M01 Go 语言 AI 开发基础
这一章是整套课程的工程基础。
后面的 LLM API 接入、工具调用、记忆系统、RAG、多智能体协作,虽然是在讲不同主题,但最终落到代码层面,都要求具备以下 Go 语言工程能力:
- 项目结构怎么组织
- HTTP 请求怎么发
- 流式输出怎么处理
- 取消信号怎么传播
- 接口怎么抽象
- 代码怎么测试
M01 的重点通过「AI 开发场景驱动」的方式讲解 Go 特性,每个知识点都对应后续模块的具体需求。 学完这一章之后,你应该能搭出一个结构清楚、接口明确、便于扩展和测试的 Go 项目骨架,为后续章节打好基础。
学习目标
完成这一章后,你将能够:
- 为一个 AI 应用组织出清晰、可扩展的 Go 工程结构;
- 用 goroutine + channel 正确建模 LLM 的流式输出;
- 用
context给每一次模型调用加上超时、取消,并贯穿传递 trace 信息; - 用
interface+ 泛型抽象出Provider,为「一套代码接所有模型」打底; - 写出一个生产级 HTTP 客户端(连接池、超时、429/5xx 重试、指数退避 + 抖动);
- 解析 LLM 返回的 SSE 流,并用
httptest对它做表驱动测试。
1.1 Go 语言开发 Agent
为什么使用 Go
AI Agent 开发不只是调用一次模型接口。模型负责生成和决策,程序还要负责接收请求、组织上下文、执行工具,以及处理超时、重试、限流、日志和测试。Go 在其中的主要作用,是把模型能力组织成一个稳定、可维护、可测试的工程系统。
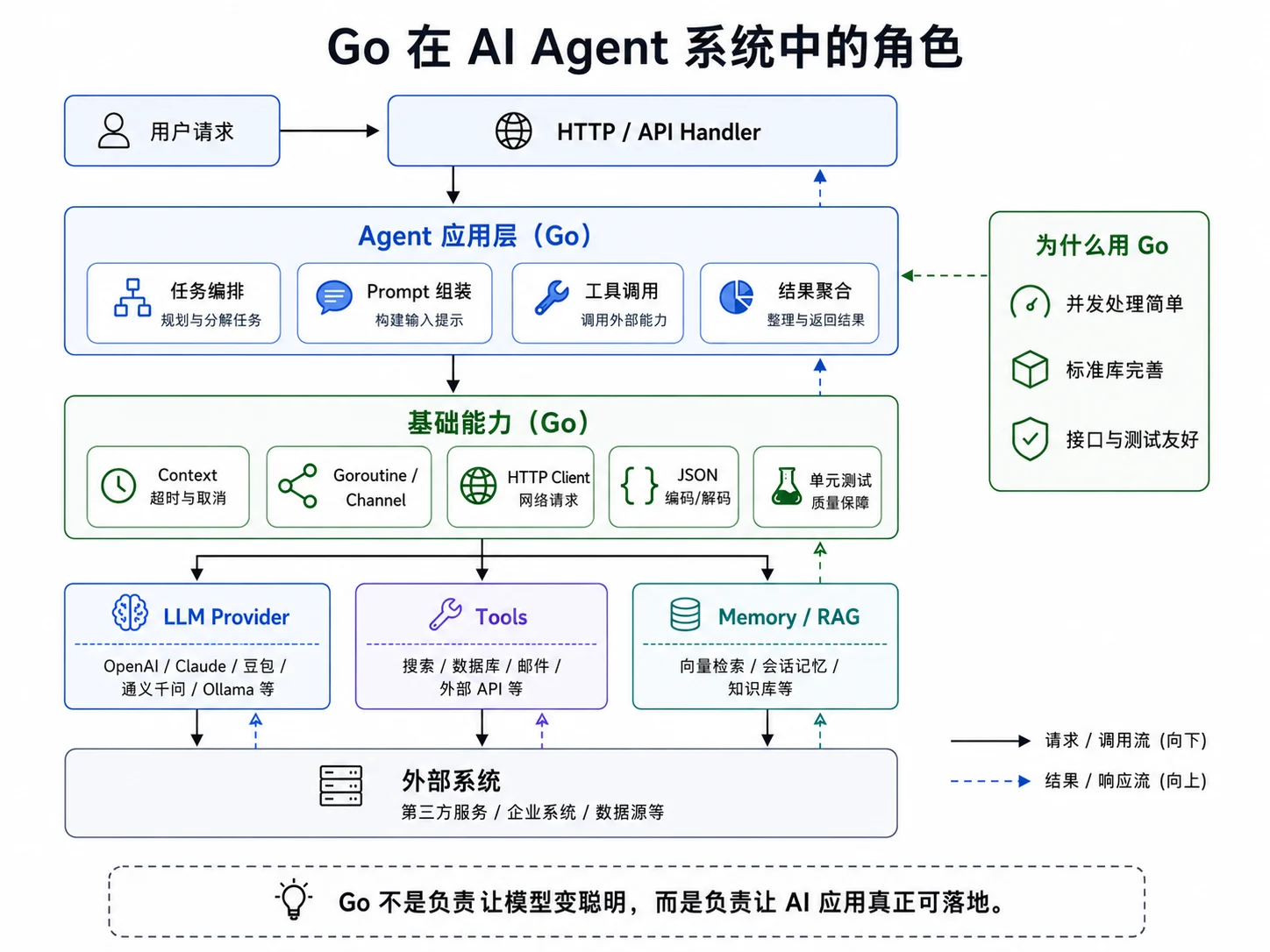
从工程视角看,Go 语言在这类项目里有几个明显优势:
- 并发处理简单,适合流式响应和多工具调用
- 标准库完整,HTTP、JSON、Context、测试都能直接用
- 接口和包管理清楚,适合把系统拆成稳定的层次
- 部署简单,适合作为服务端或命令行工具交付
调用大模型
在讨论并发、接口和工程封装之前,我们先手写一段代码直接调用一次模型,建立对整个过程的直观认识。
下面以 DeepSeek 的 OpenAI 兼容接口为例。
一次最简单的大模型调用只有四个关键部分:
| 部分 | 示例 | 作用 |
|---|---|---|
| URL | https://api.deepseek.com/chat/completions | 指定聊天补全端点 |
| 鉴权 | Authorization: Bearer $LLM_API_KEY | 证明调用方身份 |
| 请求体 | model、messages、stream | 指定模型、对话消息和响应方式 |
| 响应体 | choices、usage | 返回模型回答和 token 用量 |
先准备配置。
去 deepseek 官方平台 注册账号,充值 10 块钱,在 API keys 页面创建 API key 即可。
API Key 千万不要写进源码,也不要提交到 Git 仓库:
export LLM_API_KEY="替换成你的 API Key"具体使用的模型名称可能随平台升级而变化,实际使用时应以控制台和官方文档为准。这里把它放进环境变量,后续更换模型不需要修改代码。
HTTP 请求
OpenAI 兼容接口使用 HTTP POST 请求。完整请求可以先用 curl 观察:
curl "$LLM_BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLM_API_KEY" \
-H "Content-Type: application/json" \
-d "{
\"model\": \"$LLM_MODEL\",
\"messages\": [
{
\"role\": \"user\",
\"content\": \"用一句话解释什么是 AI Agent\"
}
],
\"stream\": false
}"请求体中的三个字段分别表示:
model:本次调用使用的模型;messages:对话历史,每条消息包含角色role和内容content;stream: false:等待模型生成完成后,一次性返回完整 JSON。
成功时会收到类似下面的响应。真实响应还可能包含其他字段,这里只展示本章需要处理的部分:
{
"model": "deepseek-v4-pro",
"choices": [
{
"message": {
"role": "assistant",
"content": "AI Agent 是能够基于目标自主决策、调用工具并执行多步任务的程序。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 15,
"completion_tokens": 28,
"total_tokens": 43
}
}模型回答位于 choices[0].message.content,token 用量位于 usage。后面的 Go 代码本质上只是完成四件事:构造这段 JSON、添加鉴权 Header、发送 HTTP 请求、解析响应 JSON。
用 Go 完成大模型调用
将下面的代码保存为 main.go 文件,代码中只使用了 Go 标准库:
package main
import (
"bytes"
"context"
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"os"
"strings"
"time"
)
const (
baseURL = "https://api.deepseek.com" // 模型厂商的 base URL
model = "deepseek-v4-pro" // 使用的模型名称
)
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
}
type ChatRequest struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream"`
}
type ChatResponse struct {
Choices []struct {
Message Message `json:"message"`
} `json:"choices"`
Usage struct {
PromptTokens int `json:"prompt_tokens"`
CompletionTokens int `json:"completion_tokens"`
TotalTokens int `json:"total_tokens"`
} `json:"usage"`
}
func main() {
apiKey := os.Getenv("LLM_API_KEY")
if apiKey == "" {
log.Fatal("请先设置 LLM_API_KEY")
}
question := "用一句话解释什么是 AI Agent"
if len(os.Args) > 1 {
question = strings.Join(os.Args[1:], " ")
}
payload := ChatRequest{
Model: model,
Messages: []Message{
{Role: "user", Content: question},
},
Stream: false,
}
body, err := json.Marshal(payload)
if err != nil {
log.Fatal(err)
}
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Minute)
defer cancel()
req, err := http.NewRequestWithContext(
ctx,
http.MethodPost,
baseURL+"/chat/completions",
bytes.NewReader(body),
)
if err != nil {
log.Fatal(err)
}
req.Header.Set("Authorization", "Bearer "+apiKey)
req.Header.Set("Content-Type", "application/json")
resp, err := http.DefaultClient.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
if resp.StatusCode < 200 || resp.StatusCode >= 300 {
raw, _ := io.ReadAll(io.LimitReader(resp.Body, 8<<10))
log.Fatalf("模型接口返回 %s: %s", resp.Status, raw)
}
var result ChatResponse
if err := json.NewDecoder(resp.Body).Decode(&result); err != nil {
log.Fatal(err)
}
if len(result.Choices) == 0 {
log.Fatal("模型响应中没有 choices")
}
fmt.Println(result.Choices[0].Message.Content)
fmt.Printf(
"token: input=%d output=%d total=%d\n",
result.Usage.PromptTokens,
result.Usage.CompletionTokens,
result.Usage.TotalTokens,
)
}运行程序:
go run main.go "为什么 Go 适合开发 AI Agent?"到这里,我们已经完成了一次真实模型调用,但这段代码还只是“能跑”:
main函数同时负责配置、请求、解析和输出,职责混在一起;- 直接使用
http.DefaultClient,没有统一的连接池、重试和限流策略; - 请求和响应类型绑定在单一协议上,还不能切换其他 Provider;
- 只能等待完整响应,暂时不能逐步打印模型生成内容;
- 代码依赖真实 API,不便于编写稳定的自动化测试。
本章后面的内容会围绕这段最小调用逐项重构。先拆出项目结构,再加入流式处理、Context、Provider 接口、生产级 HTTP 客户端、JSON 解析和测试。
最小工程结构
本章最终会完成一个命令行问答工具 minicall。我们先按以下目录结构完成项目初始化。
minicall/
├── cmd/
│ └── minicall/
│ └── main.go # 程序入口
├── internal/
│ ├── llm/
│ │ └── types.go # 请求、响应和 Provider 类型
│ └── transport/
│ └── client.go # HTTP 客户端、重试等基础设施
├── go.mod
└── Makefile这是一个比较通用的 Go 语言项目结构:
cmd/minicall放可执行程序入口。入口负责读取配置、接收命令行参数和组装依赖,不承载可复用的业务实现。internal放项目内部代码。Go 编译器会限制外部模块直接导入其中的包,适合存放llm类型和transport实现。
目录结构应随着功能增长而演进。后续真正实现 Agent、工具调用和记忆系统时,再按需要增加 internal/agent、internal/tools 和 internal/memory;当前没有必要先创建空目录,也不需要为了套用某种模板而引入 pkg。
初始化项目
mkdir minicall && cd minicall
go mod init github.com/yourname/minicall
mkdir -p cmd/minicall internal/llm internal/transport本章使用 Go 标准库直接完成 HTTP 请求、JSON 解析和测试,暂时不需要安装第三方模型 SDK。
github.com/yourname/minicall需要替换成你的实际仓库地址。
Makefile
可以编写 Makefile 把常用命令标准化。
.PHONY: run build test
QUESTION ?= 你好
run:
go run ./cmd/minicall "$(QUESTION)"
build:
mkdir -p bin
go build -o bin/minicall ./cmd/minicall
test:
go test -race ./...
完成课后练习后,可以通过 make run QUESTION="用 Go 写一个 HTTP 请求示例" 发起一次问答。随着项目增加新的入口或质量检查,再向 Makefile 补充对应目标。
1.2 Goroutine + Channel:处理流式输出
为什么流式处理需要 Goroutine?
无论是 OpenAI 风格的 SSE,还是其他 Provider 的事件流,调用方通常都不希望等模型全部生成完再一次性返回,而是希望边生成边消费。
同步方式:发请求 → 等待(3-8秒) → 收到完整回复 → 显示
流式方式:发请求 → 立刻收到第一个 token → 实时显示 → ... → 收到结束标记两种方式的用户体验差距巨大。这类场景非常适合用 Goroutine 和 Channel 处理。
- Goroutine 负责持续读取服务端返回;
- Channel 负责把 token 发送给调用方;
- Context 负责取消和超时控制。
但流式处理有个难点:我们要同时做两件事——接收 token(IO 密集)和处理 token(CPU/显示)。
先看最核心的思路:主流程发起请求之后,另起一个 Goroutine 持续读取流式响应,再通过 Channel 把结果逐步交给调用方。建议返回只读 Channel:
func StreamTokens(ctx context.Context, ...) <-chan Token {
tokens := make(chan Token, 64)
go func() {
defer close(tokens)
// 读取并发送 token
}()
return tokens
}返回 <-chan Token 可以明确告诉调用方:这个 Channel 只能读取,不能写入,也不能关闭。
调用方使用 for range 消费 Channel 时,如果 Channel 不关闭,循环就不会结束。
StreamChunk 结构设计
先定义流式数据块。
// StreamChunk 是流式输出的最小单元。
// 约定:Content 与 Err 互斥;Err != nil 时这是最后一个有意义的块。
type StreamChunk struct {
Content string // 本次增量文本
Err error // 出错时非空
}生产者
一个最小的「生产者」示例,把一段文字按字拆成流。
// fakeStream 模拟一个会逐字吐字的模型,用于教学/测试。
func fakeStream(ctx context.Context, text string) <-chan StreamChunk {
out := make(chan StreamChunk)
go func() {
defer close(out) // 关键:无论如何都要关 channel,否则消费者死等
for _, r := range text {
select {
case <-ctx.Done(): // 上游取消/超时,立刻收手并把原因带出去
out <- StreamChunk{Err: ctx.Err()}
return
case out <- StreamChunk{Content: string(r)}:
time.Sleep(30 * time.Millisecond) // 模拟生成耗时
}
}
}()
return out
}消费者
消费侧使用 for range 读取 channel。channel 被生产者关闭后,循环会自然结束:
func consume(ctx context.Context) error {
for chunk := range fakeStream(ctx, "你好,世界") {
if chunk.Err != nil {
return chunk.Err
}
print(chunk.Content) // 逐字打印
}
return nil
}这段代码里有几个重点:
- 生产者负责
close(channel),且用defer兜底。消费者用for range自动在关闭时退出。谁创建谁关闭、绝不在消费侧关闭。 - 发送也要走
select+ctx.Done()。如果只out <- chunk而消费者已经不读了,这个 goroutine 会永久阻塞泄漏。Agent 里这种泄漏极隐蔽且致命。 - 错误在同一个 channel 中返回,而不是另开一个 error channel。单通道 + 互斥字段,消费侧逻辑最简单。
1.3 Context:超时控制与请求取消
Context 解决什么问题?
Agent 系统往往是一条多层调用链:
HTTP Handler → Agent.Run → LLM.Complete → HTTP 请求模型服务如果用户关闭页面,或者请求超过了最大时间限制,后端应该尽快停止后续工作。否则不仅浪费资源,还可能继续消耗模型费用。
Context 的三种常用方式
超时控制
给整个操作设置最大时间限制,这是最常见的超时控制方式。
ctx, cancel := context.WithTimeout(context.Background(), 30*time.Second)
defer cancel() // 重要:即使超时前完成,也要释放资源手动取消
这是手动取消方式,常用于用户主动停止任务,或者上游判断需要停止。
ctx, cancel := context.WithCancel(parent)
// 某个条件触发后主动 cancel()
go func() {
<-userClosed
cancel()
}()Go 1.21+:带原因的取消,排查问题时能看到“为什么被取消”。
ctx, cancel := context.WithCancelCause(parent)
cancel(fmt.Errorf("用户取消了对话"))
// 下游:context.Cause(ctx) 取出真正原因select <-ctx.Done() 或把 ctx 传给会监听它的 IO(如 http.NewRequestWithContext),否则取消不会自动生效。传递请求级别的值
Agent 系统里 context 还承担请求级元数据透传的职责——典型的是 trace_id,用于把一次请求在多个 Agent / 工具调用间串起来。
WithValue 只适合传递请求级元数据,例如 request_id、trace_id,不应该用来传递业务参数。
type contextKey string
const requestIDKey contextKey = "request_id"
ctx = context.WithValue(ctx, requestIDKey, "req-123")
// 在任何地方取出
reqID := ctx.Value(requestIDKey).(string)正确传递 Context
下面是 ❌ 错误做法:每层调用都创建新的独立 context,这样用户取消外层 context 后,内层还在跑。
func (a *Agent) Run() (string, error) {
ctx, cancel := context.WithTimeout(context.Background(), 30*time.Second)
defer cancel()
return a.callLLM(ctx) // 传入了,但如果上层的 ctx 已取消,这个新 ctx 不受影响
}这样会断开和上游请求的取消关系。正确做法是从外部接收 Context,并基于它派生子 Context:
func (a *Agent) Run(ctx context.Context, goal string) (string, error) {
// 每次 LLM 调用单独设置超时,但基于父 ctx 派生
// 这样父 ctx 取消时,子 ctx 也会立刻取消
for step := 0; step < a.maxSteps; step++ {
// 检查父 ctx 是否已取消
if err := ctx.Err(); err != nil {
return "", fmt.Errorf("agent cancelled: %w", err)
}
// 派生子 ctx,单次 LLM 调用不超过 30 秒
llmCtx, llmCancel := context.WithTimeout(ctx, 30*time.Second)
resp, err := a.llm.Complete(llmCtx, req)
llmCancel() // ← 注意:不用 defer,在循环里 defer 会积累!
if err != nil {
return "", err
}
// ...
}
}检测取消的几种方式
方式一:直接检查
适合在循环开头进行检查。
if err := ctx.Err(); err != nil {
return err
}方式二:select
适合等待操作时同时监听取消。
select {
case result := <-resultChan:
return result, nil
case <-ctx.Done():
return nil, ctx.Err()
}方式三:传给支持 ctx 的函数
这也是最常见的方式,例如使用下面这种方式创建的 http 请求会自动在 ctx 取消时中止。
req, err := http.NewRequestWithContext(ctx, "POST", url, body)在 Go 工程实践约定:函数签名里的 ctx context.Context 永远放在第一个参数。
1.4 接口与泛型:抽象 Provider
为什么需要统一抽象?
AI Agent 项目通常不只接一个模型。OpenAI、Claude、DeepSeek、豆包等服务在协议、鉴权、返回结构和能力边界上都有差异,但上层 Agent 不应该感知这些差异。
// ❌ 不可维护:每增加一个 provider,Agent 层都要修改
func (a *Agent) callLLM(ctx context.Context, messages []Message) (string, error) {
switch a.providerType {
case "openai":
return a.openaiClient.Complete(ctx, messages)
case "claude":
return a.claudeClient.Complete(ctx, messages)
case "doubao":
return a.doubaoClient.Complete(ctx, messages)
// 每加一个 provider 就要改这里...
}
}先定义一个最小够用的 Provider 接口,各家模型各自实现。 我们希望 Agent 层只依赖一个统一接口:
// Provider 是所有大模型供应商的统一抽象。
// 接口刻意保持最小:先跑起来,能力随模块增长再扩展。
type Provider interface {
// Name 返回 Provider 标识符,用于日志和监控
Name() string
// Chat 发送请求并等待完整响应
Chat(ctx context.Context, req ChatRequest) (*ChatResponse, error)
// ChatStream 发送请求并通过 channel 返回流式 token
ChatStream(ctx context.Context, req ChatRequest) (<-chan StreamChunk, error)
}Go 谚语「The bigger the interface, the weaker the abstraction」。先有
Chat/ChatStream 两个方法就够开局;工具调用、多模态等能力,等真正用到的模块(M04 工具调用范式、M06 Function Calling 协议)再以新方法或新接口的形式加,避免一开始过度设计。统一请求与响应结构
type Role string
const (
RoleSystem Role = "system"
RoleUser Role = "user"
RoleAssistant Role = "assistant"
RoleTool Role = "tool"
)
type Message struct {
Role Role `json:"role"`
Content string `json:"content"`
}
type ChatRequest struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Temperature float64 `json:"temperature,omitempty"`
MaxTokens int `json:"max_tokens,omitempty"`
Stream bool `json:"stream,omitempty"`
}
type ChatResponse struct {
Content string
InputTokens int
OutputTokens int
}接口的价值在于,Agent 完全不需要知道背后到底是 OpenAI、Claude 还是豆包,后续切换模型、增加 Provider、做故障转移,都会更简单。
使用泛型
结构化输出解析
让模型返回 JSON,再解析进一个具体类型。
// ParseInto 把模型输出的 JSON 文本解析成目标类型 T。
// 用泛型避免每个调用点都写一遍 unmarshal + 类型断言。
func ParseInto[T any](raw string) (T, error) {
var v T
if err := json.Unmarshal([]byte(raw), &v); err != nil {
return v, fmt.Errorf("解析为 %T 失败: %w", v, err)
}
return v, nil
}
// 用法:
// type Weather struct{ City string; Temp float64 }
// w, err := ParseInto[Weather](modelOutput)指针辅助
大模型入参的大量可选字段需要 *int/*float64,泛型一个函数搞定:
// Ptr 返回任意值的指针,常用于构造带可选字段的请求体。
func Ptr[T any](v T) *T { return &v }
// 用法: req.Temperature = Ptr(0.7)使用泛型处理通用流
// Processor 是泛型流处理器,T 可以是任何类型
// 用法:stream.Process(ctx, tokenChan, func(tok Token) error { ... })
func Process[T any](
ctx context.Context,
ch <-chan T,
handler func(T) error,
) error {
for {
select {
case <-ctx.Done():
return ctx.Err()
case item, ok := <-ch:
if !ok {
return nil // channel 关闭,正常结束
}
if err := handler(item); err != nil {
return err
}
}
}
}
// Collect 将 channel 中的所有值收集到 slice
func Collect[T any](ctx context.Context, ch <-chan T) ([]T, error) {
var result []T
err := Process(ctx, ch, func(item T) error {
result = append(result, item)
return nil
})
return result, err
}这类泛型工具函数适合放在 pkg/stream 这类通用包里。它与具体 LLM 无关,可以在后续模块中反复复用。
1.5 生产级 HTTP 客户端
调用模型 API 时,不建议直接使用 http.DefaultClient。
resp, err := http.Get("https://api.openai.com/v1/...")http.DefaultClient 默认没有完整的超时、重试和限流策略。对 LLM API 这种外部依赖来说,这很容易造成请求挂起、连接复用差、错误处理不统一等问题。
HTTP 客户端配置
把拨号、TLS 握手、空闲连接数这些作为 Transport 配置项,每一次模型请求的整体生命周期交给 context 控制。
// HTTPConfig 收拢 HTTP 客户端的可调项。
type HTTPConfig struct {
DialTimeout time.Duration // 建连超时
KeepAlive time.Duration
MaxIdleConns int
MaxIdleConnsPerHost int // 默认只有 2,调模型时远远不够
IdleConnTimeout time.Duration
TLSHandshakeTimeout time.Duration
}一个适合 LLM API 的默认配置大致如下:
// DefaultHTTPConfig 是一组适合调 LLM API 的稳妥默认值。
func DefaultHTTPConfig() HTTPConfig {
return HTTPConfig{
DialTimeout: 5 * time.Second,
KeepAlive: 30 * time.Second,
MaxIdleConns: 100,
MaxIdleConnsPerHost: 20,
IdleConnTimeout: 90 * time.Second,
TLSHandshakeTimeout: 5 * time.Second,
}
}定义 HTTPOption 选项,支持修改默认配置。
// HTTPOption 覆盖默认配置。
type HTTPOption func(*HTTPConfig)
func WithDialTimeout(d time.Duration) HTTPOption { return func(c *HTTPConfig) { c.DialTimeout = d } }
func WithMaxIdleConnsPerHost(n int) HTTPOption { return func(c *HTTPConfig) { c.MaxIdleConnsPerHost = n } }
// 其余字段按同一模式按需添加 WithXxx。
// newTransport 把配置组装成 *http.Transport —— 与 client 构造分离,单一职责。
func newTransport(c HTTPConfig) *http.Transport {
return &http.Transport{
DialContext: (&net.Dialer{
Timeout: c.DialTimeout,
KeepAlive: c.KeepAlive,
}).DialContext,
MaxIdleConns: c.MaxIdleConns,
MaxIdleConnsPerHost: c.MaxIdleConnsPerHost,
IdleConnTimeout: c.IdleConnTimeout,
TLSHandshakeTimeout: c.TLSHandshakeTimeout,
ExpectContinueTimeout: 1 * time.Second,
}
}HTTP 客户端与连接池
配好 http.Client 与 Transport
// NewHTTPClient 返回一个适合调 LLM API 的客户端;不传参用默认值,也可用 Option 覆盖。
func NewHTTPClient(opts ...HTTPOption) *http.Client {
cfg := DefaultHTTPConfig()
for _, opt := range opts {
opt(&cfg)
}
// 注意:不设 client.Timeout —— 流式(SSE)是长连接,整体超时会把它掐断;
// 超时交给 context 逐次控制,这里只兜底拨号/握手等阶段。
return &http.Client{Transport: newTransport(cfg)}
}NewHTTPClient() 默认使用 DefaultHTTPConfig 配置,开箱可用。它是底层的 *http.Client 构件,下一步会在它之上再包一层带重试和限流的 transport.Client。
如果某个高并发 Provider 需要更大的连接池,可以写成 NewHTTPClient(WithMaxIdleConnsPerHost(50))。
http.Client.Timeout。流式 SSE 是长连接,整体超时可能把正常响应直接掐断。模型调用的生命周期应由每次请求传入的 context 控制,Transport 只负责拨号、握手、连接池等底层阶段。http.Transport 应该在程序生命周期内复用,不要每次请求都创建新的 http.Client。否则连接池无法复用,每次请求都要重新建立 TCP / TLS 连接。
Client 封装
一个企业级的 Client 应该支持重试逻辑和限流策略。
重试
业务高峰期大模型 API 经常返回 429 Too Many Requests 或 5xx,必须自动重试,否则用户体验极差。
常见可重试场景包括:
429 Too Many Requests500 Internal Server Error502 Bad Gateway503 Service Unavailable504 Gateway Timeout
type RetryConfig struct {
MaxRetries int // 最多重试次数(不含首次)
BaseDelay time.Duration // 退避基数,如 500ms
MaxDelay time.Duration // 退避上限,如 10s
}
func DefaultRetryConfig() RetryConfig {
return RetryConfig{
MaxRetries: 3,
BaseDelay: 500 * time.Millisecond,
MaxDelay: 10 * time.Second,
}
}限流
为了兼容更多限流实现模式,这里抽象出一个限流器接口。暂时使用 golang.org/x/time/rate.Limiter ,支持后续无缝切换。
// Limiter 抽象限流器。标准库没有内置限流,生产中通常用 golang.org/x/time/rate.Limiter
// (它的 Wait(ctx) error 正好满足这个接口)。接口定义在使用方,transport 无需 import rate。
type Limiter interface {
Wait(ctx context.Context) error
}定义企业级 Client 结构体。
// Client 把"连接池 + 重试退避 + 可选限流"封装成一个可复用的客户端。
// Do 是唯一出站入口:重试与限流统一在这里执行,调用方无法绕过。
type Client struct {
http *http.Client
retry RetryConfig
limiter Limiter // 可空:nil 表示不限流
}
type Option func(*Client)
func WithRetry(cfg RetryConfig) Option { return func(c *Client) { c.retry = cfg } }
func WithLimiter(l Limiter) Option { return func(c *Client) { c.limiter = l } } // 如 rate.NewLimiter(10, 1)
func WithHTTPOptions(opts ...HTTPOption) Option {
return func(c *Client) { c.http = NewHTTPClient(opts...) }
}
// NewClient 返回生产级 LLM HTTP 客户端;零参开箱即用,后面各章都用它。
func NewClient(opts ...Option) *Client {
c := &Client{http: NewHTTPClient(), retry: DefaultRetryConfig()}
for _, opt := range opts {
opt(c)
}
return c
}实际执行请求的 Do 方法。
// Do 执行请求并按需重试 429/5xx(指数退避 + 抖动,优先尊重 Retry-After)。
// 签名刻意对齐标准库 http.Client.Do:ctx 通过 http.NewRequestWithContext 装进请求里。
func (c *Client) Do(req *http.Request) (*http.Response, error) {
ctx := req.Context()
if c.limiter != nil {
if err := c.limiter.Wait(ctx); err != nil { // 限流:等到有令牌,或被 ctx 取消
return nil, err
}
}
var lastErr error
for attempt := 0; attempt <= c.retry.MaxRetries; attempt++ {
// 重试前重建一次性的 Body —— 否则 POST 重试会发空体。
// http.NewRequest 对 bytes/strings reader 会自动设好 GetBody,这里直接用。
if req.Body != nil && req.GetBody != nil {
body, err := req.GetBody()
if err != nil {
return nil, err
}
req.Body = body
}
resp, err := c.http.Do(req)
var wait time.Duration
switch {
case err != nil:
lastErr = err // 网络层错误,可重试
wait = backoff(attempt, c.retry)
case resp.StatusCode == http.StatusTooManyRequests || resp.StatusCode >= 500:
wait = retryAfter(resp) // 优先尊重服务端的 Retry-After
if wait <= 0 {
wait = backoff(attempt, c.retry)
}
resp.Body.Close()
lastErr = fmt.Errorf("服务端返回 %d", resp.StatusCode)
default:
return resp, nil // 2xx/4xx(非429) 直接返回,交给上层处理
}
if attempt == c.retry.MaxRetries { // 最后一次仍失败:不再等待,直接退出
break
}
if !sleep(ctx, wait) {
return nil, ctx.Err()
}
}
return nil, fmt.Errorf("重试 %d 次后仍失败: %w", c.retry.MaxRetries, lastErr)
}
// backoff 计算第 attempt 次重试的等待时长:指数增长 + 抖动,且不超过 MaxDelay。
func backoff(attempt int, cfg RetryConfig) time.Duration {
d := cfg.BaseDelay << attempt // 0.5s, 1s, 2s, 4s...
if d > cfg.MaxDelay {
d = cfg.MaxDelay
}
// 加抖动,让结果落在约 0.9~1.1 倍之间(±10%),避免大量客户端同时重试造成“惊群”
jitter := time.Duration(rand.Int63n(int64(d) / 5))
return d - (d / 10) + jitter
}
// retryAfter 解析 429/503 响应里的 Retry-After 头:支持「秒数」与「HTTP-date」两种形式。
func retryAfter(resp *http.Response) time.Duration {
v := resp.Header.Get("Retry-After")
if v == "" {
return 0
}
if sec, err := strconv.Atoi(v); err == nil { // 形式一:延迟秒数,如 "3"
return time.Duration(sec) * time.Second
}
if t, err := http.ParseTime(v); err == nil { // 形式二:HTTP-date
if d := time.Until(t); d > 0 {
return d
}
}
return 0
}
// sleep 在等待 d 的同时监听 ctx;被取消则返回 false。
func sleep(ctx context.Context, d time.Duration) bool {
t := time.NewTimer(d)
defer t.Stop()
select {
case <-ctx.Done():
return false
case <-t.C:
return true
}
}调用方只需要用 http.NewRequestWithContext 构造请求,然后执行:
resp, err := transport.NewClient().Do(req)上述代码的注意事项:
- 用
req.GetBody重建 Body:Request.Body读一次就空了,POST 重试若不重建,发出去的是空体(新手最容易翻车的地方)。标准库给bytes.Reader/strings.Reader这类 body 自动设好了GetBody,Do里取它重建即可——既修了坑,又不必把"工厂函数"暴露给调用方。 - 退避要带抖动(jitter):否则限流恢复时所有客户端同一刻冲上去,再次把服务打垮(惊群效应)。
- 优先尊重
Retry-After:服务端明确告诉你等多久时,照做最礼貌也最高效。 - 退避等待必须可被
ctx打断:用户取消时不能还傻等 4 秒。 - 流式请求不要在
http.Client上设Timeout:那会把长连接整体掐断;超时通过context控制。
进阶封装
把重试/限流做成 http.RoundTripper。上面的 Client.Do 内部显式写了重试代码——好处是直观,代价是调用方都需要使用 client.Do 而不是直接使用 http.Client。还有一种更"隐形"的做法:把重试/限流写成一层 http.RoundTripper,包在底层 transport 外,对外暴露的仍是个普通 *http.Client。这样第三方 SDK 拿到这个 client 也会自动获得了重试/限流,使用方完全无感——这是横切关注点(cross-cutting concern)最地道的封装。
// retryTransport 是一层中间件式的 RoundTripper:先限流,再带重试地委托给底层 base。
type retryTransport struct {
base http.RoundTripper
retry RetryConfig
limiter Limiter // 可空
}
func (t *retryTransport) RoundTrip(req *http.Request) (*http.Response, error) {
ctx := req.Context()
if req.Body != nil {
defer req.Body.Close() // RoundTripper 负责关闭传入 Body;重试用 GetBody 取独立副本
}
if t.limiter != nil {
if err := t.limiter.Wait(ctx); err != nil {
return nil, err
}
}
var lastErr error
for attempt := 0; attempt <= t.retry.MaxRetries; attempt++ {
// RoundTripper 契约:不应改动传入的 req(它可能被并发读)。
// 每次重试都 Clone 一份、用 GetBody 重建一次性的 Body。
r := req
if req.Body != nil && req.GetBody != nil {
body, err := req.GetBody()
if err != nil {
return nil, err
}
r = req.Clone(ctx)
r.Body = body
}
resp, err := t.base.RoundTrip(r) // 委托给真正发请求的底层 transport
var wait time.Duration
switch {
case err != nil:
lastErr, wait = err, backoff(attempt, t.retry)
case resp.StatusCode == http.StatusTooManyRequests || resp.StatusCode >= 500:
if wait = retryAfter(resp); wait <= 0 {
wait = backoff(attempt, t.retry)
}
resp.Body.Close()
lastErr = fmt.Errorf("服务端返回 %d", resp.StatusCode)
default:
return resp, nil
}
if attempt == t.retry.MaxRetries {
break
}
if !sleep(ctx, wait) {
return nil, ctx.Err()
}
}
return nil, fmt.Errorf("重试 %d 次后仍失败: %w", t.retry.MaxRetries, lastErr)
}
// NewRetryHTTPClient 返回一个“自带重试/限流”的普通 *http.Client,调用方照常用即可。
func NewRetryHTTPClient(retry RetryConfig, limiter Limiter, opts ...HTTPOption) *http.Client {
cfg := DefaultHTTPConfig()
for _, opt := range opts {
opt(&cfg)
}
return &http.Client{
Transport: &retryTransport{
base: newTransport(cfg),
retry: retry,
limiter: limiter,
},
}
}1.6 JSON 进阶:处理复杂 API 响应
LLM 接口看起来是在返回 JSON,但和普通业务接口相比,它的响应结构通常更复杂一些。
常见情况包括:
- 某些字段可能不存在,或者值是
null - 同一个字段在不同场景下可能是不同类型
- 流式响应并不是一个完整 JSON,而是一段段事件流
延迟解析
使用 json.RawMessage——延迟解析。
例如大模型返回的工具调用参数、各厂商会有不同的扩展字段,先保存原始字节,等知道类型了再解析:
type toolCall struct {
Name string `json:"name"`
Args json.RawMessage `json:"arguments"` // 先不解析,按工具类型再 ParseInto
}json.Decoder + DisallowUnknownFields —— 在测试和严格场景下,发现模型/接口返回了预期外的字段时直接报错,避免静默吞掉数据。生产解析则通常不要开启它,以兼容各厂商的差异。
处理联合类型字段
在 Go 语言中可以使用自定义 UnmarshalJSON 方法应对"同一字段可能是多种结构"的业务场景。
最典型的就是多模态消息:OpenAI 的 content 字段,纯文本对话时是个字符串,带图片/音频时却是个分块数组。json 标准库默认只认一种类型,碰到另一种类型就报错。这时就需要给指定类型实现 UnmarshalJSON 方法,先试着解析成字符串、再试着解析成数组:
// ContentPart 是多模态消息的一个分块(文本或图片)——“联合类型”的典型场景:
// 同一个字段在不同情况下是不同结构。
type ContentPart struct {
Type string `json:"type"` // "text" | "image_url"
Text string `json:"text,omitempty"` // type=="text" 时有值
ImageURL *ImageURL `json:"image_url,omitempty"` // type=="image_url" 时有值
}
type ImageURL struct {
URL string `json:"url"`
}
// MessageContent 兼容 content 字段的两种形态:纯文本字符串 或 多模态分块数组。
type MessageContent struct {
Text string // 纯文本形态
Parts []ContentPart // 多模态形态(图片、音频…)
}
func (m *MessageContent) UnmarshalJSON(data []byte) error {
// 先试最常见的纯字符串
var s string
if err := json.Unmarshal(data, &s); err == nil {
m.Text = s
return nil
}
// 再试分块数组
var parts []ContentPart
if err := json.Unmarshal(data, &parts); err == nil {
m.Parts = parts
return nil
}
return fmt.Errorf("content 既不是 string 也不是数组: %s", data)
}
// 出站方向对称处理:有分块就发数组,否则发纯字符串——与上面的解析一一对应,能无缝往返。
func (m MessageContent) MarshalJSON() ([]byte, error) {
if len(m.Parts) > 0 {
return json.Marshal(m.Parts)
}
return json.Marshal(m.Text)
}这种写法非常适合处理“字段可能是多种结构”的 API 响应。
安全序列化
// SafeJSON 安全地序列化对象,失败时返回错误字符串而非 panic
func SafeJSON(v any) string {
data, err := json.Marshal(v)
if err != nil {
return fmt.Sprintf(`{"error": "marshal failed: %v"}`, err)
}
return string(data)
}1.7 测试
AI 组件和普通业务代码相比,测试难点更明显:
- LLM 调用依赖外部 API Key
- 真实响应有随机性
- 工具调用可能带副作用
所以,比较稳妥的思路是:把外部依赖抽象成接口,再通过 Mock 和 httptest 做替换。
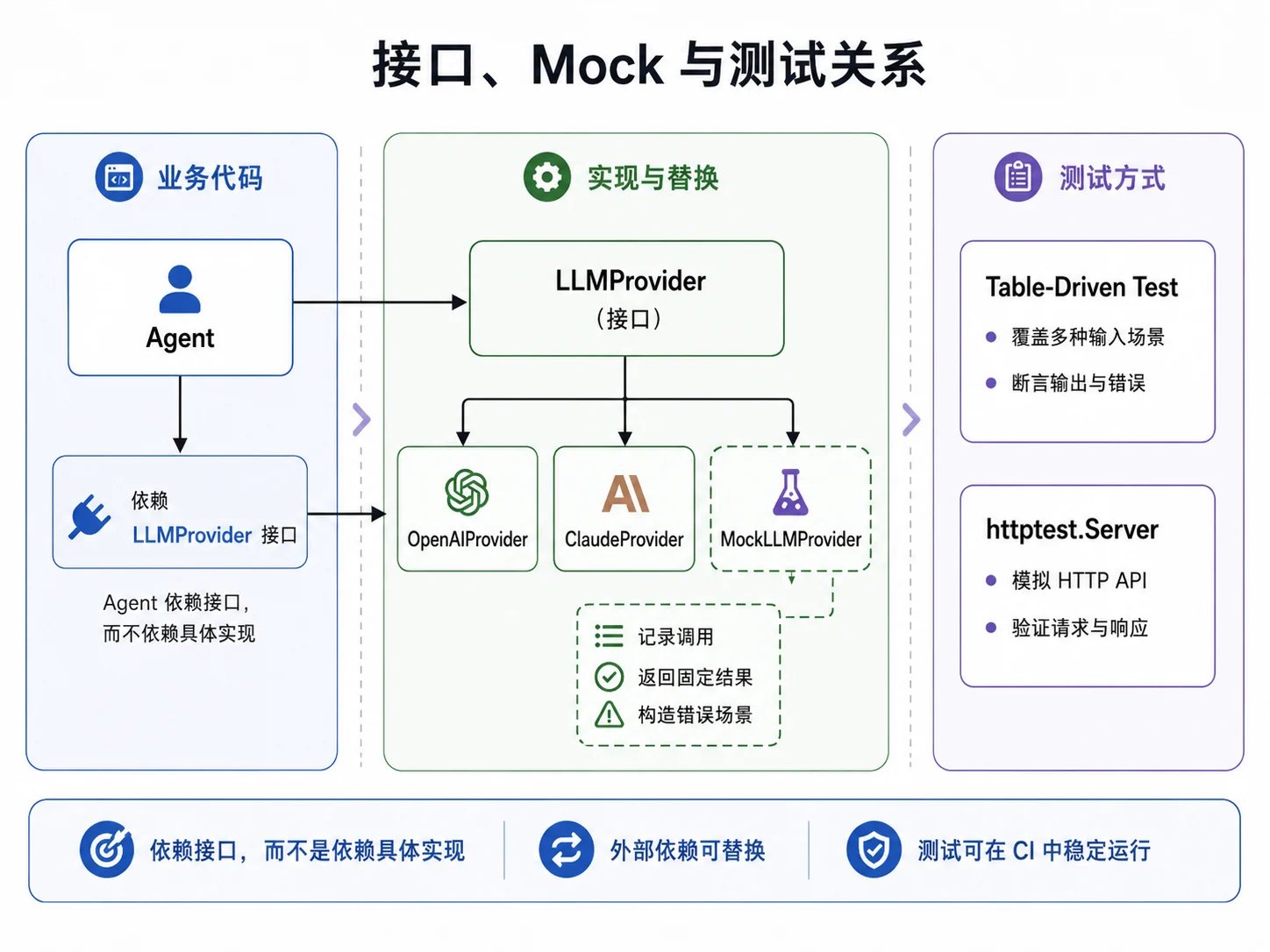
调模型的代码不能依赖真实 API 跑测试:慢、花钱、不稳定、CI 里没 Key。Mock 的作用是让测试可以稳定控制模型返回:
- 固定返回某段文本;
- 按顺序返回多轮响应;
- 模拟错误;
- 记录调用次数;
- 配合 Agent 测试多轮执行。
逻辑测试
先用表驱动测一段纯逻辑——退避里 Retry-After 头的解析(1.5):
package transport
import (
"net/http"
"testing"
"time"
)
func TestRetryAfter(t *testing.T) {
tests := []struct {
name string
val string // Retry-After 头的值(空表示不设该头)
want time.Duration
}{
{"无头", "", 0},
{"正常秒数", "3", 3 * time.Second},
{"非法值", "soon", 0},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
resp := &http.Response{Header: http.Header{}}
if tt.val != "" {
resp.Header.Set("Retry-After", tt.val)
}
if got := retryAfter(resp); got != tt.want {
t.Errorf("got %v want %v", got, tt.want)
}
})
}
}mock 测试
再用 httptest mock 一个先返回 429 错误,再返回成功的模型服务,验证 Client.Do 真的会重试、并最终拿到 200:
package transport
import (
"context"
"net/http"
"net/http/httptest"
"strings"
"sync/atomic"
"testing"
"time"
)
func TestClientDo(t *testing.T) {
var hits int32
srv := httptest.NewServer(http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if atomic.AddInt32(&hits, 1) == 1 {
w.WriteHeader(http.StatusTooManyRequests) // 第 1 次:429,应触发重试
return
}
w.WriteHeader(http.StatusOK) // 第 2 次:成功(GetBody 已把 POST body 重发一遍)
_, _ = w.Write([]byte(`{"ok":true}`))
}))
defer srv.Close()
cfg := DefaultRetryConfig()
cfg.BaseDelay = time.Millisecond // 测试里别真等几百毫秒
// ctx 装进请求;strings.Reader 让 http 自动设好 GetBody,重试时 Client 据此重建 Body
req, err := http.NewRequestWithContext(context.Background(), http.MethodPost, srv.URL, strings.NewReader(`{}`))
if err != nil {
t.Fatal(err)
}
resp, err := NewClient(WithRetry(cfg)).Do(req)
if err != nil {
t.Fatal(err)
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
t.Fatalf("期望最终 200,得到 %d", resp.StatusCode)
}
if hits != 2 {
t.Fatalf("期望命中 2 次(429 后重试一次),实际 %d", hits)
}
}httptest 做依赖替换,测试会简单很多。配套练习:minicall 命令行问答工具
把本模块的组件拼起来,做一个能用的 CLI:发一次问题、拿回完整回答 + token 用量。
需求:
- 读取环境变量
LLM_BASE_URL、LLM_API_KEY、LLM_MODEL; - 从命令行参数拿到用户问题;非流式调用
/chat/completions; - 打印模型回答与本次
input/output token用量; - 支持
Ctrl+C立即中断。
要求覆盖本模块的全部要点:
- 用 1.4 的
llm.ChatRequest/ChatResponse、Message组织请求与结果; - 用 1.5 的
transport.NewClient().Do(req)发请求(自动处理 429/5xx 重试);请求用http.NewRequestWithContext构造; - 用
signal.NotifyContext把Ctrl+C接成context取消,并贯穿传递; - 用 1.6 的 JSON 技巧解析响应(
choices[0].message.content与usage); - 给
retryAfter(或你的响应解析函数)写表驱动测试。
入口骨架(cmd/minicall/main.go,留空待你补全):
package main
import (
"context"
"fmt"
"os"
"os/signal"
"strings"
"syscall"
)
func main() {
// Ctrl+C → context 取消
ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
defer stop()
question := strings.Join(os.Args[1:], " ")
if question == "" {
fmt.Println("用法: minicall <你的问题>")
os.Exit(1)
}
cfg := loadConfigFromEnv() // TODO: 读取 BASE_URL / API_KEY / MODEL
if err := runOnce(ctx, cfg, question); err != nil {
fmt.Fprintln(os.Stderr, "\n出错:", err)
os.Exit(1)
}
}
// runOnce: 构造请求 → transport.NewClient().Do(req) → 解析 choices[0].message.content 与 usage → 打印。
// TODO: 由你实现,这是本模块的综合验收。
func runOnce(ctx context.Context, cfg Config, question string) error {
panic("TODO")
}小结
这一章的主线可以概括为下面几点:
- Agent 项目工程分层(
internal/cmd,依赖单向)。 - Go 语言并发模式、Context 传播、接口抽象和测试方式,都会贯穿后续所有章节。
- 合理定义可扩展的
Provider接口及泛型的应用场景。 - 如何定义生产级 HTTP 客户端 + 重试退避。
- SSE 解析 + httptest 测试。
完成这一章后,你应该已经有能力搭出一个最小可用的 Go Agent 项目骨架。
参考资料
context官方文档- Go Blog: Concurrency Patterns
- 《The Go Programming Language》第 8 章
golangci-lint