M03 Agent 核心架构设计
从这一章开始,这套课程才真正进入 Agent 本身。
前两章已经分别把工程基础和 LLM 调用层准备好了。到这里,我们要开始回答一个更关键的问题:什么样的程序,才能算是一个真正的 Agent?
如果只是把用户输入直接发给模型,再把模型输出返回给用户,这更像是一个普通的聊天程序。Agent 的区别在于,它不是一次性的调用,而是一个持续推进目标的运行循环。它会根据当前目标、历史步骤和工具返回结果,决定下一步该做什么;必要时还会修正策略、重试或者结束任务。
所以,M03 的重点不是“换一种 Prompt 写法”,而是把 Agent 当作一个完整的运行系统来设计。
学习目标
完成本章后,你应该能够:
- 理解 Agent Loop 的基本结构和运行方式
- 能够实现一个最小可用的 ReAct Agent
- 理解 Function Calling / Tool Use 的处理流程
- 理解 Plan-and-Execute 的适用场景与基本实现方式
- 为 Agent 增加最大步骤限制、状态记录和错误恢复机制
- 完成一个带会话历史和工具调用的命令行 AI 助手
本章内容
- 什么是 Agent Loop,为什么 Agent 不是一次性的 LLM 调用
- 如何定义 Agent 的状态、步骤和统一接口
- 如何实现 ReAct 模式
- 如何处理 Function Calling / Tool Use
- 如何实现 Plan-and-Execute 两阶段执行架构
- 如何为 Agent 设计状态机、最大步骤限制和错误恢复
- 如何把这些能力整合成一个命令行 AI 助手
一、什么是 Agent Loop
Agent 的核心不是“会调用工具”,而是“会在一个循环中持续推进任务”。
一个最基础的 Agent Loop 通常包括下面几个阶段:
- 接收用户目标
- 根据目标、历史步骤和工具描述构建提示词
- 调用 LLM,让模型给出下一步决策
- 如果模型要求调用工具,就执行工具并得到 Observation
- 把新的 Observation 加回上下文,继续下一轮决策
- 如果模型已经能够给出最终答案,则结束循环
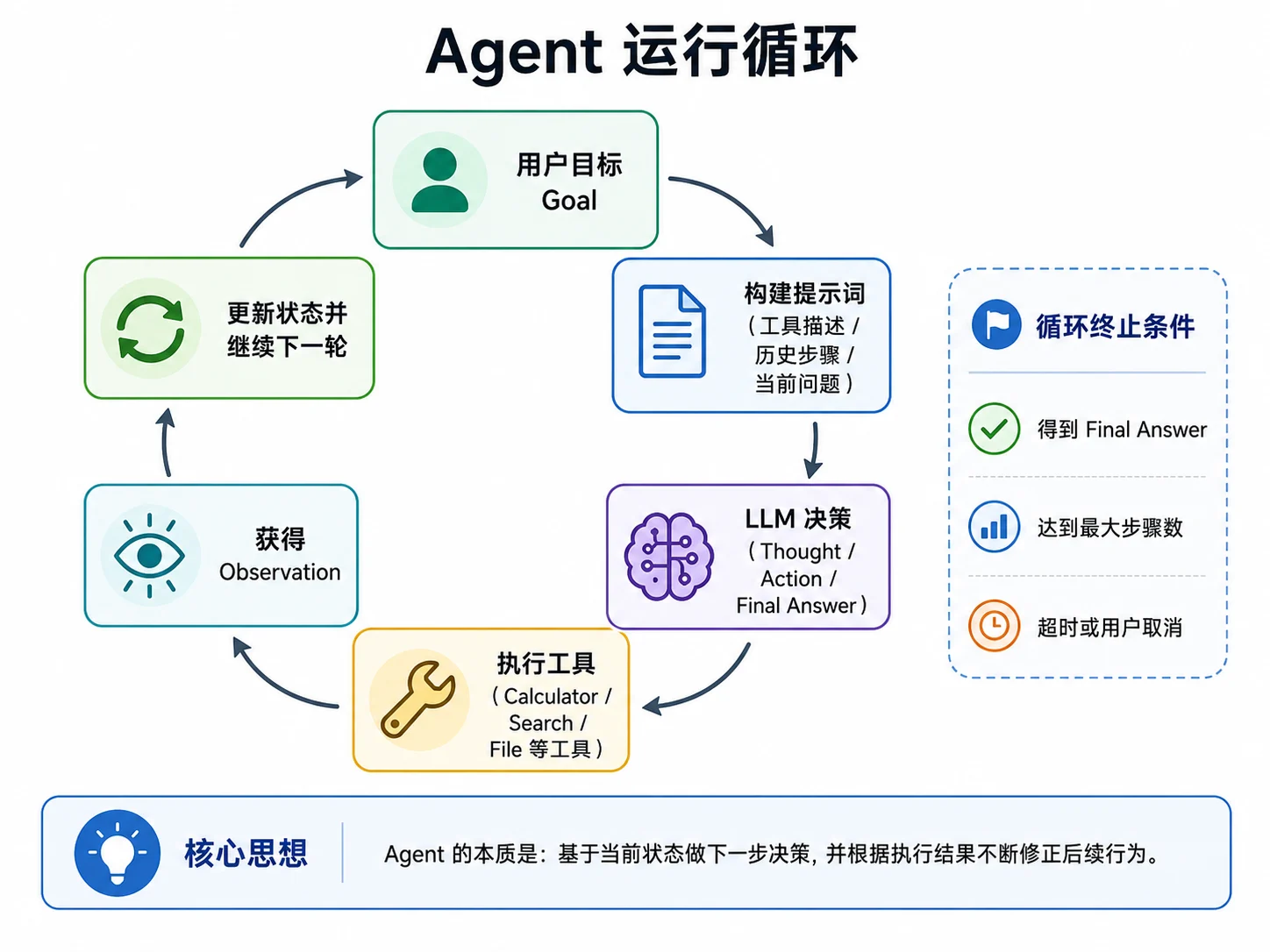
这个过程和普通聊天接口最大的区别是:模型不再只负责“回答问题”,而是参与到一个持续运行的任务闭环中。
1. 为什么需要循环
很多任务并不能通过一次模型调用直接完成。
例如,用户问“帮我总结这个目录下最近修改过的 Go 文件并说明每个文件大概做什么”。如果没有循环,模型只能在不知道真实文件内容的情况下猜测;而在 Agent 模式下,模型可以先决定读取文件列表,再读取部分文件内容,最后组织结果返回。
也就是说,Agent 的价值不只是“会输出答案”,而是“会通过中间动作获取额外信息”。
2. 循环不等于无限循环
一旦把程序设计成循环,就必须控制退出条件。
常见的退出条件包括:
- 模型已经输出最终答案
- 达到最大步骤数
- 上下文超时
- 工具调用连续失败
- 任务已经无法推进
如果没有这些约束,Agent 很容易在错误的路径上持续打转。
二、统一 Agent 状态与接口
要实现一个可以持续运行的 Agent,第一步通常不是先写 Prompt,而是先定义状态结构。
因为从工程视角看,Agent 运行的每一步都应该是可记录、可观测、可恢复的。
先看一个基础版本的状态结构:
type AgentState struct {
Goal string
Steps []Step
FinalAnswer string
StartTime time.Time
}
type Step struct {
Thought string
Action Action
Observation string
Error error
Duration time.Duration
}
type Action struct {
Tool string
Input json.RawMessage
}这套结构最重要的作用,是把“模型思考了什么、调用了什么工具、工具返回了什么结果、这一步有没有出错”全部保存下来。
如果没有这层状态,后面做错误恢复、调试日志、会话持久化、可视化展示都会很困难。
1. 对上层暴露统一接口
和前一章的 LLMProvider 一样,Agent 本身也应该有统一接口。
type Agent interface {
Run(ctx context.Context, goal string) (string, error)
RunStream(ctx context.Context, goal string) (<-chan AgentEvent, error)
}这样做有两个好处:
- 上层调用方不需要关心底层到底是 ReAct 还是 Plan-and-Execute
- 后面增加流式事件输出、命令行交互、Web 界面时,可以复用同一套核心逻辑
2. 状态结构要为后续扩展留空间
一开始的状态结构不需要设计得很复杂,但至少要能支持后续扩展。
例如,后面你大概率会继续往状态里加入:
- 当前步骤编号
- 重试次数
- 反思内容
- 会话 ID
- 工具调用轨迹
- 中间成本统计
因此,这一层更像是 Agent 的“运行记录”,不是单纯的数据临时变量。
三、ReAct:最常见的一类 Agent 模式
ReAct 可以理解成目前最容易上手的一种 Agent 设计方式。
它的核心思路是:让模型在同一轮输出中同时给出“当前判断”和“下一步行动”,然后由程序解析出行动部分,执行对应工具,再把结果反馈给模型。
它适合下面这类场景:
- 每一步只需要调用一个工具
- 任务可以边做边看,不需要提前制定完整计划
- 希望快速实现一个可工作的 Agent 原型
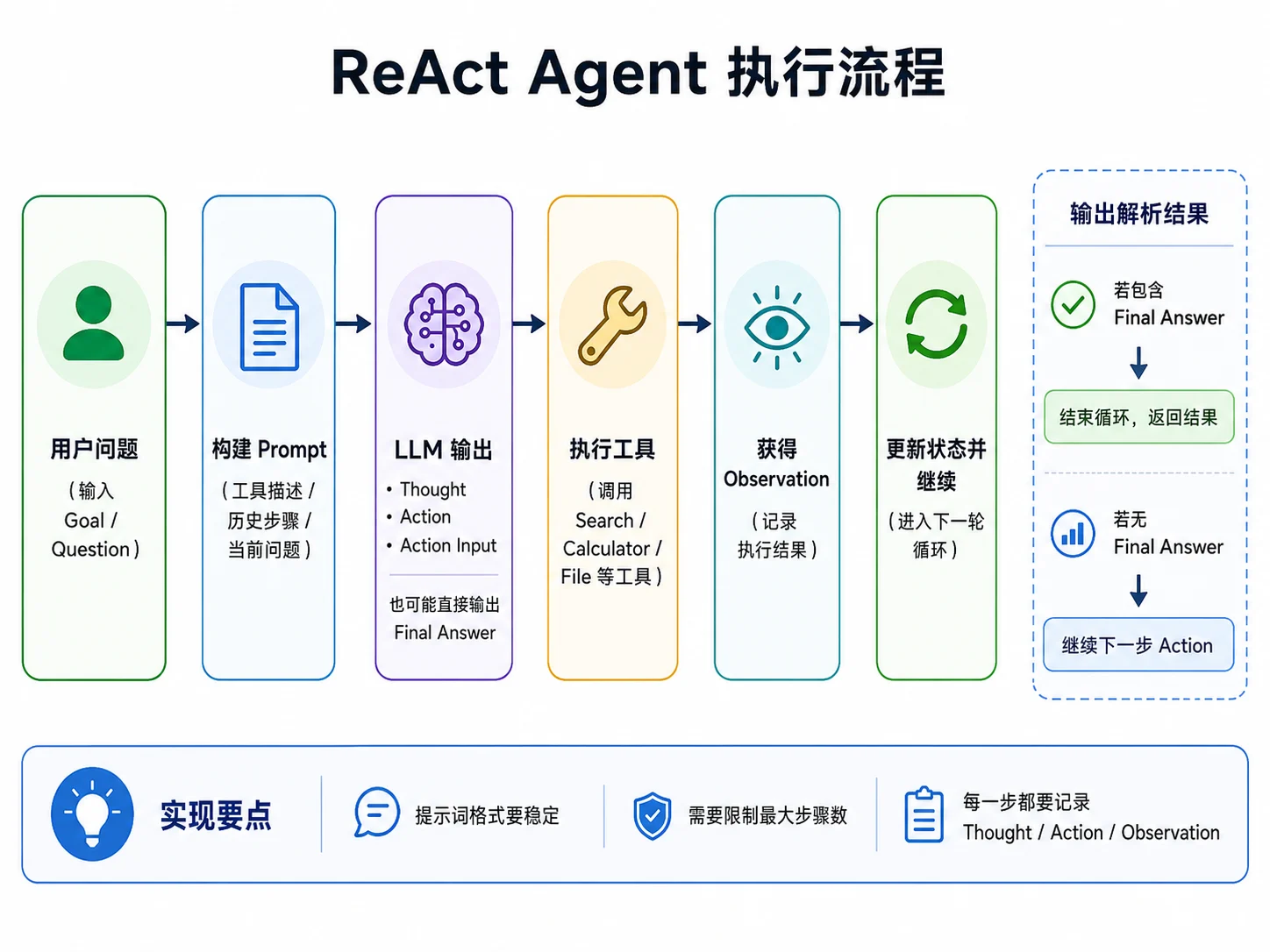
1. ReAct Prompt 的基本形式
先看一个典型的 ReAct 系统提示词:
You are a helpful AI assistant.
You have access to the following tools:
{{range .Tools}}
Tool: {{.Name}}
Description: {{.Description}}
Input Schema: {{.Schema}}
{{end}}
To answer the user's question, you must follow this format EXACTLY:
Thought: [your reasoning about what to do next]
Action: [tool name]
Action Input: [JSON input for the tool]
After receiving a tool result (Observation), you can:
- Continue with another Thought/Action/Action Input cycle
- OR provide the final answer using:
Final Answer: [your answer to the user]这里最关键的,不是 Prompt 文案有多华丽,而是输出格式足够明确。因为如果格式不稳定,后面的解析就会变得非常脆弱。
2. 解析模型输出
如果使用文本式 ReAct,那么程序需要负责从模型返回文本中提取出 Thought、Action 和 Action Input。
type LLMOutput struct {
Thought string
Action string
ActionInput string
FinalAnswer string
IsFinal bool
}
func ParseReActOutput(text string) LLMOutput {
var out LLMOutput
if idx := strings.Index(text, "Final Answer:"); idx != -1 {
out.FinalAnswer = strings.TrimSpace(text[idx+len("Final Answer:"):])
out.IsFinal = true
return out
}
if m := thoughtRe.FindStringSubmatch(text); len(m) > 1 {
out.Thought = m[1]
}
if m := actionRe.FindStringSubmatch(text); len(m) > 1 {
out.Action = m[1]
}
if m := inputRe.FindStringSubmatch(text); len(m) > 1 {
out.ActionInput = m[1]
}
return out
}这类解析在课程里有必要掌握,因为它能帮助你真正理解 Agent Loop 的运行方式。但在生产环境里,这种做法也有明显局限:它很依赖模型是否老老实实遵守格式。
3. 把 ReAct 跑起来
下面是一段最小可用的运行循环:
func (a *ReactAgent) Run(ctx context.Context, goal string) (string, error) {
state := &AgentState{Goal: goal, StartTime: time.Now()}
for i := 0; i < a.maxSteps; i++ {
prompt := a.promptBuilder.BuildReActPrompt(state)
resp, err := a.llm.Complete(ctx, CompletionRequest{
Model: a.model,
Messages: []Message{{Role: "user", Content: prompt}},
})
if err != nil {
return "", fmt.Errorf("step %d: %w", i, err)
}
output := ParseReActOutput(resp.Content)
if output.IsFinal {
return output.FinalAnswer, nil
}
obs, toolErr := a.tools.Execute(ctx, output.Action, []byte(output.ActionInput))
step := Step{
Thought: output.Thought,
Action: Action{Tool: output.Action},
Observation: obs,
Error: toolErr,
}
state.Steps = append(state.Steps, step)
}
return "", ErrMaxStepsReached
}这个版本已经能说明 ReAct 的核心机制:模型决定下一步动作,程序执行动作,再把结果回灌进状态中。
四、Function Calling / Tool Use
文本式 ReAct 适合理解原理,但只要模型稍微不按格式输出,整个解析链就会变得很脆弱。
因此,在很多实际项目里,更稳妥的做法是直接使用模型厂商提供的 Function Calling 或 Tool Use 机制。
这类机制的本质是:让模型不要再用普通文本描述“我要调用哪个工具”,而是通过结构化字段把工具名和参数直接返回给程序。
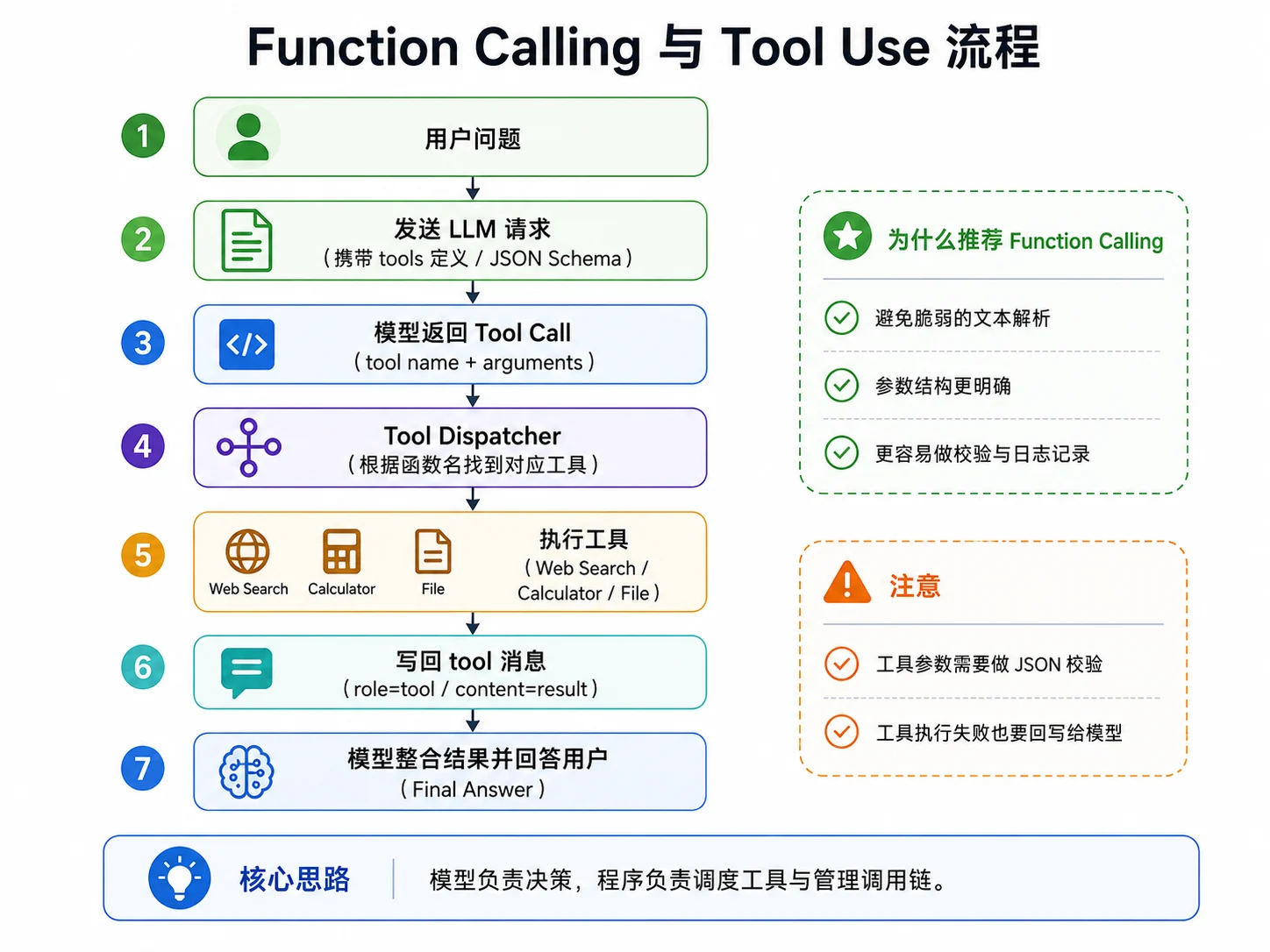
1. 工具描述本质上是协议
先看一个工具定义结构:
type ToolDefinition struct {
Type string `json:"type"`
Function FunctionDef `json:"function"`
}
type FunctionDef struct {
Name string `json:"name"`
Description string `json:"description"`
Parameters json.RawMessage `json:"parameters"`
}这里的重点是:工具描述不是给开发者看的注释,而是给模型看的“调用协议”。
模型需要通过这份协议知道:
- 有哪些工具可以用
- 每个工具是干什么的
- 需要什么参数
- 参数应该长什么样
因此,工具名、描述和 JSON Schema 都应该写得足够清楚。
2. 程序调用工具
Function Calling 不是“模型自己完成工具调用”,而是“模型告诉你它想调用什么工具”,真正的执行仍然由程序完成。
func (a *FunctionCallingAgent) processToolCalls(ctx context.Context, calls []ToolCall) ([]Message, error) {
var results []Message
for _, call := range calls {
result, err := a.tools.Execute(ctx, call.Function.Name, []byte(call.Function.Arguments))
resultStr := result
if err != nil {
resultStr = "Error: " + err.Error()
}
results = append(results, Message{
Role: "tool",
Content: resultStr,
ToolCallID: call.ID,
})
}
return results, nil
}程序在这里的职责通常包括:
- 校验参数
- 调用真实工具
- 处理执行失败
- 把结果以规范消息格式返回给模型
3. 使用结构化字段保存输入/输出
因为结构化字段比自由文本更容易被程序稳定处理。
你不需要再用正则表达式去猜“这一段是不是 Action Input”,而是直接从明确的字段中拿到工具名和参数。这会让整个 Agent 执行链稳定很多。
五、Plan-and-Execute:把复杂任务拆开处理
ReAct 的优点是简单直接,但它更适合“边想边做”的任务。
如果用户目标比较复杂,需要先拆解任务、分析依赖关系,再分批执行,那么 Plan-and-Execute 通常更合适。
这类架构的核心是把流程拆成两个阶段:
- Planner 负责生成计划
- Executor 负责按计划执行每个步骤
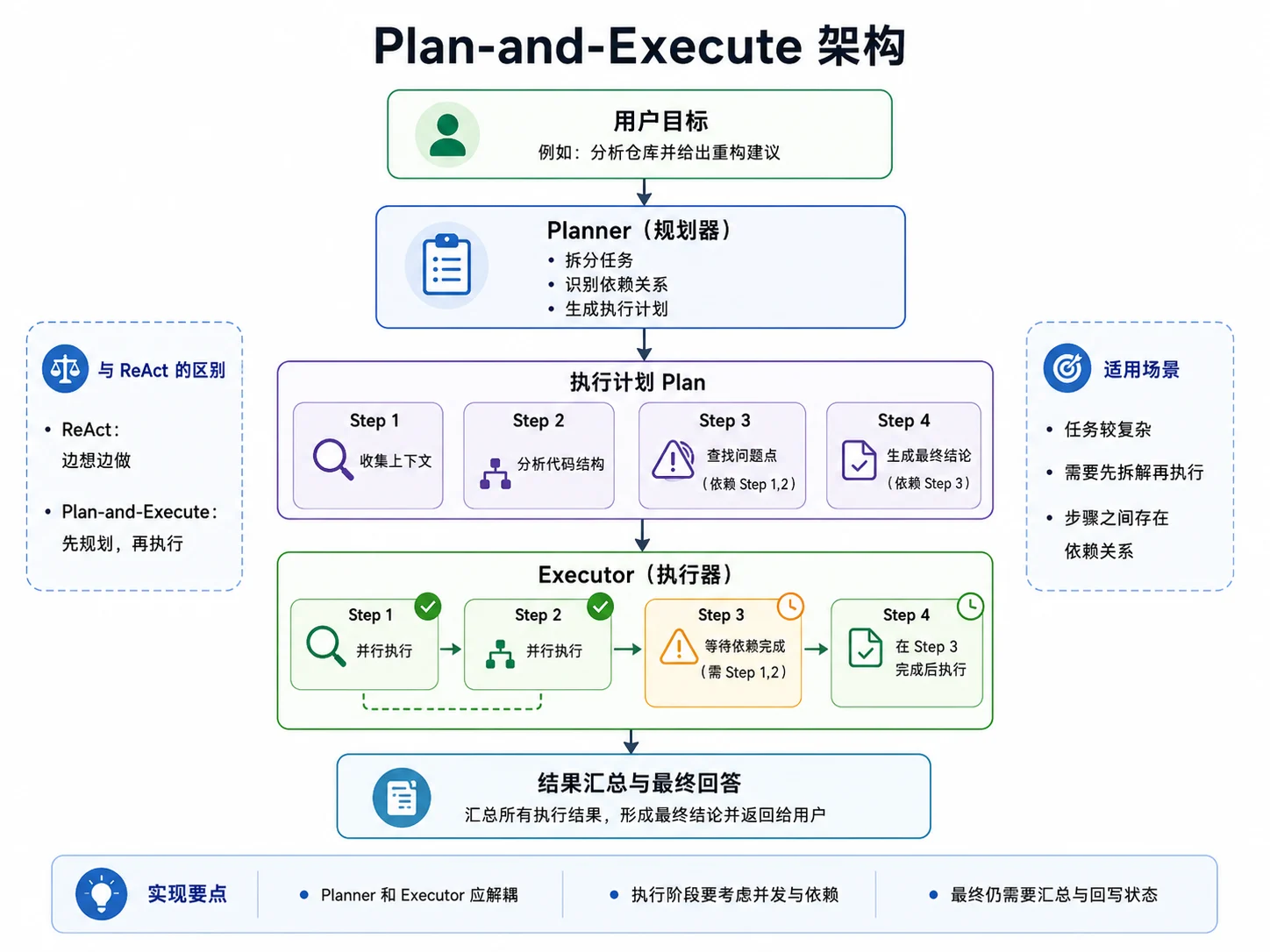
1. 先定义计划结构
type Plan struct {
Steps []PlanStep
}
type PlanStep struct {
ID int
Task string
DependsOn []int
Result string
Done bool
}和 ReAct 相比,这里的区别在于:Agent 在真正执行之前,先把“要做哪些步骤、步骤之间的依赖关系是什么”描述清楚。
2. 计划和执行拆开
type PlanAndExecuteAgent struct {
planner Planner
executor Executor
}
func (a *PlanAndExecuteAgent) Run(ctx context.Context, goal string) (string, error) {
plan, err := a.planner.Plan(ctx, goal)
if err != nil {
return "", err
}
return a.executePlan(ctx, plan)
}这样的拆分有一个明显好处:你可以单独替换 Planner,也可以单独优化 Executor,而不需要把所有逻辑揉在一起。
3. 对无依赖步骤做并发执行
func (a *PlanAndExecuteAgent) executePlan(ctx context.Context, plan *Plan) (string, error) {
completed := make(map[int]string)
var mu sync.Mutex
for _, batch := range topologicalBatches(plan) {
var wg sync.WaitGroup
for _, step := range batch {
wg.Add(1)
go func(s PlanStep) {
defer wg.Done()
result, _ := a.executor.Execute(ctx, s, completed)
mu.Lock()
completed[s.ID] = result
mu.Unlock()
}(step)
}
wg.Wait()
}
return a.synthesize(ctx, completed)
}这里体现出来的,就是 M01 里讲过的并发能力在 Agent 架构里的实际应用。
如果两个步骤之间没有依赖关系,那么它们就可以并发执行。这样在多工具场景下,整体吞吐通常会更高。
4. 适用场景
Plan-and-Execute 通常适合:
- 目标复杂,需要先拆解再执行
- 中间步骤之间存在明确依赖
- 需要控制执行顺序或并发批次
- 希望保留完整计划用于审计或回放
相应地,它的实现和调试成本也比 ReAct 更高。
六、状态管理、最大步骤限制与错误恢复
只要 Agent 开始执行多轮循环,状态管理就会成为核心问题。
因为这时你面对的不是“某一次调用是否成功”,而是“一个持续运行的任务是否还能继续推进”。
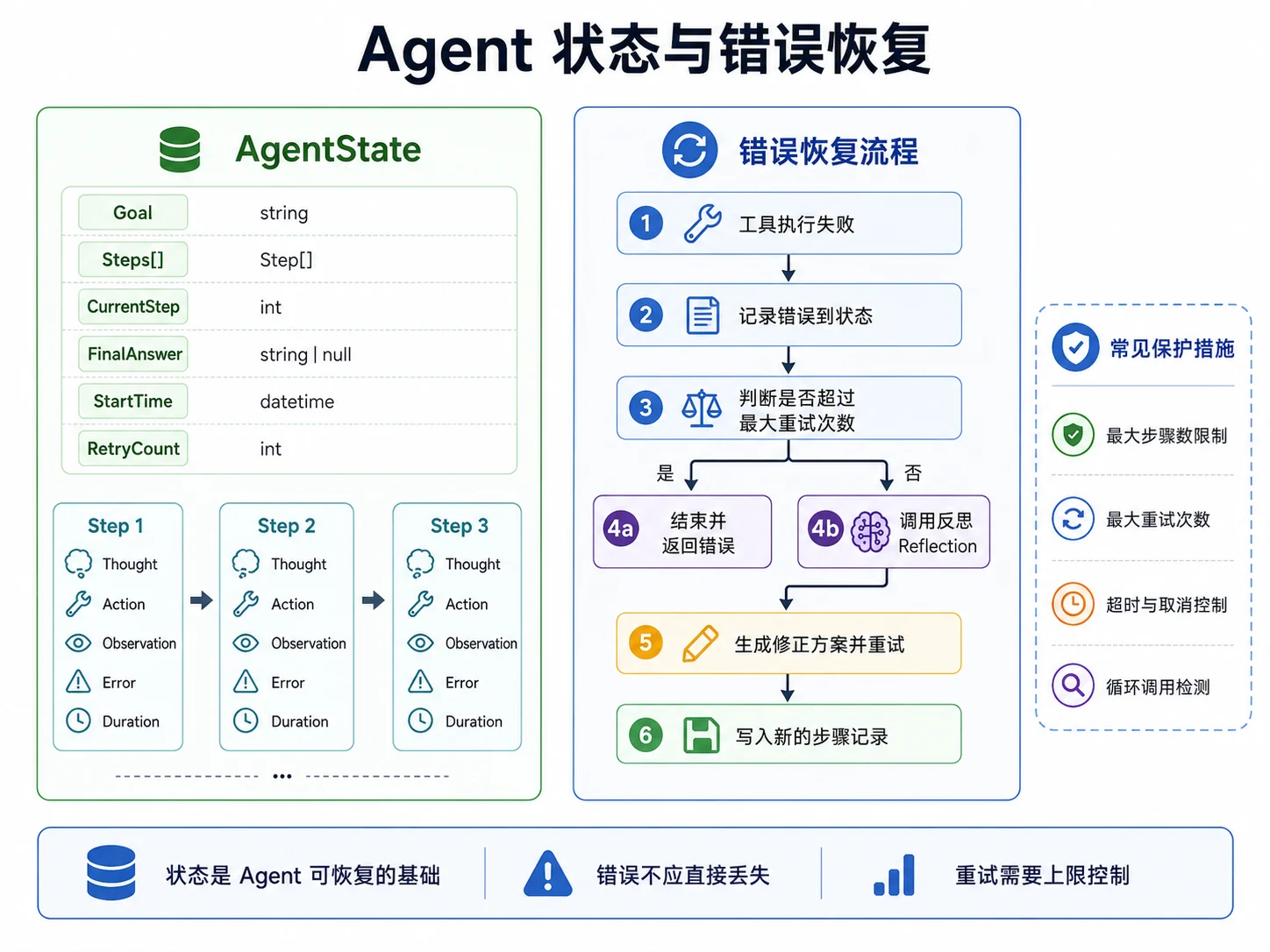
1. 先限制最大步骤数
最大步骤数限制是最基本、也是最必要的一层保护。
如果没有这层限制,Agent 可能会在错误路径上反复调用同一个工具,或者不断生成没有实际进展的中间步骤。
for i := 0; i < a.maxSteps; i++ {
// do agent loop
}
return "", ErrMaxStepsReached这不是“保守”,而是防止系统进入不可控状态。
2. 记录每一步的结果和错误
只要某一步失败,就应该把失败信息写回状态,而不是简单 return err 就结束。
因为很多失败并不一定意味着整个任务彻底终止。模型有时候可以基于错误信息重新选择工具、修正参数,或者改走另一条路径。
3. 给 Agent 一次反思和修正的机会
func (a *ReactAgent) handleToolError(ctx context.Context, state *AgentState, step Step, err error) (string, bool) {
if step.RetryCount >= a.maxRetries {
return "", false
}
reflection := a.reflect(ctx, state, err)
state.AddReflection(reflection)
return reflection, true
}这里的思路很简单:当工具执行失败后,不是立刻放弃,而是把错误描述重新交给模型,让模型决定是否调整参数、换工具或者换路径。
这种“反思后再继续”的模式,并不能保证所有错误都能恢复,但它能让 Agent 在一部分场景下表现得更稳。
七、本章实战:命令行 AI 助手
这一章的实践项目,是把前面的 Agent 循环、工具调用、状态管理和流式输出真正整合起来,做成一个命令行 AI 助手。
这个项目的目标不是做一个功能巨大的产品,而是把 Agent 的核心机制完整跑通。
1. 基本功能
这个命令行工具至少应该支持:
- 多轮对话
- 会话历史
- 内置工具调用
- 流式输出
- 元命令
- 本地持久化
2. 一个最小可用的主程序入口
func main() {
agent := NewCLIAgent(
WithLLM(openai.New(os.Getenv("OPENAI_API_KEY"))),
WithTools(NewFileTools(), NewShellTool()),
WithHistory(LoadHistory(".agent_history")),
)
scanner := bufio.NewScanner(os.Stdin)
for {
fmt.Print("> ")
if !scanner.Scan() {
break
}
input := scanner.Text()
if strings.HasPrefix(input, "/") {
agent.HandleCommand(input)
continue
}
for event := range agent.RunStream(context.Background(), input) {
fmt.Print(event.Content)
}
fmt.Println()
}
}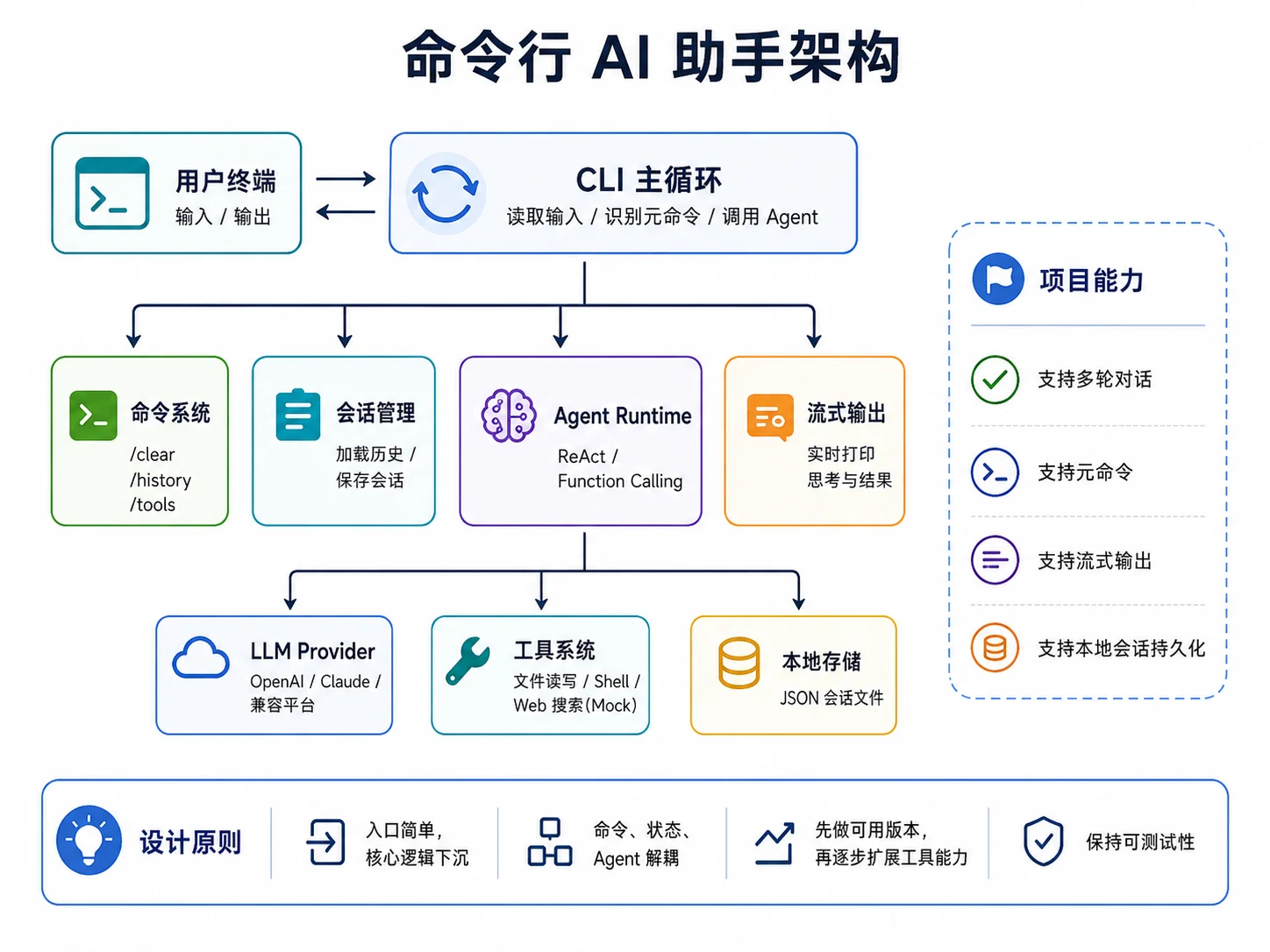
3. 项目目标
表面上看,它只是一个 CLI 工具;但实际上,这个项目把本章最核心的几个能力都串起来了:
- Agent Loop
- 会话状态
- 工具调用
- 流式事件输出
- 本地持久化
- 元命令处理
只要这个项目能稳定跑起来,后面无论你要做 Web 版、SSE 版,还是接入更复杂的工具系统,都只是交互层和能力层的继续扩展。
八、常见问题
1. ReAct 和 Function Calling 应该选哪个
如果你的目标是先把 Agent 原理真正吃透,可以先做一版文本式 ReAct;如果你的目标是做更稳定的实际项目,优先使用 Function Calling / Tool Use。
简单说:ReAct 更适合理解机制,Function Calling 更适合工程落地。
2. Agent 为什么会反复调用同一个工具
常见原因包括:
- Prompt 中没有明确的终止条件
- 工具返回结果信息不足
- 模型没有判断出任务已经完成
- 没有限制最大步骤数
因此,不要把“停止”这件事完全交给模型自己决定,程序层也必须有硬约束。
3. Plan-and-Execute 一定比 ReAct 更高级吗
不一定。
它适合复杂任务,但并不意味着所有任务都应该先做计划。很多简单任务,用 ReAct 已经足够;强行上 Plan-and-Execute 只会增加实现复杂度和调试成本。
九、小结
这一章真正建立起来的,不是某一个具体 Prompt,也不是某个工具调用细节,而是 Agent 的整体运行观。
到这里,你应该已经能把一个 Agent 看成这样一套系统:
- 有明确的输入目标
- 有持续推进任务的运行循环
- 有可执行的工具系统
- 有状态记录和历史步骤
- 有最大步骤、超时和错误恢复等保护机制
后面的工具系统、记忆系统和多智能体协作,本质上都是在这套骨架上继续加能力。
课后练习
必做练习
- 实现一个最小可用的 ReAct Agent,内置
calculator和echo两个工具。 - 为 ReAct Agent 增加最大步骤数限制和整体超时控制。
- 用
RunStream形式输出 Agent 运行事件,在命令行中实时展示中间过程。
选做练习
- 给 Agent 增加步骤去重检测,避免反复调用同一个工具。
- 实现一个简单的 Planner,把复杂任务拆成多个子步骤后再执行。
- 为命令行 AI 助手增加
/clear、/history、/tools三个元命令。
参考资料
- ReAct: Synergizing Reasoning and Acting in Language Models
- OpenAI Function Calling / Tool Calling 相关文档
- Anthropic Tool Use 相关文档
- Go
context、sync、encoding/json标准库文档 - 本课程前两章的项目骨架与 LLM Provider 实现