M02 LLM 全平台接入
在 Agent 系统里,LLM 调用层是后续所有能力的基础。工具调用、记忆系统、RAG、多智能体协作表面上各不相同,但最终都会回到同一个问题:如何稳定、可控地调用模型。
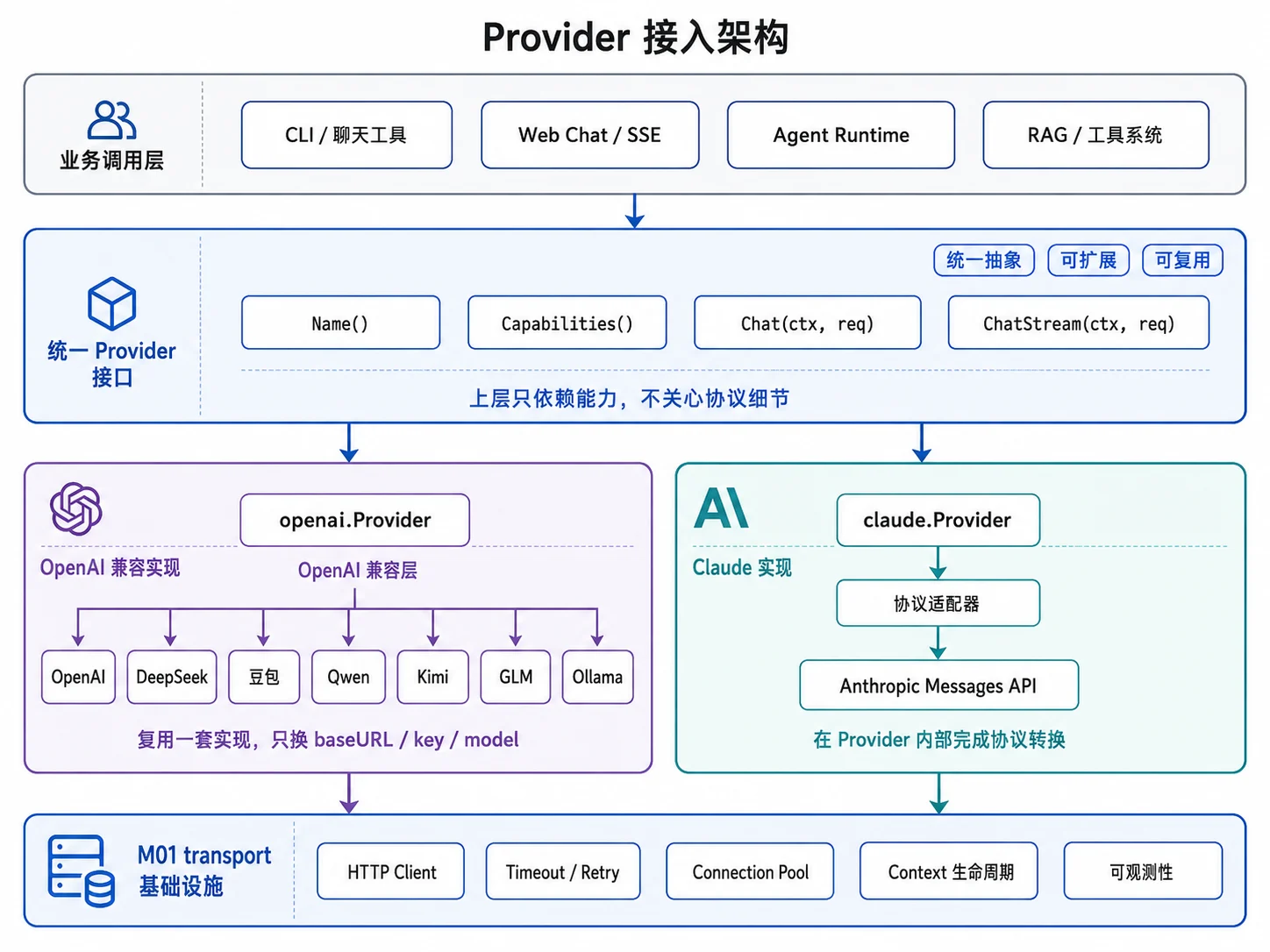
M01 的生产级 HTTP 客户端、Context 生命周期控制和最小 Provider 接口已经准备好了基础设施。本章将在这些基础上,搭出一层可扩展、可复用的模型接入抽象:对外提供统一接口,内部自行兼容各厂商的协议差异。
学习目标
学完本章,你应该能够:
- 定义统一的
Provider接口与请求、响应结构; - 实现一个基于 M01 生产级 HTTP 客户端中
transport的 OpenAI 风格客户端; - 用兼容层复用一套实现接入 DeepSeek、豆包、Kimi、Qwen、GLM 等平台;
- 用适配器接入 Claude 这类非 OpenAI 兼容平台;
- 处理流式输出,自动生成 JSON Schema,并计量 token 与成本;
- 用 Provider 工厂和路由网关把多个模型组织成可降级的系统能力。
前置要求是完成 M01 Go 语言 AI 开发基础,并准备至少一个可用的 OpenAI 兼容 API Key。配套练习是 llmrouter:一个命令行工具,可以配置多个 Provider,自动故障转移,并在回答后打印“由谁回答、消耗 token、估算成本”。
transport 之上。为聚焦设计,部分重复的请求和解析样板会用注释省略;完整可运行版本需要在配套练习中补齐。2.1 LLM API 协议家族
在开始编写具体代码之前,先了解一下目前市面上主流厂商的 LLM API。OpenAI、Anthropic、Gemini 三家协议在端点结构、消息格式、流式事件和工具调用上都有根本差异。理解了这些协议层的差异,后面对接 OpenAI 兼容平台、Claude、Ollama 时,才知道哪些地方应该复用,哪些地方必须适配。
为什么需要统一接口
很多项目第一次接 LLM 时,会直接写一段 HTTP 请求,拿到 JSON 后解析。只有一个 Provider 时,这样做没有问题;一旦接入第二家、第三家,代码很快会失控:
- OpenAI、豆包、Qwen 的路径与模型名各不相同;
- Claude 的请求结构与 OpenAI 风格不同;
- Gemini 的
contents、parts、systemInstruction又是另一套表达; - 有的场景要同步返回,有的要流式输出;
- 某家限流或超时时,需要自动切到别家。
没有统一抽象,业务层会塞满 if provider == ... 的分支。LLM 接入层要先把差异收敛到 Provider 内部,让上层只依赖“能不能 Chat、能不能流式、支持哪些能力”。
主流协议对比
截至 2026-06-02,LLM API 主要可以分成三类协议家族:OpenAI 兼容协议、Anthropic Messages 协议、Google Gemini 协议。下面按端点、消息、流式和工具四个维度看差异。
端点结构
| 维度 | OpenAI 兼容 | Anthropic | Google Gemini |
|---|---|---|---|
| Base URL | https://api.openai.com/v1 | https://api.anthropic.com | https://generativelanguage.googleapis.com/v1beta |
| 聊天端点 | /chat/completions | /v1/messages | /models/{model}:generateContent |
| 流式端点 | 同上,设置 stream: true | 同上,设置 stream: true | /models/{model}:streamGenerateContent |
| 鉴权 | Authorization: Bearer {key} | x-api-key: {key} + anthropic-version | x-goog-api-key 或 OAuth2 |
| Embedding | /embeddings | 无独立 embedding 端点 | /models/{model}:embedContent |
仅鉴权方式就有三种写法。OpenAI 兼容协议使用 Bearer token,Anthropic 使用自定义 header 和 API 版本号,Gemini REST 示例常用 x-goog-api-key。
消息格式
请求体里消息历史的结构差异最大。
// OpenAI:messages 数组,system 是一种 role
{
"model": "gpt-5",
"messages": [
{"role": "system", "content": "你是助手"},
{"role": "user", "content": "你好"}
]
}
// Anthropic:system 是顶层字段,messages 只有 user/assistant
{
"model": "claude-sonnet-4-20250514",
"system": "你是助手",
"messages": [
{"role": "user", "content": "你好"}
],
"max_tokens": 1024
}
// Gemini:contents 数组,role 使用 "model",systemInstruction 单独配置
{
"contents": [
{"role": "user", "parts": [{"text": "你好"}]}
],
"systemInstruction": {
"parts": [{"text": "你是助手"}]
}
}几个必须关注的差异点:
system的位置不同。OpenAI 把 system 作为 messages 中的一项;Anthropic 使用顶层system字段;Gemini 使用systemInstruction。- role 命名不同。OpenAI 和 Anthropic 使用
assistant;Gemini 使用model表示模型回复。 - content 形态不同。OpenAI 常见是 string,也支持多模态数组;Anthropic 使用 string 或 content blocks;Gemini 使用
parts数组。 max_tokens要求不同。Anthropic Messages API 要求请求中带max_tokens;OpenAI 兼容协议通常可选。
流式约定
三家都可以走 SSE,但事件结构不同。
OpenAI:
data: {"choices":[{"delta":{"content":"H"}}]}
data: {"choices":[{"delta":{"content":"i"}}]}
data: [DONE]
Anthropic:
event: message_start
data: {"type":"message_start", ...}
event: content_block_delta
data: {"type":"content_block_delta","delta":{"type":"text_delta","text":"H"}}
event: message_stop
data: {"type":"message_stop"}
Gemini:
data: {"candidates":[{"content":{"parts":[{"text":"H"}]}}]}
data: {"candidates":[{"content":{"parts":[{"text":"i"}]}}]}每家的事件名、字段名和结束标记都不同。M01 1.2讲的是如何用 channel 表达流;本章会补真实 SSE 字节流的解析。
工具调用
工具调用会在 M06 6.3 Function Calling 协议完整展开。这里先记住结论:
- OpenAI 使用
tools[].function与tool_calls[] - Anthropic 使用 content block 中的
tool_use/tool_result - Gemini 使用
function_declarations与functionCall。
因此工具调用协议也不能直接暴露给业务层。
综合对比
| 维度 | OpenAI | Anthropic | Gemini |
|---|---|---|---|
| 设计风格 | 平铺、history-driven | content blocks 统一抽象 | Proto 风格、强类型 |
| system 处理 | role=system | 顶层 system 字段 | systemInstruction |
| role 命名 | user / assistant | user / assistant | user / model |
| content | string 或多模态数组 | string 或 content blocks | parts 数组 |
| 流式结束 | data: [DONE] | message_stop 事件 | 通常随 HTTP 流结束 |
| 工具协议 | tools[].function | tools[].input_schema | function_declarations |
| 多模态承载 | content 中的 image_url | content block 中的 image | parts 中的 inline_data |
| 鉴权 | Bearer token | x-api-key + version | API key header 或 OAuth |
| Embedding | /embeddings | 不提供 | embedContent |
OpenAI 兼容协议
国内外很多模型服务都提供 OpenAI 兼容接口。原因很直接:围绕 OpenAI SDK 和 Chat Completions 协议已经形成了大量工具、框架和集成方式。一个平台只要兼容 /chat/completions 的核心请求和响应结构,用户通常只需要改 base_url、API Key 和模型名就能接入。
这带来很大的工程红利:同一协议族的平台,可以复用一套基础实现,只把 baseURL、apiKey 和默认模型名作为配置项。
下面是常见 OpenAI 兼容平台的地址示例。厂商 API 地址会变化,实际项目以官方文档为准。
| 厂商 | OpenAI 兼容 baseURL |
|---|---|
| OpenAI | https://api.openai.com/v1 |
| DeepSeek | https://api.deepseek.com |
| 豆包(火山方舟) | https://ark.cn-beijing.volces.com/api/v3 |
| Qwen(DashScope 兼容模式) | https://dashscope.aliyuncs.com/compatible-mode/v1 |
| Kimi(月之暗面) | https://api.moonshot.cn/v1 |
| GLM(智谱) | https://open.bigmodel.cn/api/paas/v4 |
usage 字段都可能有差异。Provider 接口
三家协议差异这么大,业务代码不能直接绑定某家 JSON 结构。M01 1.4已经起了一个最小 Provider 接口,本章将继续把它完善:上层只关心模型调用能力,具体协议由各 Provider 实现。
package llm
// Provider 是所有大模型供应商的统一抽象。上层只关心能否调用和能否流式,
// 不关心某家把 system 放哪、请求头怎么拼。
type Provider interface {
Name() string
Capabilities() Capability // 声明当前统一接口真正支持的能力,路由时使用
Chat(ctx context.Context, req ChatRequest) (*ChatResponse, error)
ChatStream(ctx context.Context, req ChatRequest) (<-chan StreamChunk, error)
}
// Capability 描述一个 Provider 的能力。
// M02 的统一请求只实现普通对话和流式输出,因此本章 Provider 只把 Streaming 设为 true。
// Thinking、Tools 字段预留给后续章节;统一请求结构尚未补齐前不能提前声明支持。
type Capability struct {
Streaming bool
Thinking bool
Tools bool
}
这里有两个取舍。
第一,Chat 和 ChatStream 一开始都放进接口。终端工具、网页聊天、SSE 转发都需要流式,流式不是可有可无的附加能力。
第二,接口统一的是能力,不是协议细节。工具调用、多模态等能力等真正用到的模块再扩展,不在 M02 一次性做大接口。
为什么不直接用 OpenAI 官方 Go SDK
如果大多数平台都 OpenAI 兼容,为什么不直接使用 OpenAI SDK?
第一,Claude、Gemini、Ollama 等平台并不都能完全用 OpenAI SDK 覆盖。业务层仍然会出现分支。
第二,SDK 调用方式会把具体协议和 SDK 类型暴露给业务代码。以后换 SDK、换协议或接入异构平台时,影响范围会扩大。
第三,项目需要自己的横切能力:M01 的生产级 HTTP 客户端、统一重试和限流、多 Provider 路由、成本统计、观测埋点。这些能力更适合收敛在自己的 Provider 层。
因此,本课程自己写一个薄的抽象层。Provider 内部可以复用 SDK 或手写 HTTP,但业务层只依赖 llm.Provider。
2.2 统一请求与响应结构
为了让多个 Provider 复用同一套上层逻辑,需要一套项目内部统一的请求和响应结构。它不必和某家协议完全一致,只要能表达上层真正需要的字段即可。
package llm
type Role string
const (
RoleSystem Role = "system"
RoleUser Role = "user"
RoleAssistant Role = "assistant"
RoleTool Role = "tool"
)
type Message struct {
Role Role `json:"role"`
Content string `json:"content"`
}
type ChatRequest struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Temperature *float64 `json:"temperature,omitempty"`
MaxTokens int `json:"max_tokens,omitempty"`
Stream bool `json:"stream,omitempty"`
}
type ChatResponse struct {
Content string
InputTokens int
OutputTokens int
}接入不同平台时,再把这套结构复用或转换成各家真正的请求体。OpenAI 兼容协议和它基本同形,可以直接序列化;Anthropic 和 Gemini 则需要适配器。
Temperature 使用指针,是为了区分“没有设置”与“显式设置为 0”。如果使用 float64 配合 omitempty,合法值 0 会被当成空值省略,服务端实际收到的是自己的默认温度。RoleTool 先保留给后续章节扩展,但 M02 的 Provider 在尚未具备工具调用 ID 和 content block 等字段时,必须拒绝它,不能直接发给上游。
NewChatRequest 使用函数式选项模式,保持调用简洁的同时能向后兼容,避免字段一多就难用。
func NewChatRequest(model string, messages []Message, opts ...Option) ChatRequest {
req := ChatRequest{Model: model, Messages: messages}
for _, opt := range opts {
opt(&req)
}
return req
}
type Option func(*ChatRequest)
func WithTemperature(t float64) Option {
return func(r *ChatRequest) { r.Temperature = &t }
}
func WithMaxTokens(n int) Option {
return func(r *ChatRequest) { r.MaxTokens = n }
}这部分只负责“消息发出去、结果收回来”。如何把消息写好、组织 few-shot 和约束结构化输出,见 M03 3.2 Prompt 编写方法。
2.3 OpenAI 风格客户端
OpenAI 风格接口是行业事实标准,适合作为第一版统一实现。
客户端本身保持很薄,连接池、超时、重试和退避由 M01 1.5的 transport.Client 负责。
package openai
type Provider struct {
name string
baseURL string
apiKey string
client *transport.Client // M01 的生产级客户端
}
// Config 收拢 Provider 构造参数。
// 三个字段都是 string,如果用位置参数容易把 baseURL 和 apiKey 写反。
type Config struct {
Name string // Provider 标识,如 "deepseek"
BaseURL string // 形如 https://api.deepseek.com
APIKey string
}
// New 创建一个 OpenAI 兼容 Provider。
func New(cfg Config) *Provider {
return &Provider{
name: cfg.Name,
baseURL: cfg.BaseURL,
apiKey: cfg.APIKey,
client: transport.NewClient(),
}
}
func (p *Provider) Name() string { return p.name }
func (p *Provider) Capabilities() llm.Capability {
return llm.Capability{Streaming: true}
}
func (p *Provider) validateMessages(messages []llm.Message) error {
// M02 的 Message 还不能表达 OpenAI 工具结果要求的 tool_call_id,
// 因此不能把 RoleTool 直接序列化后发给接口。
for _, m := range messages {
if m.Role == llm.RoleTool {
return fmt.Errorf("%s: M02 尚未实现 tool message 协议", p.name)
}
}
return nil
}
func (p *Provider) Chat(ctx context.Context, req llm.ChatRequest) (*llm.ChatResponse, error) {
if err := p.validateMessages(req.Messages); err != nil {
return nil, err
}
body, err := json.Marshal(req) // M06 接工具时会进一步细化请求体
if err != nil {
return nil, fmt.Errorf("%s: 序列化请求: %w", p.name, err)
}
httpReq, err := http.NewRequestWithContext(
ctx,
http.MethodPost,
p.baseURL+"/chat/completions",
bytes.NewReader(body),
)
if err != nil {
return nil, err
}
httpReq.Header.Set("Content-Type", "application/json")
httpReq.Header.Set("Authorization", "Bearer "+p.apiKey)
resp, err := p.client.Do(httpReq)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, fmt.Errorf("%s: %s", p.name, parseAPIError(resp))
}
var out struct {
Choices []struct {
Message struct {
Content string `json:"content"`
} `json:"message"`
} `json:"choices"`
Usage struct {
PromptTokens int `json:"prompt_tokens"`
CompletionTokens int `json:"completion_tokens"`
} `json:"usage"`
}
if err := json.NewDecoder(resp.Body).Decode(&out); err != nil {
return nil, err
}
if len(out.Choices) == 0 {
return nil, fmt.Errorf("%s: 空响应", p.name)
}
return &llm.ChatResponse{
Content: out.Choices[0].Message.Content,
InputTokens: out.Usage.PromptTokens,
OutputTokens: out.Usage.CompletionTokens,
}, nil
}这段代码有三个值得提一下的好习惯。
第一,baseURL 不写死。接入兼容平台时只换配置,不需要复制客户端。
第二,错误处理要尽量完整。网络错误、Key 配错、上下文过长、参数非法、429 限流、5xx 上游异常都需要在错误信息中体现。示例里的 parseAPIError 可以按各家错误体进一步实现。
第三,用 httptest 测客户端。M01 1.7 测试已经演示过“先 429 再成功”的测试方式,本章可以继续扩展成功响应、非法 JSON、空 choices、401/400 错误体等用例。
流式 ChatStream 放到 2.7 节统一处理。
2.4 兼容层复用
接入第二家厂商时,不应该复制一份新客户端代码。国内主流模型服务大多提供 OpenAI 兼容接口,接入它们时不需要重写请求逻辑,只需要复用上面的 openai.Provider,预置不同的 baseURL、apiKey 和名称。
package openai
// 复用第三节的 Provider,只是预置各家的 baseURL。
func NewOpenAI(apiKey string) llm.Provider {
return New(Config{Name: "openai", BaseURL: "https://api.openai.com/v1", APIKey: apiKey})
}
// NewDeepSeek DeepSeek Provider
func NewDeepSeek(apiKey string) llm.Provider {
return New(Config{Name: "deepseek", BaseURL: "https://api.deepseek.com", APIKey: apiKey})
}
// NewDoubao 豆包 Provider
func NewDoubao(apiKey string) llm.Provider {
return New(Config{Name: "doubao", BaseURL: "https://ark.cn-beijing.volces.com/api/v3", APIKey: apiKey})
}
// NewQwen 千问 Provider
func NewQwen(apiKey string) llm.Provider {
return New(Config{Name: "qwen", BaseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1", APIKey: apiKey})
}
// Kimi、GLM 同理:换 baseURL 即可。具体模型名按次通过 ChatRequest.Model 传入。如果某个平台不返回 usage、错误体格式不同、流式字段有扩展,可以单独在小补丁里适配。主路径仍然复用 OpenAI 兼容实现,不要每接一家复制一套客户端。
2.5 Claude 适配器
不是所有平台都适合复用 OpenAI 兼容层。Claude 使用 Anthropic Messages API,和 OpenAI 风格有几处明显差异:
system是顶层字段,不放进messages;max_tokens必填;- 鉴权使用
x-api-key和anthropic-version; - 响应
content是内容块数组,可能包含text块、thinking 块或工具相关块。
更好的做法是保留统一 ChatRequest,在 Claude Provider 内部完成协议转换。
package claude
import "fmt" // 教学骨架 Chat 占位用,真实实现还会引入 context、encoding/json 等
func New(apiKey string) *Provider {
/* baseURL=https://api.anthropic.com/v1,复用 transport */
}
func (p *Provider) Name() string { return "claude" }
func (p *Provider) Capabilities() llm.Capability {
return llm.Capability{Streaming: true}
}
// adaptRequest 把统一的 ChatRequest 翻译成 Anthropic 请求体。
func (p *Provider) adaptRequest(req llm.ChatRequest) (map[string]any, error) {
var system string
msgs := make([]map[string]string, 0, len(req.Messages))
for _, m := range req.Messages {
if m.Role == llm.RoleSystem {
system += m.Content
continue
}
if m.Role != llm.RoleUser && m.Role != llm.RoleAssistant {
return nil, fmt.Errorf("claude: M02 尚未实现 role %q 的协议转换", m.Role)
}
msgs = append(msgs, map[string]string{
"role": string(m.Role),
"content": m.Content,
})
}
maxTokens := req.MaxTokens
if maxTokens == 0 {
maxTokens = 1024 // Anthropic 要求 max_tokens 必填
}
body := map[string]any{
"model": req.Model,
"messages": msgs,
"max_tokens": maxTokens,
}
if system != "" {
body["system"] = system
}
if req.Temperature != nil {
body["temperature"] = *req.Temperature
}
return body, nil
}
func (p *Provider) Chat(ctx context.Context, req llm.ChatRequest) (*llm.ChatResponse, error) {
// 教学骨架,完整实现见配套练习。
// 真实写法:
// 1) body, err := adaptRequest(req),并处理转换错误
// 2) 带 x-api-key / anthropic-version 头通过 p.client.Do 发请求
// 3) 解析 content 块数组,拼接所有 type=="text" 的块
// 4) 用 usage.input_tokens / output_tokens 填 ChatResponse
return nil, fmt.Errorf("anthropic.Provider.Chat: 教学骨架,完整实现见配套练习")
}这段代码的重点是 adaptRequest。上层业务不知道 Claude 把 system 放在哪里,也不知道响应是 content blocks,只需要调用统一的 Chat。
总之,兼容层主要用来复用实现,适配器主要用来转换协议。
Claude 还有两个特性值得提前知道:
- Prompt Caching 可以让稳定前缀命中缓存,M03 3.5会讲如何组织提示词顺序;
- Extended Thinking 会让模型先产出 thinking block,再给答案,适合困难任务但更慢更贵。
2.6 Ollama 本地模型
Ollama 可以在本机跑开源模型,适合离线开发、隐私场景和压测省钱。它提供 OpenAI 兼容端点,因此可以直接复用 openai.Provider。
local := openai.New(openai.Config{
Name: "ollama",
BaseURL: "http://localhost:11434/v1",
APIKey: "ollama", // 本地不校验 key,随便填
})
// 先执行:ollama pull qwen3
// ChatRequest.Model 填 "qwen3" 即可。Ollama 的价值不在于替代云端大模型,而在于给开发和兜底提供一个成本可控的环境。真实产品仍要根据任务复杂度、响应质量、延迟和合规要求选择模型。
2.7 流式输出
聊天窗口、终端工具和实时响应都需要流式。OpenAI 兼容接口在 stream=true 时返回 SSE,一行行 data: {...},以空行分隔事件,OpenAI 风格通常用 data: [DONE] 收尾。
解析流式响应的流程要分成两层:
- 第一层只负责读 SSE 线协议,按条拿到
data; - 第二层由各 Provider 提供事件解析器,OpenAI 风格平台共用一套,Claude 用自己的解析器。
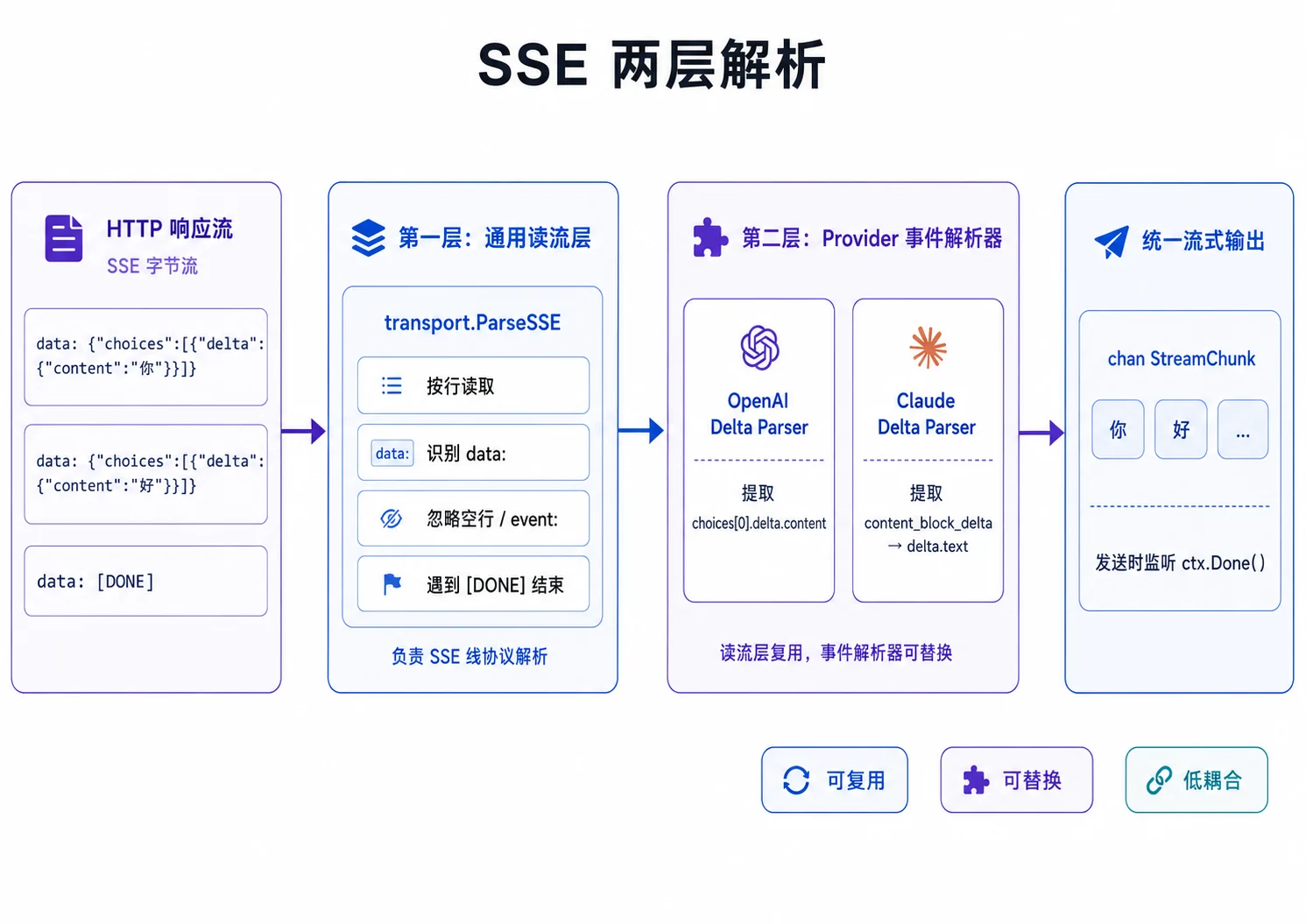
先看典型的 SSE 数据。
data: {"choices":[{"delta":{"content":"你"}}]}
data: {"choices":[{"delta":{"content":"好"}}]}
data: [DONE]第一层是读取数据,放在 internal/transport。
package transport
import (
"bufio"
"io"
"strings"
)
// ParseSSE 按空行聚合一个完整 SSE 事件,再把该事件的 data 交给 onData。
// 同一事件可以包含多行 data,规范要求使用换行符连接,不能逐行回调。
// onData 返回非 nil error 时提前终止;读到 EOF 时结束。
// [DONE]、message_stop 等协议结束标记由各 Provider 解析,通用层不擅自吞掉。
func ParseSSE(r io.Reader, onData func(data []byte) error) error {
scanner := bufio.NewScanner(r)
// 单条 SSE 数据可能很长,调大缓冲区上限。
scanner.Buffer(make([]byte, 0, 64*1024), 1024*1024)
var dataLines []string
dispatch := func() error {
if len(dataLines) == 0 {
return nil
}
data := strings.Join(dataLines, "\n")
dataLines = dataLines[:0]
return onData([]byte(data))
}
for scanner.Scan() {
line := strings.TrimSuffix(scanner.Text(), "\r")
if line == "" {
if err := dispatch(); err != nil {
return err
}
continue
}
if strings.HasPrefix(line, ":") {
continue // SSE 注释/心跳
}
field, value, found := strings.Cut(line, ":")
if !found {
field, value = line, ""
} else {
value = strings.TrimPrefix(value, " ")
}
if field == "data" {
dataLines = append(dataLines, value)
}
}
// SSE 规范规定:连接在空行前结束时,未完成的事件不派发。
return scanner.Err()
}这里有三个常见的坑。
- 第一,
bufio.Scanner默认 token 上限较小,SSE 中的 JSON 数据可能更长,需要调大缓冲区; - 第二,一个事件可以有多行
data:,要等空行出现后再聚合派发; - 第三,连接如果在事件分隔空行前结束,该事件是不完整事件,不应该交给上层解析。
第二层是 OpenAI 事件解析器。它只声明关心的字段,其余字段忽略。
func parseOpenAIDelta(data []byte) (delta string, done bool, err error) {
if string(data) == "[DONE]" {
return "", true, nil
}
var chunk struct {
Choices []struct {
Delta struct {
Content string `json:"content"`
} `json:"delta"`
} `json:"choices"`
}
if err := json.Unmarshal(data, &chunk); err != nil {
return "", false, fmt.Errorf("解析 OpenAI 流事件: %w", err)
}
if len(chunk.Choices) == 0 {
return "", false, nil // 可能是只携带 usage 的结束事件
}
return chunk.Choices[0].Delta.Content, false, nil
}把两层结合起来,OpenAI 的 ChatStream 就把增量塞进 channel。这里不要忘了 M01 1.2强调过的铁律:生产者执行 defer close(),并且发送时要监听 ctx.Done()。
func (p *Provider) ChatStream(ctx context.Context, req llm.ChatRequest) (<-chan llm.StreamChunk, error) {
if err := p.validateMessages(req.Messages); err != nil {
return nil, err
}
req.Stream = true
resp, err := p.doRequest(ctx, req) // 同 Chat 的发请求样板,略
if err != nil {
return nil, err
}
out := make(chan llm.StreamChunk)
go func() {
defer close(out)
defer resp.Body.Close()
sawDone := false
streamErr := transport.ParseSSE(resp.Body, func(data []byte) error {
delta, done, err := parseOpenAIDelta(data)
if err != nil {
return err
}
if done {
sawDone = true
return nil
}
if delta == "" {
return nil
}
select {
case <-ctx.Done():
return ctx.Err()
case out <- llm.StreamChunk{Content: delta}:
return nil
}
})
if streamErr == nil && !sawDone {
streamErr = fmt.Errorf("OpenAI 流在 [DONE] 前结束")
}
if streamErr != nil {
select {
case <-ctx.Done():
case out <- llm.StreamChunk{Err: streamErr}:
}
}
}()
return out, nil
}Claude 的 SSE 事件结构不同,文本增量藏在 content_block_delta 事件里。第一层 ParseSSE 可以复用,只需要换第二层解析器。
// parseClaudeDelta 只从文本增量块里抽出 delta.text;
// message_start / content_block_stop 等事件返回空串,message_stop 返回 done=true。
func parseClaudeDelta(data []byte) (delta string, done bool, err error) {
var ev struct {
Type string `json:"type"`
Delta struct {
Type string `json:"type"`
Text string `json:"text"`
} `json:"delta"`
}
if err := json.Unmarshal(data, &ev); err != nil {
return "", false, fmt.Errorf("解析 Claude 流事件: %w", err)
}
if ev.Type == "message_stop" {
return "", true, nil
}
if ev.Type == "content_block_delta" && ev.Delta.Type == "text_delta" {
return ev.Delta.Text, false, nil
}
return "", false, nil
}这样,Claude 的 ChatStream 骨架和 OpenAI 版本基本一致:请求体换成 adaptRequest,解析函数换成 parseClaudeDelta,并记录是否收到 message_stop。读流层共享,Provider 只负责解析自己的事件结构。两种实现都必须把 ParseSSE、事件 JSON 解析错误,以及未收到协议结束标记就 EOF 的情况通过 StreamChunk.Err 传给调用方,不能把异常断流伪装成正常结束。
2.8 JSON Schema 自动生成
在真实业务中的很多场景下(意图识别、任务规划、路由决策、工具调用参数),我们并不希望模型返回自然语言结果,而是希望拿到更稳定的结构化结果,通常是约定一个 JSON 格式的返回结构。手写 JSON Schema 冗长,也容易和 Go 结构体不同步。更好的做法是用反射从结构体自动生成。
package schema
type Schema struct {
Type string `json:"type,omitempty"`
Description string `json:"description,omitempty"`
Properties map[string]*Schema `json:"properties,omitempty"`
Items *Schema `json:"items,omitempty"`
Required []string `json:"required,omitempty"`
}
// Generate 为任意值的类型生成 JSON Schema。
// 实现是一段 reflect 递归:遍历字段、按 kind 映射、读取 json/desc 标签。
func Generate(v any) *Schema {
/* reflect 递归:string→"string",struct→"object" ... */
return nil
}用法是先定义参数结构体,再生成 Schema。
type GetWeatherArgs struct {
City string `json:"city" desc:"城市名"`
Days int `json:"days,omitempty" desc:"预报天数,默认 1"`
}
s := schema.Generate(GetWeatherArgs{}) // 交给模型的工具或结构化输出定义拿到 Schema 后有两种方式:
- 平台支持原生结构化输出时,优先用原生约束;
- 平台不支持时,用提示词约束加解析重试兜底。
M06 6.2 类型安全工具会把 Generate 接进工具注册流程。
2.9 Token 与成本计量
模型调用直接关系成本、延迟和上下文占用。Token 计量应该放在接入层统一处理,而不是让业务层各自估算。
package cost
type Pricing struct {
InputPer1M float64 // 每百万输入 token 单价
OutputPer1M float64 // 每百万输出 token 单价
}
type Usage struct {
InputTokens int
OutputTokens int
}
func (u Usage) Cost(p Pricing) float64 {
return float64(u.InputTokens)/1e6*p.InputPer1M +
float64(u.OutputTokens)/1e6*p.OutputPer1M
}
// Accumulator 并发安全地累计一轮会话的用量与成本。
type Accumulator struct {
mu sync.Mutex
Usage Usage
Cost float64
}
func (a *Accumulator) Add(u Usage, p Pricing) {
a.mu.Lock()
defer a.mu.Unlock()
a.Usage.InputTokens += u.InputTokens
a.Usage.OutputTokens += u.OutputTokens
a.Cost += u.Cost(p)
}真实计费应以 Provider 返回的 usage 为准。本地 token 估算只能作为提前预算和提示词裁剪的参考,因为不同模型的 tokenizer 并不完全一致。
上下文历史过长如何分配预算,见 M03 3.4 Token 预算;如何裁剪和压缩,见 M09 9.3 历史压缩。
2.10 多模型路由网关
前面介绍的各种能力最终会落到一个网关上:对上层只暴露一个 Chat,网关负责 Provider 组装、故障转移、按需分流和用量统计。
先用工厂函数按配置组装所有可用 Provider。Key 没配的 Provider 不启用,本地 Ollama 可以作为兜底。
func BuildAll(cfg Config) map[string]llm.Provider {
ps := map[string]llm.Provider{}
if cfg.DeepSeekKey != "" {
ps["deepseek"] = openai.NewDeepSeek(cfg.DeepSeekKey)
}
if cfg.ArkKey != "" {
ps["doubao"] = openai.NewDoubao(cfg.ArkKey)
}
if cfg.ClaudeKey != "" {
ps["claude"] = claude.New(cfg.ClaudeKey)
}
ps["ollama"] = openai.New(openai.Config{
Name: "ollama",
BaseURL: cfg.OllamaURL,
APIKey: "ollama",
})
return ps
}再用一个轻量网关把它们串起来。Strategy 决定尝试顺序,Chat 按顺序尝试,失败后降级,并把“谁回答的”返回给上层。
package router
type Strategy interface {
Order(providers []llm.Provider) []llm.Provider // 决定尝试顺序
}
type Priority struct{} // 最简策略:按注册顺序,主用第一个,挂了降级
func (Priority) Order(ps []llm.Provider) []llm.Provider { return ps }
type Router struct {
providers []llm.Provider
strategy Strategy
}
func New(strategy Strategy, providers ...llm.Provider) (*Router, error) {
if strategy == nil {
return nil, fmt.Errorf("router strategy 不能为空")
}
if len(providers) == 0 {
return nil, fmt.Errorf("至少需要一个 Provider")
}
for i, p := range providers {
if p == nil {
return nil, fmt.Errorf("providers[%d] 不能为空", i)
}
}
return &Router{
providers: append([]llm.Provider(nil), providers...),
strategy: strategy,
}, nil
}
func (r *Router) Chat(ctx context.Context, req llm.ChatRequest) (*llm.ChatResponse, string, error) {
var lastErr error
for _, p := range r.strategy.Order(r.providers) {
resp, err := p.Chat(ctx, req)
if err == nil {
return resp, p.Name(), nil // 第二个返回值告诉上层“谁回答的”
}
lastErr = err
if ctx.Err() != nil {
return nil, "", ctx.Err() // 用户取消,不再尝试
}
}
return nil, "", fmt.Errorf("所有 Provider 均失败: %w", lastErr)
}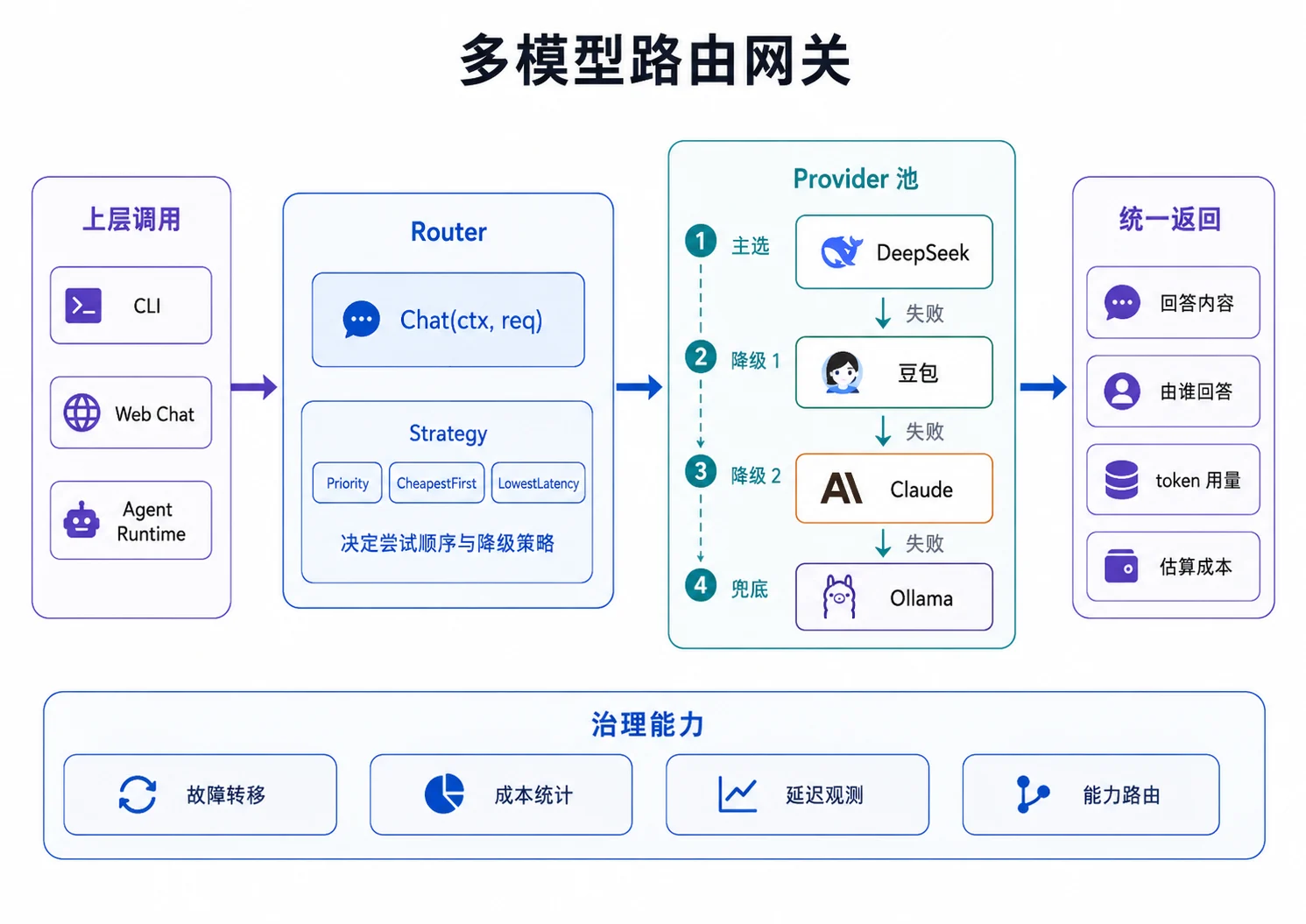
Priority 是最简单的故障转移策略。按成本优先、按延迟优先、按能力标签选择,都可以通过替换 Strategy 实现。路由网关的价值不是把多个模型摆在一起,而是把它们组织成可治理、可扩展、可降级的系统能力。
配套练习:llmrouter
按下面顺序完成:
- 实现最小可用的
openai.Provider,支持Chat与ChatStream; - 实现
claude.Provider,在内部完成协议适配,满足同一Provider接口; - 用兼容层接入豆包或 DeepSeek,只换 baseURL、key、model;
- 实现
BuildAll工厂和环境变量配置; - 完成支持故障转移的
Router,回答后打印“由谁回答、token、估算成本”。
选做:
- 实现
CheapestFirst和LowestLatency策略; - 统计 P50、P95 延迟;
- 给
parseOpenAIDelta写表驱动测试。
本章小结
| 主题 | 工程含义 |
|---|---|
| Provider 接口 | 上层只依赖能力,不碰协议细节 |
| OpenAI 兼容层 | 一套实现复用多个兼容平台 |
| Claude 适配器 | 把异构协议差异收在 Provider 内部 |
| SSE 两层解析 | 通用读流层复用,事件解析器按 Provider 替换 |
| JSON Schema | 用结构体生成工具和结构化输出定义 |
| Token 与成本 | 在接入层统一统计用量与估算成本 |
| 路由网关 | 把多个模型组织成可降级的系统能力 |
思考题
- 流式请求失败时,当前
Router还没有实现ChatStream的重试和降级。如果模型吐到一半断流,你会整段重来,还是从断点续?这两种方案分别会带来什么问题? - Prompt Caching 是前缀匹配。如果每次请求都在 system 最前面插一个变化的时间戳,缓存命中率会怎样?这对提示词顺序有什么启示?
- “路由 + 模型名”是耦合的:降级到 Claude 时需要使用 Claude 的模型名。你会如何设计,让上层只表达“给我一个便宜的中文模型”,而不关心具体供应商?
下一步
下一章进入 M03 Prompt 与上下文工程基础。M02 已经解决“如何把消息稳定发给模型并拿回结果”,下一章开始讨论“消息本身应该如何组织”,包括角色、提示词模板、上下文窗口、token 预算和 Prompt Caching。
参考资料
- OpenAI Chat Completions API
- Anthropic Messages API
- Google Gemini GenerateContent API
- Google Gemini Embeddings API
- DeepSeek API Docs
go build ./... 和 go test ./...。