", fmt.Errorf("unknown tool: %s", name)
}
ctx, cancel := context.WithTimeout(ctx, 30*time.Second)
defer cancel()
return tool.Execute(ctx, input)
}这里把超时控制放在注册表层,而不是每个工具各写一遍,主要是为了避免通用逻辑散落在各个工具实现中。
后续还可以在这一层继续加入:
- 调用日志
- 结果缓存
- 权限校验
- 资源限制
- 错误统一包装
- 工具调用指标统计
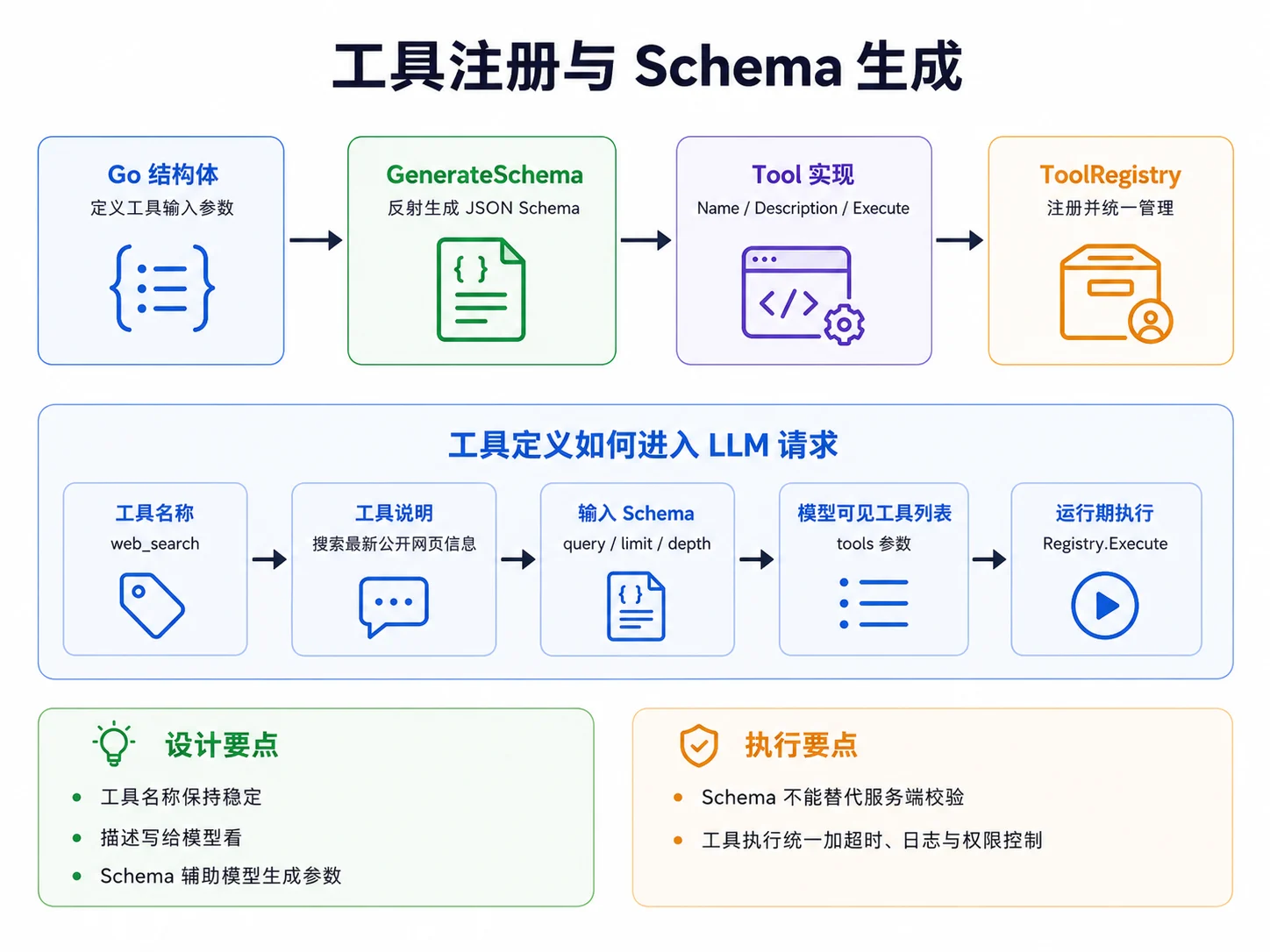
四、工具输入与 JSON Schema
Agent 调用工具时,模型需要知道工具接收哪些参数。最常见的方式是为每个工具提供 JSON Schema。
比如搜索工具的输入可以定义为:
type SearchInput struct {
Query string `json:"query" jsonschema:"description=The search query,required"`
Limit int `json:"limit" jsonschema:"description=Number of results,default=5"`
}然后通过 Go 结构体生成 Schema:
func GenerateSchema[T any]() json.RawMessage {
var zero T
t := reflect.TypeOf(zero)
schema := map[string]any{
"type": "object",
"properties": extractProperties(t),
"required": extractRequired(t),
}
b, _ := json.Marshal(schema)
return b
}这类工具代码在课程里可以先写一个简化版,理解核心流程即可。实际项目中,可以考虑使用成熟库来生成 JSON Schema,避免自己处理各种边界情况。
1. 为什么不要只靠自然语言描述参数
如果只在 Prompt 里告诉模型“搜索工具需要一个 query 参数”,模型可能输出各种格式:
{"query": "Go Agent framework"}也可能输出:
{"keyword": "Go Agent framework"}甚至输出:
{"q": "Go Agent framework", "num": 5}而 Schema 的作用,就是尽量把模型输出限制在程序可解析的结构内。
2. Schema 仍然不能替代服务端校验
即使模型使用了 JSON Schema,工具执行前也必须做服务端校验。
原因很简单:模型输出不是可信输入。
对于每一个工具,你都应该在执行前检查:
- 必填字段是否存在
- 字段类型是否正确
- 数值范围是否合理
- 字符串是否包含危险内容
- 文件路径是否越界
- SQL 是否符合限制
五、Web 搜索与 HTTP 工具
Web 搜索是 Agent 最常见的外部工具之一。
它适合处理这类问题:
- 需要最新信息
- 需要引用公开网页
- 需要查询文档、新闻或价格
- 模型自身知识可能过期
一个搜索工具的结构通常如下:
type WebSearchTool struct {
client *http.Client
apiKey string
}执行逻辑大致分成几步:
- 解析模型传入的 JSON 参数
- 校验查询词和搜索深度
- 构造 HTTP 请求
- 调用搜索 API
- 格式化搜索结果返回给 Agent
示例代码:
func (t *WebSearchTool) Execute(ctx context.Context, input json.RawMessage) (string, error) {
var params struct {
Query string `json:"query"`
Depth string `json:"search_depth"`
}
if err := json.Unmarshal(input, ¶ms); err != nil {
return "", err
}
reqBody := map[string]any{
"api_key": t.apiKey,
"query": params.Query,
}
body, _ := json.Marshal(reqBody)
req, err := http.NewRequestWithContext(
ctx,
http.MethodPost,
"https://api.tavily.com/search",
bytes.NewReader(body),
)
if err != nil {
return "", err
}
req.Header.Set("Content-Type", "application/json")
resp, err := t.client.Do(req)
if err != nil {
return "", err
}
defer resp.Body.Close()
var result TavilyResponse
if err := json.NewDecoder(resp.Body).Decode(&result); err != nil {
return "", err
}
return formatSearchResults(result.Results), nil
}这里比直接使用 client.Post 多做了一件事:把 ctx 传进请求。
这很重要。因为搜索请求属于 Agent 运行链路中的一个子步骤,如果用户取消任务,搜索请求也应该尽快取消。
context.Background()。工具应该继承 Agent 调用链传下来的 ctx,这样超时和取消才能正常传播。六、代码执行工具与安全沙箱
代码执行工具非常强大,也非常危险。
它可以让 Agent 编写 Python、Go 或 Shell 脚本来处理数据、生成图表、执行分析任务。但如果没有隔离,代码执行工具也可能访问宿主机文件、发起网络请求、消耗大量 CPU 或删除重要数据。
因此,代码执行工具必须放进沙箱里运行。
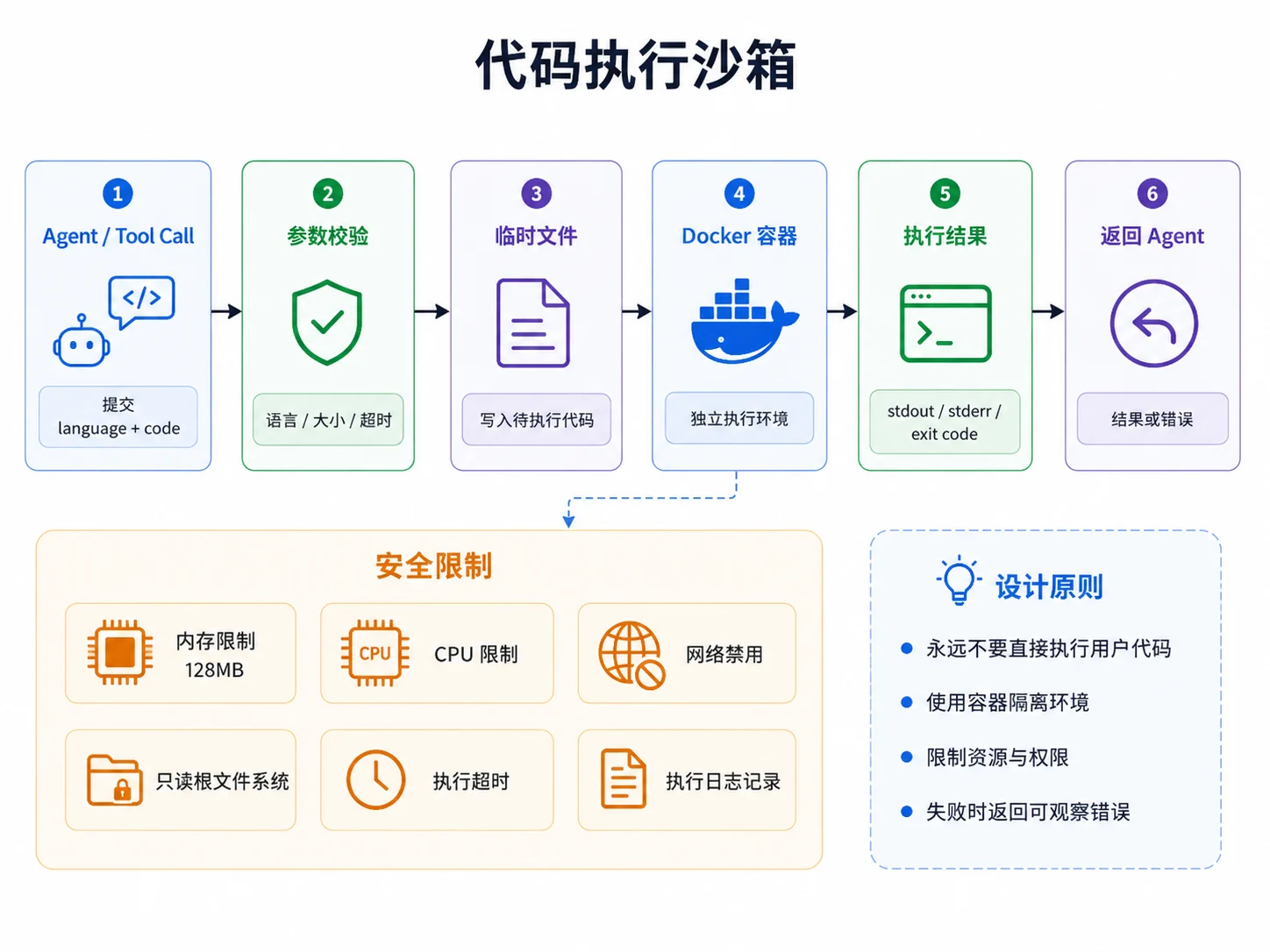
一个基础的代码执行工具可以这样定义:
type CodeExecutorTool struct {
dockerClient *client.Client
timeout time.Duration
}执行流程大致如下:
func (t *CodeExecutorTool) Execute(ctx context.Context, input json.RawMessage) (string, error) {
var params struct {
Language string `json:"language"`
Code string `json:"code"`
}
if err := json.Unmarshal(input, ¶ms); err != nil {
return "", err
}
tmpFile := writeTempFile(params.Code, extForLanguage(params.Language))
defer os.Remove(tmpFile)
ctx, cancel := context.WithTimeout(ctx, t.timeout)
defer cancel()
return t.runInContainer(ctx, params.Language, tmpFile)
}真正运行代码时,应当通过 Docker 或其他隔离环境限制资源:
resp, err := t.dockerClient.ContainerCreate(
ctx,
&container.Config{
Image: imageForLang(lang),
Cmd: cmdForLang(lang, file),
},
&container.HostConfig{
Resources: container.Resources{
Memory: 128 * 1024 * 1024,
CPUQuota: 50000,
},
NetworkMode: "none",
ReadonlyRootfs: true,
},
nil,
nil,
"",
)这个配置里有几个关键点:
Memory:限制内存使用CPUQuota:限制 CPU 使用NetworkMode: "none":禁用网络访问ReadonlyRootfs: true:使用只读根文件系统context.WithTimeout:限制最长执行时间
七、数据库工具与 NL2SQL
数据库工具可以让 Agent 查询结构化数据。
一个常见做法是:模型根据用户问题和表结构生成 SQL,程序验证 SQL 之后再执行查询。
流程如下:
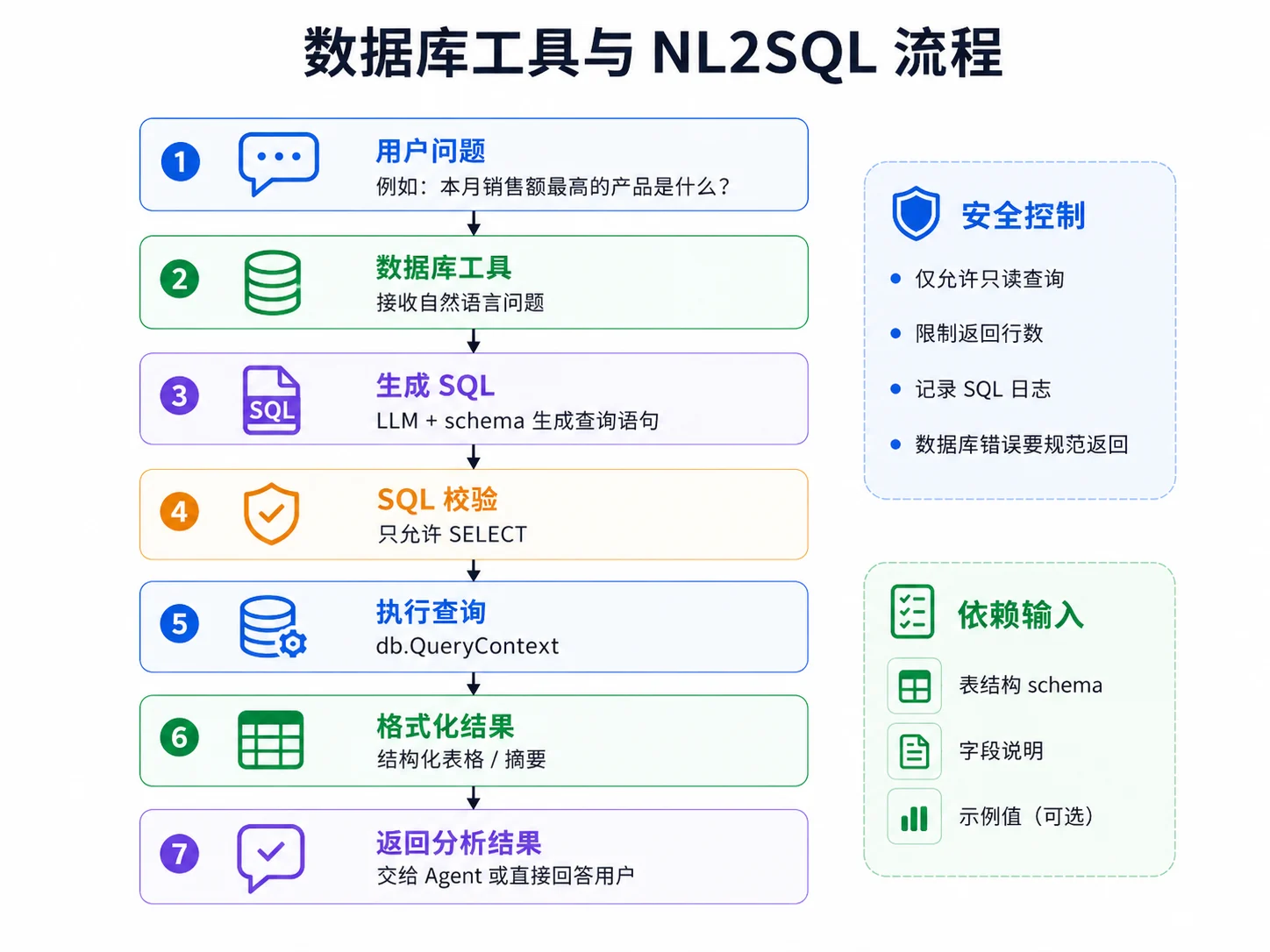
一个简化版数据库工具可以这样定义:
type DatabaseTool struct {
db *sql.DB
schema string
llm LLMProvider
}执行逻辑分三步:
func (t *DatabaseTool) Execute(ctx context.Context, input json.RawMessage) (string, error) {
var params struct {
Question string `json:"question"`
}
if err := json.Unmarshal(input, ¶ms); err != nil {
return "", err
}
query, err := t.generateSQL(ctx, params.Question)
if err != nil {
return "", err
}
if !isSelectOnly(query) {
return "", errors.New("only SELECT queries allowed")
}
rows, err := t.db.QueryContext(ctx, query)
if err != nil {
return "", fmt.Errorf("SQL error: %w", err)
}
defer rows.Close()
return formatQueryResults(rows), nil
}这里最重要的是 isSelectOnly。
对于一个面向分析场景的数据库工具,通常应该先只允许 SELECT 查询,禁止:
INSERTUPDATEDELETEDROPALTER- 多语句执行
如果后续确实需要写操作,也应该单独设计权限系统、审批流程和审计日志,而不是让模型自由生成可执行 SQL。
1. schema 很重要
NL2SQL 的效果很大程度上取决于模型看到的 schema 描述。
一个好的 schema 描述不应该只是列名,还应该包含:
- 表用途
- 字段含义
- 字段类型
- 枚举值说明
- 常见查询示例
- 重要业务约束
这样模型才能生成更接近真实业务语义的 SQL。
八、浏览器自动化工具
浏览器工具适合处理普通 HTTP 请求不方便完成的任务,例如:
- 页面内容由 JavaScript 渲染
- 需要截图
- 需要等待某个元素加载
- 需要点击按钮或填写表单
Go 里可以使用 chromedp 实现浏览器自动化。
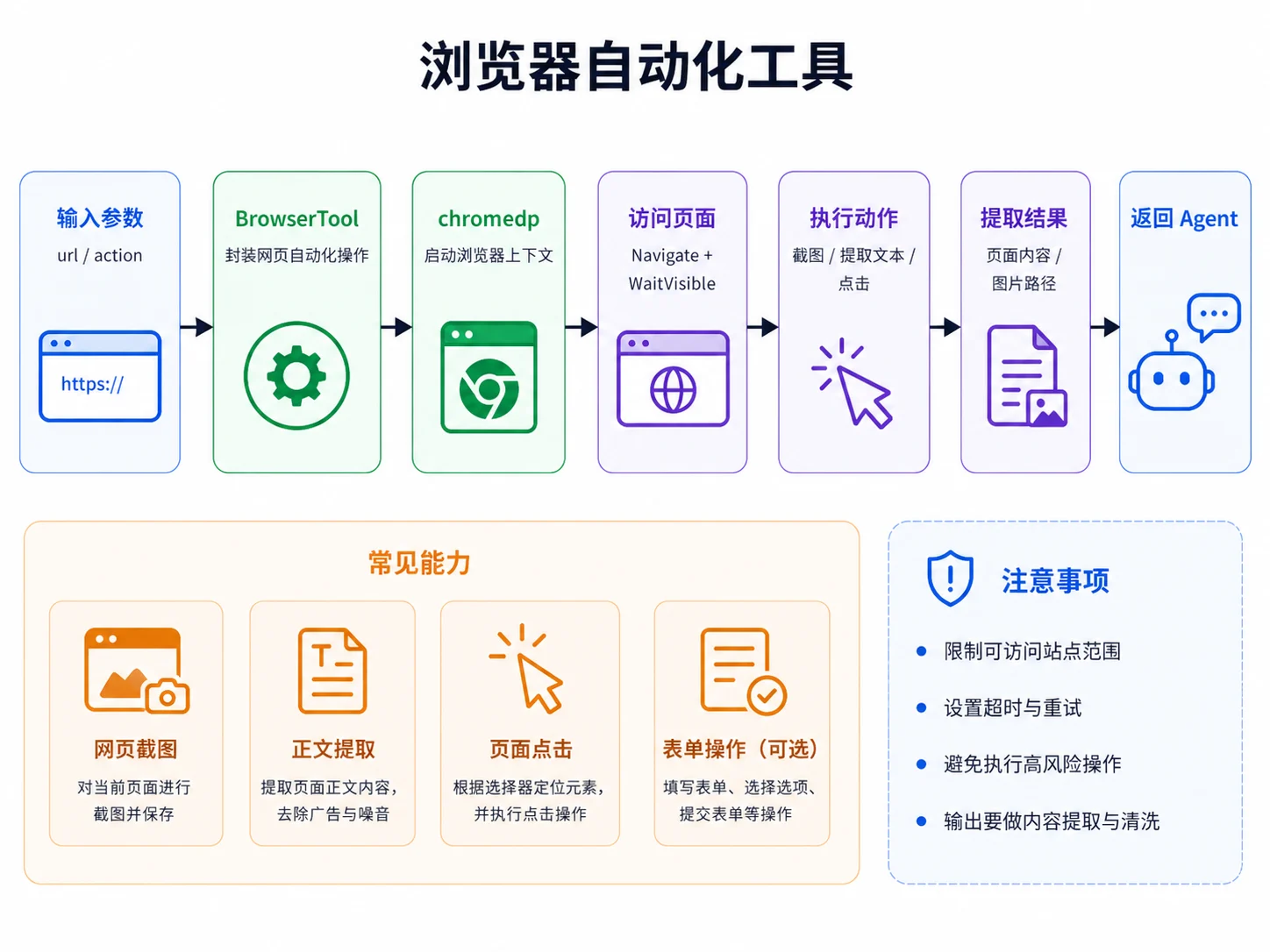
一个基础结构如下:
type BrowserTool struct {
allocCtx context.Context
}执行逻辑示例:
func (t *BrowserTool) Execute(ctx context.Context, input json.RawMessage) (string, error) {
var params struct {
URL string `json:"url"`
Action string `json:"action"`
}
if err := json.Unmarshal(input, ¶ms); err != nil {
return "", err
}
taskCtx, cancel := chromedp.NewContext(t.allocCtx)
defer cancel()
var html string
err := chromedp.Run(taskCtx,
chromedp.Navigate(params.URL),
chromedp.WaitVisible("body"),
chromedp.InnerHTML("body", &html, chromedp.ByQuery),
)
if err != nil {
return "", err
}
return extractMainContent(html), nil
}在课程中,这一节重点是理解浏览器工具的位置,不需要一开始就做复杂的点击和表单自动化。
真实项目中,浏览器工具同样需要限制:
- 允许访问的域名
- 单次任务超时
- 截图尺寸
- 下载行为
- 页面跳转次数
- 是否允许登录态
九、本章实战:数据分析 Agent
本章的最终项目是一个数据分析 Agent。
它要把前面实现的工具组合起来,完成一个典型的数据分析任务:读取数据、理解结构、编写分析代码、执行代码、生成图表、总结结果。
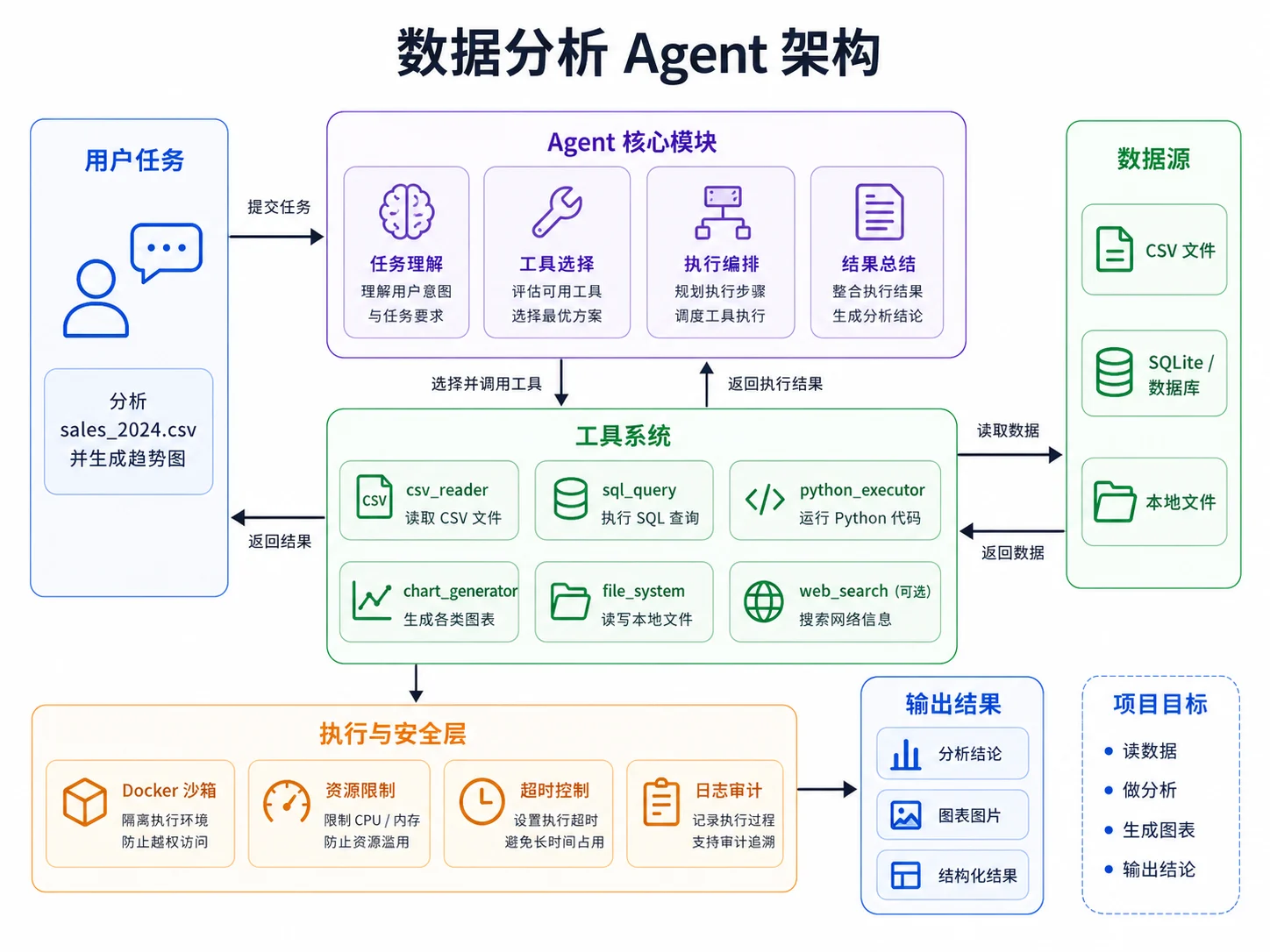
一个最小工具集可以包括:
csv_reader:读取 CSV 文件,返回列名、样例行和基本统计信息sql_query:对 SQLite 或内存数据库执行只读 SQLpython_executor:执行 pandas / matplotlib 分析代码chart_generator:生成图表文件
一次典型执行过程如下:
User: 分析 sales_2024.csv 中各季度的销售趋势,并生成折线图
Thought: 需要先读取 CSV 文件了解数据结构
Action: csv_reader
Action Input: {"file":"sales_2024.csv","rows":5}
Observation: 列: date, product, revenue, quantity,共 1200 行
Thought: 编写 Python 代码进行季度聚合和绘图
Action: python_executor
Action Input: {"code":"import pandas as pd\n..."}
Observation: 图表已保存至 chart.png,Q1:128万, Q2:156万, Q3:189万, Q4:210万
Final Answer: 2024 年销售呈持续增长趋势,全年增长 64%,Q4 表现最佳。图表已生成。这个项目的重点不是把数据分析功能做得多复杂,而是理解 Agent 如何通过多个工具完成一个有实际结果的任务。
1. 数据分析 Agent 的执行链路
一个简单版本可以按照下面的顺序实现:
- 用户输入分析目标和文件路径
- Agent 调用
csv_reader查看数据结构 - Agent 决定使用 SQL 或 Python 继续分析
- 执行分析代码并生成结果
- 如果需要图表,调用图表生成逻辑
- Agent 整理结论并返回用户
2. 项目边界
M04 里的数据分析 Agent 不追求一次做成完整 BI 系统。
建议先把边界控制在:
- 支持 CSV 文件
- 支持 SQLite 只读查询
- 支持 Python pandas 基础分析
- 支持生成本地 PNG 图表
- 支持记录每次工具调用日志
后续再逐步扩展到更多数据源和更复杂的分析流程。
十、工具执行安全原则
工具系统越强,风险也越高。
所以本章最后要强调的是:工具执行必须默认不信任模型输出。
建议至少遵守下面几个原则。
1. 最小权限
每个工具只拥有完成任务所需的最小权限。
例如:
- 文件工具只允许访问指定工作目录
- 数据库工具默认只允许
SELECT - 代码执行工具默认无网络权限
- 浏览器工具默认限制可访问域名
2. 输入验证
所有工具参数都要在执行前验证。
JSON Schema 可以帮助模型生成结构化参数,但不能替代服务端校验。
3. 资源限制
工具执行必须限制资源使用。
常见限制包括:
- 超时时间
- 最大输出长度
- CPU 使用
- 内存使用
- 文件大小
- 网络访问范围
4. 审计日志
工具调用应该记录日志。
至少记录:
- 调用时间
- 工具名称
- 输入参数摘要
- 执行耗时
- 是否成功
- 错误信息
这样后续排查问题、评估成本和审计风险时才有依据。
5. 失败安全
工具失败不应该直接导致整个系统崩溃。
更合理的方式是:
- 把错误包装成 Observation 返回给 Agent
- 让 Agent 决定是否重试
- 达到重试上限后返回可理解的错误信息
- 记录失败上下文,便于后续分析
本章小结
这一章我们把 Agent 的工具系统完整串了一遍。
从架构上看,工具系统至少包含四层:
- 统一工具接口
- 工具注册表
- 工具参数 Schema
- 工具执行治理
从工具类型上看,本章覆盖了几类常见能力:
- Web 搜索与 HTTP 请求
- 代码执行
- 数据库查询
- 浏览器自动化
- 文件和数据分析工具
从工程实践上看,工具系统最重要的不是“功能多”,而是“边界清楚”。
工具越多,Agent 越容易接近真实业务;约束越清楚,系统越容易稳定运行。
课后练习
必做练习
- 实现一个
FileSystemTool,支持读取指定目录下的文件,并阻止路径越界。 - 实现一个
WebSearchTool,接入 Tavily 或其他搜索 API,并为搜索结果增加简单缓存。 - 实现一个
ToolRegistry,支持工具注册、查询、执行和调用日志记录。 - 为工具输入增加 JSON 校验,至少覆盖缺少必填字段和字段类型错误两类情况。
进阶练习
- 基于 Docker 实现一个最小 Python 代码执行沙箱,限制内存、CPU、网络和超时时间。
- 实现一个只读 SQLite 查询工具,要求禁止非
SELECTSQL。 - 完成数据分析 Agent,支持读取 CSV 文件、执行 pandas 分析并生成图表。
- 为每次工具调用增加审计日志,并输出一份 JSON 格式执行报告。
参考资料
- Go 官方文档:
net/http - Go 官方文档:
database/sql - Go 官方文档:
context - Docker SDK for Go
- chromedp 项目文档
- JSON Schema 规范